GTC 2012 Part 1: NVIDIA Announces GK104 Based Tesla K10, GK110 Based Tesla K20
by Ryan Smith on May 17, 2012 3:15 AM ESTThe other Tesla announced this week is Tesla K20, which is the first and so far only product announced that will be using GK110. Tesla K20 is not expected to ship until October-November of this year due to the fact that GK110 is still a work in progress, but since NVIDIA is once again briefing developers of the new capabilities of their leading compute GPU well ahead of time there’s little reason not to announce the card, particularly since they haven’t attached any solid specifications to it beyond the fact that it will be composed of a single GK110 GPU.

GK110 itself is a bit of a complex beast that we’ll get into more detail about later this week, but for now we’ll quickly touch upon some of the features that make GK110 the true successor to GF110. First and foremost of course, GK110 has all the missing features that GK104 lacked – ECC cache protection, high double precision performance, a wide memory bus, and of course a whole lot of CUDA Cores. Because GK110 is still in the lab NVIDIA doesn’t know what will be viable to ship later this year, but as it stands they’re expecting triple the double precision performance of Tesla M2090, with this varying some based on viable clockspeeds and how many functional units they can ship enabled. Single precision performance should also be very good, but depending on the application there’s a decent chance that K10 could beat K20, at least in the type of applications that are well suited for GK104’s limitations.
As it stands a complete GK110 is composed of 15 SMXes – note that these are similar but not identical to GK104 SMXes – bound to 1.5MB of L2 cache and a 384bit memory bus. GK110 SMXes will contain 192 CUDA cores (just like GK104), but deviating from GK104 they will contain 64 CUDA FP64 cores (up from 8, which combined with the much larger SMX count is what will make K20 so much more powerful at double precision math than K10. Of interesting note, NVIDIA is keeping the superscalar dispatch method that we first saw in GF104 and carried over to GK104, so unlike Fermi Tesla products, compute performance on K20 is going to be a little more erratic as a result of the fact that maximizing SMX utilization will require a high degree of both TLP and ILP.

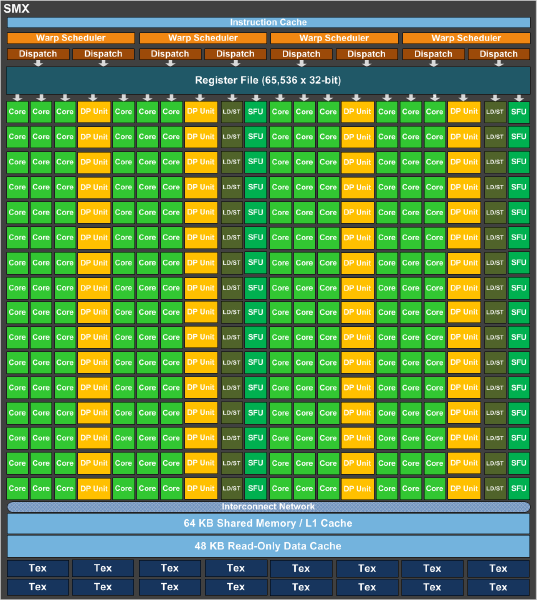
Along with the slew of new features native to the Kepler family and some new Kepler family compute instructions being unlocked with CUDA 5, GK110/K20 will be bringing with it two major new features that are unique to just GK110: Hyper-Q and Dynamic Parallelism. We’ll go over both of these in depth in the near future with our look at GK110, but for the time being we’ll quickly touch on what each of them does.
Hyper-Q is NVIDIA’s name for the expansion of the number of work queues in the GPU. With Fermi NVIDIA’s hardware only supported 1 hardware work queue, whereas GK110 will support 32 work queues. The important fact to take away from this is that 1 work queue meant that Fermi could be under occupied at times (that is, hardware units were left without work to do) if there wasn’t enough work in that queue to fill every SM, even with parallel kernels in play. By having 32 work queues to select from, GK110 can in many circumstances achieve higher utilization by being able to put different program streams on what would otherwise be an idle SMX.


