Analyzing the iPhone 5 Geekbench Results
by Anand Lal Shimpi on September 16, 2012 8:31 PM EST- Posted in
- Smartphones
- Apple
- Mobile
- SoCs
- iPhone 5
While working on our Haswell piece, I've been religiously checking the Geekbench and GLBenchmark results browsers to see if anyone ran either benchmark and decided to tap upload. This usually happens before every major smartphone launch, but in the case of the iPhone 5 the details these applications can give us are even more important.
Yesterday we confirmed that Apple is using its own custom designed ARM based CPU cores in its A6 SoC. Apple opted not to design in a vanilla ARM Cortex A9 likely to avoid relying on pure voltage/frequency scaling to improve performance, and chose not to integrate a Cortex A15 likely because of power consumption concerns as well.
There's absolutely no chance of Apple sending us a nice block diagram of the A6 CPU cores, so we have to work with what clues we can get elsewhere. Geekbench is particularly useful because it reports clock speed. Why does clock speed matter? Because, if reported accurately, it can tell us a lot about how the A6's CPU design has improved from an IPC standpoint. Remember that clock speed doesn't matter, but rather the combination of clock frequency and instructions executed per clock that define single threaded performance.
| Apple iPhone 5 Models | ||||||
| iPhone 5 Model | GSM/EDGE Bands | WCDMA Bands | CDMA 1x/EVDO Rev.A/B Bands | LTE Bands (FCC+Apple) | ||
| A1428 "GSM" | 850/900/1800/1900 MHz | 850/900/1900/2100 MHz | N/A | 2/4/5/17 | ||
| A1429 "CDMA" | 850/900/1800/1900 MHz | 850/900/1900/2100 MHz | 800/1900/2100 MHz | 1/3/5/13/25 | ||
| A1429 "GSM" | 850/900/1800/1900 MHz | 850/900/1900/2100 MHz | NA | 1/3/5 (13/25 unused) | ||
A short while ago, Geekbench results for a device identifying itself as an iPhone5,2 appeared. Brian believes this is likely the A1429 Verizon device (A1428 being iPhone 5,1) - perhaps one presampled to a reviewer looking to test their luck.
MacRumors appears to be first on the scene, having been tipped by an employee at PrimateLabs (the creators of Geekbench). I need to preface the rest of this post with a giant caution sign: I have no inside knowledge of whether or not these results are legitimate. They seem believable, but anything can happen. The rest of this post is simply my initial thoughts on what these mean, should the results be accurate. Update: The first iPhone 5 reviews are out and this Geekbench data looks accurate.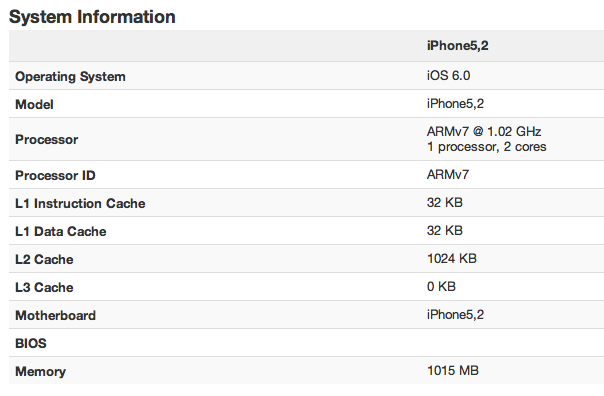
Cache sizes haven't changed, which either tells us Apple isn't feeling as generous with die size as perhaps it once was or that working sets in iOS are still small enough to fit inside of a 1MB L2. I suspect it's mostly the latter, although all microprocessor design is a constantly evaluated series of tradeoffs (often made through giant, awesomely protected spreadsheets).
The first real change is clock speed. Apple clocked its A4 and A5 CPU core(s) at 800MHz, although these Geekbench results point to a 25% increase in frequency at 1GHz. Some of the headroom is likely enabled by the move to 32nm, although it's very possible that Apple also went with a slightly deeper pipeline to gain frequency headroom. The latter makes sense. We've seen conservative/manageable increases in pipeline depth to hit frequency targets and improve performance before.
