What We've Been Waiting For: Testing OpenCL Accelerated Handbrake with AMD's Trinity
by Anand Lal Shimpi on May 15, 2012 1:23 PM ESTAMD, and NVIDIA before it, has been trying to convince us of the usefulness of its GPUs for general purpose applications for years now. For a while it seemed as if video transcoding would be the killer application for GPUs, that was until Intel's Quick Sync showed up last year.
With Trinity, AMD has an answer to Quick Sync with its integrated VCE, however the performance is hardly as similar as the concept. In applications that take advantage of both Quick Sync and VCE, the Intel solution is considerably faster. While this first implementation of working VCE is better than x86 based transcoding on AMD's APUs, it still needs work:

Quick Sync's performance didn't move all users to Sandy/Ivy Bridge based video transcoding. One of its biggest limitations is the lack of good software support for the standard. We use applications like Arcsoft's Media Converter 7.5 and Cyber Link's Media Espresso 6.5 not because we want to, but because they are among the few transcoding applications that support Quick Sync. What we'd really like to see is support for Quick Sync in x264 or through an application like Handbrake.
The open source community thus far hasn't been very interested in supporting Intel's proprietary technologies. As a result, Quick Sync remains unused by the applications we want to use for video transcoding.
In our conclusion to this morning's Trinity review, we wrote that AMD's portfolio of GPU accelerated consumer applications is stronger now than it has ever been before. Photoshop CS6, GIMP, Media Converter/Media Espresso and WinZip 16.5 for the most part aren't a list of hardly used applications. These are big names that everyone is familiar, that many have actual seat time with. Now there's always the debate of whether or not the things you do with these applications are actually GPU accelerated, but AMD is at least targeting the right apps with its GPU compute efforts.
The list is actually a bit more impressive than what we've published thus far. Several weeks ago AMD dropped a bombshell: x264 and Handbrake would both feature GPU acceleration, largely via OpenCL, in the near future. I begged for an early build of both of them and eventually got just that. What you see below may look like a standard Handbrake screenshot, but it's actually a look at an early build of the OpenCL accelerated version of Handbrake:
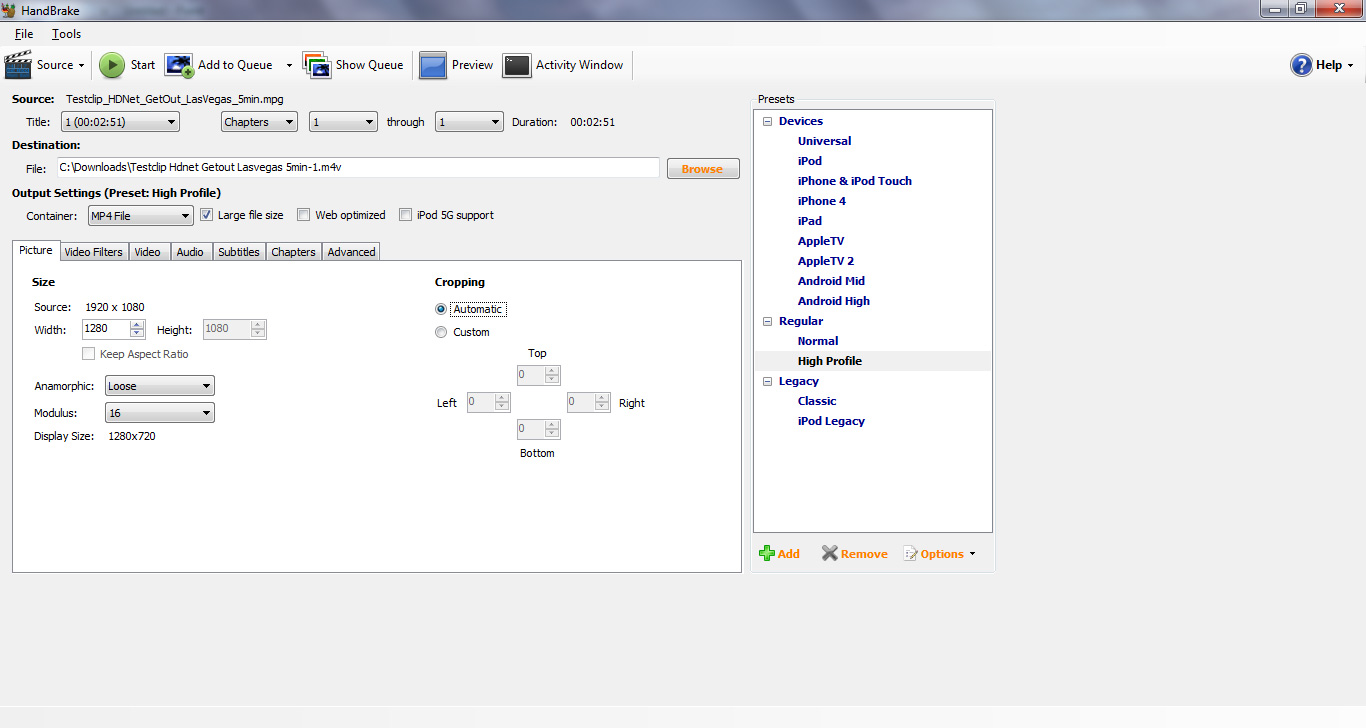
As I mentioned before, the application isn't ready for prime time yet. The version I have is currently 32-bit only and it doesn't allow you to manually enable/disable GPU acceleration. Instead, to compare the x86 and OpenCL paths we have to run the beta Handbrake release against the latest publicly available version of the software.
GPU acceleration in Handbrake comes via three avenues: DXVA support for GPU accelerated video decode, OpenCL/GPU acceleration for video scaling and color space conversion, and OpenCL/GPU acceleration of the lookahead function of the x264 encoding process.
Video decode is the lowest hanging fruit to improving video transcode performance, and by using the DXVA API Handbrake can leverage the hardware video decode engine (UVD) on Trinity as well as its counterpart in Intel's Sandy/Ivy Bridge.
The scaling, color conversion and lookahead functions of the encode process are similarly obvious candidates for offloading to the GPU. The latter in particular is already data parallel and runs in its own thread, making it a logical fit for the GPU. The lookahead function determines how many frames the encoder should look ahead in time in the input stream to achieve better image quality. Remember that video encoding is fundamentally a task of figuring out which parts of frames remain unchanged over time and compressing that redundant data.
GPU usage during transcode in the OpenCL enhanced version of Handbrake
We're still working on a lot of performance/quality characterization of Handbrake, but to quickly illustrate what it can do we performed a simple transcode of a 1080p MPEG-2 source using Handbrake's High Profile defaults and a 720p output resolution.
The OpenCL accelerated Handbrake build worked on Sandy Bridge, Ivy Bridge as well as the AMD APUs, although obviously Sandy Bridge saw no benefit from the OpenCL optimizations. All platforms saw speedups however, implying that Intel benefitted handsomely from the DXVA decode work. We ran both 32-bit x86 and 32-bit GPU accelerated results on all platforms. The results are below:

