The GeForce GTX 660 Ti Review, Feat. EVGA, Zotac, and Gigabyte
by Ryan Smith on August 16, 2012 9:00 AM ESTThat Darn Memory Bus
Among the entire GTX 600 family, the GTX 660 Ti’s one unique feature is its memory controller layout. NVIDIA built GK104 with 4 memory controllers, each 64 bits wide, giving the entire GPU a combined memory bus width of 256 bits. These memory controllers are tied into the ROPs and L2 cache, with each controller forming part of a ROP partition containing 8 ROPs (or rather 1 ROP unit capable of processing 8 operations), 128KB of L2 cache, and the memory controller. To disable any of those things means taking out a whole ROP partition, which is exactly what NVIDIA has done.
The impact on the ROPs and the L2 cache is rather straightforward – render operation throughput is reduced by 25% and there’s 25% less L2 cache to store data in – but the loss of the memory controller is a much tougher concept to deal with. This goes for both NVIDIA on the design end and for consumers on the usage end.
256 is a nice power-of-two number. For video cards with power-of-two memory bus widths, it’s very easy to equip them with a similarly power-of-two memory capacity such as 1GB, 2GB, or 4GB of memory. For various minor technical reasons (mostly the sanity of the engineers), GPU manufacturers like sticking to power-of-two memory busses. And while this is by no means a true design constraint in video card manufacturing, there are ramifications for skipping from it.
The biggest consequence of deviating from a power-of-two memory bus is that under normal circumstances this leads to a card’s memory capacity not lining up with the bulk of the cards on the market. To use the GTX 500 series as an example, NVIDIA had 1.5GB of memory on the GTX 580 at a time when the common Radeon HD 5870 had 1GB, giving NVIDIA a 512MB advantage. Later on however the common Radeon HD 6970 had 2GB of memory, leaving NVIDIA behind by 512MB. This also had one additional consequence for NVIDIA: they needed 12 memory chips where AMD needed 8, which generally inflates the bill of materials more than the price of higher speed memory in a narrower design does. This ended up not being a problem for the GTX 580 since 1.5GB was still plenty of memory for 2010/2011 and the high pricetag could easily absorb the BoM hit, but this is not always the case.
Because NVIDIA has disabled a ROP partition on GK104 in order to make the GTX 660 Ti, they’re dropping from a power-of-two 256bit bus to an off-size 192bit bus. Under normal circumstances this means that they’d need to either reduce the amount of memory on the card from 2GB to 1.5GB, or double it to 3GB. The former is undesirable for competitive reasons (AMD has 2GB cards below the 660 Ti and 3GB cards above) not to mention the fact that 1.5GB is too small for a $300 card in 2012. The latter on the other hand incurs the BoM hit as NVIDIA moves from 8 memory chips to 12 memory chips, a scenario that the lower margin GTX 660 Ti can’t as easily absorb, not to mention how silly it would be for a GTX 680 to have less memory than a GTX 660 Ti.
Rather than take the usual route NVIDIA is going to take their own 3rd route: put 2GB of memory on the GTX 660 Ti anyhow. By putting more memory on one controller than the other two – in effect breaking the symmetry of the memory banks – NVIDIA can have 2GB of memory attached to a 192bit memory bus. This is a technique that NVIDIA has had available to them for quite some time, but it’s also something they rarely pull out and only use it when necessary.
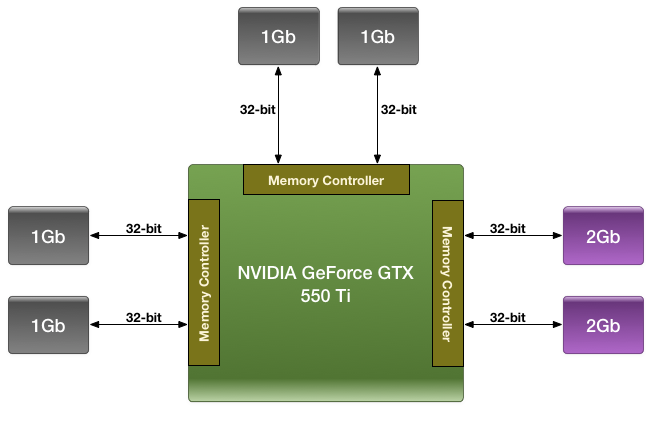
We were first introduced to this technique with the GTX 550 Ti in 2011, which had a similarly large 192bit memory bus. By using a mix of 2Gb and 1Gb modules, NVIDIA could outfit the card with 1GB of memory rather than the 1.5GB/768MB that a 192bit memory bus would typically dictate.