The other major new feature here was Dynamic Parallelism, which is NVIDIA’s name for the ability for kernels to be able to dispatch other kernels. With Fermi only the CPU could dispatch a new kernel, which incurs a certain amount of overhead by having to communicate back and forth with the CPU. By giving kernels the ability to dispatch their own child kernels, GK110 can both save time by not having to go back to the GPU, and in the process free up the CPU to work on other tasks.
Wrapping things up, there are a few other features new to GK110 such as a new grid management unit, RDMA, and a new ISA encoding scheme, all of which are intended to further improve NVIDIA’s compute performance, both over Fermi and even GK104. But we’ll save these for another day when we look at GK110 in depth.








51 Comments
View All Comments
Ananke - Thursday, May 17, 2012 - link
I would bet 1/1 or 1/2 is better, but we will see the outcome of the battle when Handbrake gets OpenCL acceleration on both NVidia and AMD units.I think Radeons are better for heavy computations, but then the sheer user base of CUDA is larger - it is just cheaper to replace Fermi with Kepler accelerators.
Ryan Smith - Thursday, May 17, 2012 - link
These are the same FP64 CUDA Cores that we saw on GK104. So they cannot do FP32. They can only be used for FP64 operations.kilkennycat - Thursday, May 17, 2012 - link
I have been working closely with a professional developer of CUDA applications targeting real-time processing of Broadcast-Quality HD video signals (frame-rate conversion, re-sizing, slow-motion, de-interlacing etc) using multiple GTX5xx cards operating in tandem (no need for SLI) None of the underlying algorithms require any Double-Precision computation, Single-Precision is more than adequate.After much waiting, last week he managed to finally acquire a GTX680 board and ran benchmarks for that board against a GTX580. He found that the average GTX680 conversion frame-rate on an extensive test-suite dropped to less than 2/3 of that available with a single GTX580, actually only a little better than the frame--rate available from a previously-tested 900MHz overclocked GTX560Ti. Further technical analysis revealed conclusively that the 256-bit memory interface of the GK104 was the performance killer.....
krslavin - Sunday, May 20, 2012 - link
I have been doing the exact same thing! I ran tests on my frame-rate converter and the GTX 680 got only 70% of a GTX 580! I also thought it was the reduced cache bandwidth because there are only 8 SMs instead of 16. I also do not use double precision FP, but it seems that specmanship and marketing wins out over common sense ;^(g101 - Saturday, July 14, 2012 - link
Indeed it does...Ursus.se - Saturday, May 19, 2012 - link
What I can understands fit this unit into remarks to me from inside Apple about a new real up to date MacPro for FCPX user...Lets hope...
Ursus
g101 - Saturday, July 14, 2012 - link
You can also shut the fuck up.Professionals don't use "FCPX!!!" . Someone needs to grasp you around the neck and wake your obviously dormant brain into a state of at least partial activity.
garyab33 - Tuesday, May 22, 2012 - link
I really hope 2 of these cards is SLI will be finally able to run Metro 2033 at 1920x1080 with everything maxed out (DoF & Tessellation ON) and Crysis 1 (16AA and 16AF), also everything set to highest in NV control panel, at stable 100-120 fps. I don't care about the heat nor the power consumption of GK110 as long as it produce 60+ fps in most demanding games, and in SLI above 100fps. That's how the games are supposed to be played. Gtx 680 is a joke, it is slightly better than gtx 580 in Metro 2033. Doesnt worth the wait and price for gtx 680.CeriseCogburn - Wednesday, May 23, 2012 - link
Like I said.Even after 680's are present and sold, people like you say they can't be built.
I do wonder if you're wearing your shoes after you attempt to tie the shoelaces.
No looking down before you answer.
g101 - Saturday, July 14, 2012 - link
Shut the fuck up dumbass.You never have anything worthwhile to say, it's always some unintelligible pro-nvidia rubbish that doesn't even address the previous comments.
There's no question in ours minds, we know nvidia can make a hobbled bit of rubbish and sell it to little dipshits who spend all their time commenting about their favorite computer hardware brand.
Every. Single. Article.