*SNB's GPU doesn't support OpenCL, video decode should be GPU accelerated, all OpenCL work is handled by the CPU
While video transcoding is significantly slower on Trinity compared to Intel's Sandy Bridge on the traditional x86 path, the OpenCL version of Handbrake narrows the gap considerably. A quad-core Sandy Bridge goes from being 73% faster down to 7% faster than Trinity. Ivy Bridge on the other hand goes from being 2.15x the speed of Trinity to a smaller but still pronounced 29.6% lead. Image quality appeared to be comparable between all OpenCL outputs, although we did get higher bitrate files from the x86 transcode path. The bottom line is that AMD goes from a position of not really competitive, to easily holding its own against similarly priced Intel parts.
This truly is the holy grail for what AMD is hoping to deliver with heterogeneous compute in the short term. The Sandy Bridge comparison is particularly telling. What once was a significant performance advantage for Intel, shrinks to something unnoticeable. If AMD could achieve similar gains in other key applications, I think more users would be just fine in ignoring the CPU deficit and would treat Trinity as a balanced alternative to Intel. The Ivy Bridge gap is still more significant but it's also a much more expensive chip, and likely won't appear at the same price points as AMD's A10 for a while.
We're working on even more examples of where AMD's work in enabling OpenCL accelerated applications are changing the balance of power in the desktop. Handbrake is simply the one we were most excited about. It will still be a little while before there are public betas of x264 and Handbrake, but it's at least something we can now look forward to.








60 Comments
View All Comments
vincentlaw - Tuesday, May 15, 2012 - link
Where can we find this build? I've been looking at the nightlies, but there's no explicit statement of support for OpenCL, so I'm not sure which one I need to grab. I know it's not ready for prime time, but for testing purposes, I'm willing to experiment.JarredWalton - Tuesday, May 15, 2012 - link
The OpenCL code at present is developed in house by AMD and they will eventually provide all of the code and documentation back to the open source community. However, for now it is all under tight wraps and there is no way to get it (other than from AMD).CeriseCogburn - Wednesday, May 23, 2012 - link
No, amd is an evil proprietary company who does not practice what it preaches.Shouldn't be a big surprise to amd fans anymore.
ltcommanderdata - Tuesday, May 15, 2012 - link
BenchPress was a bit over the top in replying to many comments with it in the Ask the Experts article, but I think it is a worthwhile question here. Does Handbrake 0.9.6 currently make full use of SSE4.x and AVX? If not, what type of speedup would SSE4.x and AVX support bring and how would it compare to these OpenCL results? If the speedup turns out to be fairly comparable, is adopting SSE4.x/AVX easier for these programs that already make use of other SSE versions than adopting OpenCL? Since that would be a disincentive to GPGPU uptake.BenchPress - Tuesday, May 15, 2012 - link
I'm pretty sure it uses SSE4, but AVX is unlikely since it's basically only floating-point.However, AVX2 extends all integer SIMD instructions to 256-bit as well, doubling the throughput compared to SSE4. And other goodies like gather support, vector-vector shift and any-to-any permutes may help as well. BMI and TSX won't hurt either.
ilovegpu - Tuesday, May 15, 2012 - link
Handbrake uses x264 for encode, x264 for sure uses SSE/AVXBenchPress - Wednesday, May 16, 2012 - link
I checked the code and it only uses AVX-128, which is basically the same as SSE4 but with non-destructive destination operands. So it's not gaining any benefit from the 256-bit floating-point instructions, as expected.AVX2 will extend the integer SIMD instructions to 256-bit as well, effectively doubling the throughput and giving GPGPU a run for its money.
saneblane - Tuesday, May 15, 2012 - link
Trinity just got a lot more interesting. Video conversion is the most demanding thing that 85 percent of people do. And with this, Amd is back in the game. Interesting time ahead indeed.Wow, seems like Trinity my be the swiss army knife of processors.
saneblane - Tuesday, May 15, 2012 - link
"Trinity might be the swiss army knife of processors". that should have read. Wow, this site needs an edit button.CeriseCogburn - Wednesday, May 23, 2012 - link
And just moments ago video conversion was a who cares piece of crap that no real mobile gamer could give a crap about.My my, how times have changed.