For the GTX 660 Ti in 2012 NVIDIA is once again going to use their asymmetrical memory technique in order to outfit the GTX 660 Ti with 2GB of memory on a 192bit bus, but they’re going to be implementing it slightly differently. Whereas the GTX 550 Ti mixed memory chip density in order to get 1GB out of 6 chips, the GTX 660 Ti will mix up the number of chips attached to each controller in order to get 2GB out of 8 chips. Specifically, there will be 4 chips instead of 2 attached to one of the memory controllers, while the other controllers will continue to have 2 chips. By doing it in this manner, this allows NVIDIA to use the same Hynix 2Gb chips they already use in the rest of the GTX 600 series, with the only high-level difference being the width of the bus connecting them.

Of course at a low-level it’s more complex than that. In a symmetrical design with an equal amount of RAM on each controller it’s rather easy to interleave memory operations across all of the controllers, which maximizes performance of the memory subsystem as a whole. However complete interleaving requires that kind of a symmetrical design, which means it’s not quite suitable for use on NVIDIA’s asymmetrical memory designs. Instead NVIDIA must start playing tricks. And when tricks are involved, there’s always a downside.
The best case scenario is always going to be that the entire 192bit bus is in use by interleaving a memory operation across all 3 controllers, giving the card 144GB/sec of memory bandwidth (192bit * 6GHz / 8). But that can only be done at up to 1.5GB of memory; the final 512MB of memory is attached to a single memory controller. This invokes the worst case scenario, where only 1 64-bit memory controller is in use and thereby reducing memory bandwidth to a much more modest 48GB/sec.
How NVIDIA spreads out memory accesses will have a great deal of impact on when we hit these scenarios. In the past we’ve tried to divine how NVIDIA is accomplishing this, but even with the compute capability of CUDA memory appears to be too far abstracted for us to test any specific theories. And because NVIDIA is continuing to label the internal details of their memory bus a competitive advantage, they’re unwilling to share the details of its operation with us. Thus we’re largely dealing with a black box here, one where poking and prodding doesn’t produce much in the way of meaningful results.
As with the GTX 550 Ti, all we can really say at this time is that the performance we get in our benchmarks is the performance we get. Our best guess remains that NVIDIA is interleaving the lower 1.5GB of address while pushing the last 512MB of address space into the larger memory bank, but we don’t have any hard data to back it up. For most users this shouldn’t be a problem (especially since GK104 is so wishy-washy at compute), but it remains that there’s always a downside to an asymmetrical memory design. With any luck one day we’ll find that downside and be able to better understand the GTX 660 Ti’s performance in the process.








313 Comments
View All Comments
rarson - Friday, August 17, 2012 - link
I might have said that ten years ago, but when I read stuff like "the GTX 680 marginalized the Radeon HD 7970 virtually overnight," I wonder what kind of bizarro universe I've stumbled into.CeriseCogburn - Sunday, August 19, 2012 - link
That's the sales numbers referred to there rarson - maybe you should drop the problematic amnesia ( I know you can't since having no clue isn't amnesia), but as a reminder, amd's crap card was $579 bucks and beyond and nVidia dropped in 680 at $499 across the board...Amd was losing sales in rapid fashion, and the 680 was piling up so many backorders and pre-purchases that resellers were gbegging for relief, and a few reviewers were hoping something could be done to stem the immense backorders for the 680.
So:
" "the GTX 680 marginalized the Radeon HD 7970 virtually overnight,"
That's the real world, RECENT HISTORY, that real bizarro world you don't live in, don't notice, and most certainly, will likely have a very difficult time admitting exists.
Have a nice day.
Biorganic - Saturday, August 18, 2012 - link
Go look up Bias in a dictionary instead of flinging around insults like a child. When the adults converse amongst themselves they like to Add things to the actual conversation, not unnecessarily degrade people. Thanks! @$$-OJamahl - Thursday, August 16, 2012 - link
The point I was making was that Nvidia has seeded overclocked cards to the majority of the tech press, while you had a go at AMD for their 7950 boost.After all the arguments and nonsense over the 7950 boost, hardly anyone benchmarked it but still plenty went ahead and benched the overclocked cards sent by Nvidia. Two AMD partners have shown they are releasing the 7950 boost edition asap, prompting a withdrawal of the criticisms from another nvidia fansite, hardwarecanucks.com
So again I ask, AMD's credibility? The only credibility at stake is the reviewers who continually bend over to suit Nvidia. Nvidia has no credibility to lose.