The fairly low clock speed also points to an increase in IPC (instructions executed per clock) over the Cortex A9 design. As I mentioned in our A6 analysis post, simple voltage/frequency scaling is a very power inefficient way to scale performance. A combination of IPC and frequency increases are necessary. If these results are accurate and the CPU cores are only running at 1GHz, it does lend credibility to the idea of a tangibly wider design.
It's also unclear if Apple is doing any sort of dynamic thermal allocation here, ala Intel's Turbo Boost. You can't get more power constrained than in a smartphone, and power gating is already common within ARM based SoCs, so that 1GHz value could be under load for both cores. A single core could run at higher frequencies for short bursts.
The next thing that stood out to me was the memory data:
| Geekbench Comparison | |||||
| Memory Performance | iPhone 4S | iPhone 5 (unconfirmed) | Scaling | ||
| Read Sequential ST | 0.32 GB/s | 1.78 GB/s | 5.63x | ||
| Write Sequential ST | 0.86 GB/s | 1.35 GB/s | 1.57x | ||
| Stdlib Allocate ST | 1.44 Mallocs/s | 1.92 Mallocs/s | 1.33x | ||
| Stdlib Write | 2.7 GB/s | 6.06 GB/s | 2.24x | ||
| Stdlib Copy | 0.55 GB/s | 2.26 GB/s | 4.13x | ||
| Geekbench Comparison | |||||
| Stream Performance | iPhone 4S | iPhone 5 (unconfirmed) | Scaling | ||
| Stream Copy | 0.42 GB/s | 1.9 GB/s | 4.55x | ||
| Stream Scale | 319 MB/s | 994 MB/s | 3.11x | ||
| Stream Add | 0.59 GB/s | 1.39 GB/s | 2.34x | ||
| Stream Triad | 377 MB/s | 1019 MB/s | 2.70x | ||
It's well known that ARM's Cortex A9 doesn't have the world's best interface outside of the compute core and its memory performance suffered as a result. If this data is accurate, it points to significantly overhauled cache and memory interfaces. Perhaps an additional load port, deeper buffers, etc...
Also pay close attention to peak bandwidth utilization. The 4S had 6.4GB/s of theoretical bandwidth out to main memory, the 5 raises that to 8.5GB/s. In the Stdlib write test the 4S couldn't even hit 50% of that peak bandwidth. The iPhone 5 on the other hand manages to hit over 70% of its peak memory bandwidth. I will say that if these numbers are indeed faked, whoever faked them was smart enough not to violate reality when coming up with these memory bandwidth numbers (e.g. no 95% efficiency numbers show up). It's also clear that these results aren't a simply doubling across the board over the 4S, lending some credibility to them.
Some of the largest performance improvements promised by the Geekbench data appear here in the memory results. It's whatever work Apple did here that helped enable the gains in the integer and floating point results below:
| Geekbench Comparison | |||||
| Integer Performance | iPhone 4S | iPhone 5 (unconfirmed) | Scaling | ||
| Blowfish ST | 10.7 MB/s | 23.4 MB/s | 2.18x | ||
| Blowfish MT | 20.7 MB/s | 45.6 MB/s | 2.20x | ||
| Text Compress ST | 1.21 MB/s | 2.79 MB/s | 2.30x | ||
| Text Compress MT | 2.28 MB/s | 5.19 MB/s | 2.27x | ||
| Text Decompress ST | 1.71 MB/s | 3.82 MB/s | 2.23x | ||
| Text Decompress MT | 2.84 MB/s | 5.60 MB/s | 2.67x | ||
| Image Compress ST | 3.32 Mpixels/s | 7.31 Mpixels/s | 2.20x | ||
| Image Compress MT | 6.59 Mpixels/s | 14.2 Mpixels/s | 2.15x | ||
| Image Decompress ST | 5.32 Mpixels/s | 12.4 Mpixels/s | 2.33x | ||
| Image Decompress MT | 10.5 Mpixels/s | 23.0 Mpixels/s | 2.19x | ||
| Lua ST | 215.4 Knodes/s | 455 Knodes/s | 2.11x | ||
| Lua MT | 425.6 Knodes/s | 887 Knodes/s | 2.08x | ||
| MT Scaling | 1.90x | 1.92x | |||
On average we see around 2.2x scaling from the 4S to the 5 in Geekbench's integer tests. There's no major improvement in multicore scaling, confirming what Geekbench tells us that we're looking at a two core/two thread machine.