silverblue - Friday, August 17, 2012 - link
I'm afraid I have to back you up on this one. NVIDIA released not one, not two but THREE GT 640s, and I think people have forgotten about that one. AMD have replaced the 7950 BIOS and as such have overclocked it to the performance level where it probably should've been to start with (the gap between 7950 and 7970 was always far more than the one between 7870 and 7950).Yes, AMD should've given it a new name - 7950 XT as I said somewhere recently - but it's not even two-thirds as bad as the GT 640 fiasco. At least this time, we're talking two models separated only by a BIOS change and the consequently higher power usage, not two separate GPU generations with vastly different clocks, shader counts, memory types and so on.
If I'm wrong, I'm wrong, however I don't understand how AMD's GPU division's credibility could be damaged by any of this. Feel free to educate me. :)
CeriseCogburn - Sunday, August 19, 2012 - link
For your education and edification: amd failed in their card release by clocking it too low because they had lost the power useage war(and they knew it), and charging way too much on release.They suck, and their cred is ZERO, because of this.
Now it not only harmed amd, it harmed all of us, and all their vender partners, we all got screwed and all lost money because of amd's greed and incompetence.
Now amd, in a desperate panic, and far too long after the immense and debilitating blunder, that also left all their shareholders angry (ahem), after dropping the prices in two or three steps and adding 3 games to try to quell the massive kicking their falling sales to nVidia injuries...
FINALLY pulled their head out of it's straight jacket, well, halfway out, and issued permission for a GE version.
Now, maybe all you amd fans have been doing much and very excessive lying on 78xx79xx OC capabilities, or amd is just dumb as rocks and quite literally dangerous to themselves, the markets, their partners, all of us.
I think it's a large heaping of BOTH.
So there we have it - amd cred is where amd fanboy cred is - at the bottom of the barrel of slime.
Galidou - Sunday, August 19, 2012 - link
Anyway, with you AMD fails, always failed and will continue to fail at everything... I don't know if you think people will read your posts like religious madmans and beleive it a 100%, you're making it so exagerated, that it's barely readable.The words nazi and such comes back so often when you go on the madman route, that it's a wonder if anyone gives you any credibility. A little sad because you have nice arguments, you just display them surrounded by so much hate, it's hard to give you any credit for them.
We do exagerate AMD's performance just for the sake of being fanboys, but not to the point of saying such debilitating stuff like you're so good at it. Not to the point of totally destroying Nvidia and saying it's worth NOTHING like you do for AMD. I may lean a little on AMD's side because for my money they gave me more performance from the radeon 4xxx to the 6xxx series. I won't forget my 8800gt either, that was a delight for the price too. But I can recon when a video card wins at EVERYTHING and is doing WONDERS and none is happening now, it's a mixed bag of feeling. between overclockability, optimization on certain games, etc...
When the 8800gt and radeon 4870 came out, there was nothing people could say, just nothing, for the price, they were wonders, trampling over anythingbefore and after but at the same time you said they were mistake because they were not greedy enough moves.
Wanna speak about greed, why is Nvidia so rich, you defend the most rich video card maker in history but you accuse the others of being greedy, society is built on greed, go blame others. Couldn't they sell their GPU at lower prices to kill AMD and be less greedy? No, if AMD die, you'll see greed and 800$ gpus, speak about greed.
CeriseCogburn - Thursday, August 23, 2012 - link
Didn't read your loon spiel, again, not even glossed, part of 1st sentence.I won't tell you to shut up or change what you say, because I'm not a crybaby like you.
AMD sucks, they need help, and they only seem to fire more people.
Galidou - Thursday, August 23, 2012 - link
To date your best argument that repeats itself is ''AMD sucks'' which is something you learn to say when you're a kid. You're not a crybaby ohhh that's new, you keep crying more than everyone else I've seen, TheJian might be a fanboy but you're more related to the fanatic side of the thing.Still, they are the most rich video maker in history, but they still try to manipulate opinions like every company does. Why? if their product is so good and perfect, why do they have to manipulate? I hear you already saying something like: It's because that AMD suck, they suck so much that Nvidia has to make em suck even more by manipulating the stoopid reviewers because the world is against Nvidia and I'm their Crusader.... good job.
CeriseCogburn - Thursday, August 23, 2012 - link
Yes, I've never crapload of facts nor a single argument of note, and your head is a bursting purple strawberry too mr whiner.