The gains here are huge and are likely directly embodied in the performance claims that Apple made at the iPhone 5 launch event. Many smartphone workloads (under Android, iOS and Windows Phone despite what Microsoft may tell you) are still very CPU bound. Big increases in integer performance will be apparent in application level improvements.

Don't be surprised to see greater than 2x scaling here even though Apple only promised 2x at the event. Remember that what you're looking at is raw compute tests without many of the constraints that apply to application level benchmarks. While Apple has used benchmarks in the past to showcase performance, all of its performance claims at launch were application level tests. Those types of tests are more constrained and will show less scaling. That being said, I am surprised to see application level tests that were so close to the 2.2x average scaling we see here. Apple could have moved to faster NAND/storage controller here as well, which could help most if not all of these situations.
| Geekbench Comparison | |||||
| Floating Point Performance | iPhone 4S | iPhone 5 (unconfirmed) | Scaling | ||
| Mandelbrot ST | 223 MFLOPS | 397 MFLOPS | 1.77x | ||
| Mandelbrot MT | 438 MFLOPS | 766 MFLOPS | 1.74x | ||
| Dot Product ST | 177 MFLOPS | 322 MFLOPS | 1.81x | ||
| Dot Product MT | 353 MFLOPS | 627 MFLOPS | 1.77x | ||
| LU Decomposition ST | 171 MFLOPS | 387 MFLOPS | 2.25x | ||
| LU Decomposition MT | 348 MFLOPS | 767 MFLOPS | 2.20x | ||
| Primality ST | 142 MFLOPS | 370 MFLOPS | 2.59x | ||
| Primality MT | 260 MFLOPS | 676 MFLOPS | 2.59x | ||
| Sharpen Image ST | 1.35 Mpixels/s | 4.85 Mpixels/s | 3.59x | ||
| Sharpen Image MT | 2.67 Mpixels/s | 9.28 Mpixels/s | 3.47x | ||
| Blur Image ST | 0.53 Mpixels/s | 1.96 Mpixels/s | 3.68x | ||
| Blur Image MT | 1.06 Mpixels/s | 3.78 Mpixels/s | 3.56x | ||
| MT Scaling | 1.96x | 1.92x | |||
The floating point benchmarks show "milder" scaling in the first few tests (sub-2x) but big scaling in the latter ones. My guess here is we're seeing some of the impacts of increased memory bandwidth at the end there. If you look at our iPhone 5 hands-on video you'll see Brian talking about how super fast the new flyover mode in iOS 6 Maps is on the 5 compared to the 4S. That's likely due in no small part to the improved memory interface.
Although Geekbench is cross platform, I wouldn't recommend using this data to do anything other than compare iOS devices. I've looked at using Geekbench to compare iOS to Android in the past and I've sometimes seen odd results.
I'm sure we'll learn a lot more about the A6 SoC over the coming days/weeks.








118 Comments
View All Comments
doobydoo - Tuesday, September 18, 2012 - link
You are correct.The Huawei Ascend P1 is much. much thicker at its thickest point.
There seems to be no consensus or authoritative documentation on the Oppo Finder - in terms of how fat it is at the bulge, some say 7.1 some say 7.8 having navigated around.
What all these phones which people are claiming are thinner have in common, as you state - is thicker points so they shouldn't really claim to be as thin as they are.
Either way - when you have to cite the 'Huawei Ascend P1 or the Oppo Finder' to find a questionably thinner phone - I think you make Apples point :-)
xype - Monday, September 17, 2012 - link
I like it how short of being ~8 times faster than anyone else in the market for the next 4 years a custom Apple-designed CPU seem to be a dissapointment to the enlightened audience of AnandTech. :)Good thing it’s built into an iPhone 5, too, since that’s obviously going to sink Apple as well, being as lame as it is, eh?
KoolAidMan1 - Monday, September 17, 2012 - link
They madtipoo - Monday, September 17, 2012 - link
I'm not disappointed, if this is true I'm pretty impressed.nitram_tpr - Monday, September 17, 2012 - link
The only people who care are geeks who can run benchmarks. Normal punters really don't give a rats ass, the majority of people who have pre-ordered or are gonna queue are doing it because they have to have the latest version, because it's the latest, not because it's the quickest.iPhones (iDevices as a whole) sell in huge amounts regardless of the performance. I think the 5 will sell better than the 4s because it is visibly different, you can put it next to a 4 / 4s and other people will see and say 'ooooh thats the new iPhone'.
the 4s is a pretty smooth running phone, it makes me laugh, every single increment of the iPhone has been smooth running comapred to the last. When being reviewed the new one makes the last one seem like a piece of crap.
doobydoo - Monday, September 17, 2012 - link
I think you make a good point.But there's a reason why iPhone users don't generally concern themselves with performance - for them, performance has never been an issue - as you state.
Contrast to Android phones, the vast majority of which are laggy and glitchy when being used - particularly those which run older versions of Android (which is the majority). iOS users can almost forget hardware specifications as an issue because everything just works smoothly on their phone and apps are designed for their hardware. Android users aren't so lucky - which is why they need to focus so much on benchmarks.
A large part of why Apple managed this is the optimisation of iOS for their specific hardware, and lack of fragmentation. For example, an app developer for Android can't optimise the app for every Android phone to make sure it doesn't lag - but iOS developers can.
The second reason is that the GPU's in iPhones of late dominate the benchmarks, and I believe a faster GPU is more perceptible for the end users, as it affects the graphical rendering (the part which can appear stuttery). An end user doesn't feel if an app takes 0.1 seconds longer to load. But they sure as hell feel it if graphics start to stutter.
pjc78 - Monday, September 17, 2012 - link
What's sad is that the realization that good GPUs give a good user experience does not extend to the iMac or Mac Pro, and even the MacBook Pro to a lesser extent. Seriously, Radeon 5870 is the best Mac Pro GPU?web2dot0 - Monday, September 17, 2012 - link
How the hell are you gonna put a 300W GPU into a iMac buddy or in a MacBook Pro? What you some sort of thermo genius?The target market for iMac and MacBook are people trying to get 100fps in Crysis.
What's sad is you still don't get it.
lkm32 - Sunday, September 23, 2012 - link
Engineers kind of need some sort of GPU processing for simulations.Also, they don't seem to be doing that well when it comes to heat anyhow, with some of my colleagues with Macbook Pros getting the things damn hot.
I personally have a T430s and a W520 ... most reliable things I have ever bought (Other than my sonofagun Moto Defy running CM10 ... that thing has been to the Arctic, mountain climbing, deep sea fishing and back and still runs smoothly thanks to Jelly Bean).
On that note, I need a new rugged phone with a bit of oomph. Not the iPhone5 as somebody got it and showed it to me and it is nowhere as rugged as I want ... sure metal is great to touch, but it feels a bit too fragile (I guess it's awesome for most people, but I need a heavy duty phone and that it is not).
Any suggestions (since you get it and all)?
robinthakur - Monday, September 17, 2012 - link
True that, having put Jelly Bean onto the Nexus 7, it still isn't as smooth as even the first iPhone, which is completely mental. Scrolling in Chrome is hardly "buttery smooth" as Google would have you believe, its more like vaseline mixed with sand. The G3 behaves differently depending on how much free internl storage it has available also. 2/3 full, and it starts to lag and stutter in a way i've never experienced on iOS. Even loading times should be positively impacted by the faster Nand in the IP5 which is great. Due to the fragmentation, there are hardly any apps which can be used to demo the extra speed on Androids other than benchmarks. The main game I used to show off the power of my old quad core Exynos Galaxy 3? Angry Birds Space. It ran almost as smoothly as it did on iOS. I'm very glad Apple have pushed the capabilities of the GPU, as it should be very noticeable to end users.