The AMD Trinity Review (A10-4600M): A New Hope
by Jarred Walton on May 15, 2012 12:00 AM ESTIntroduction and Piledriver Overview
Brazos and Llano were both immensely successful parts for AMD. The company sold tons despite not delivering leading x86 performance. The success of these two APUs gave AMD a lot of internal confidence that it was possible to build something that didn't prioritize x86 performance but rather delivered a good balance of CPU and GPU performance.
AMD's commitment to the world was that we'd see annual updates to all of its product lines. Llano debuted last June, and today AMD gives us its successor: Trinity.
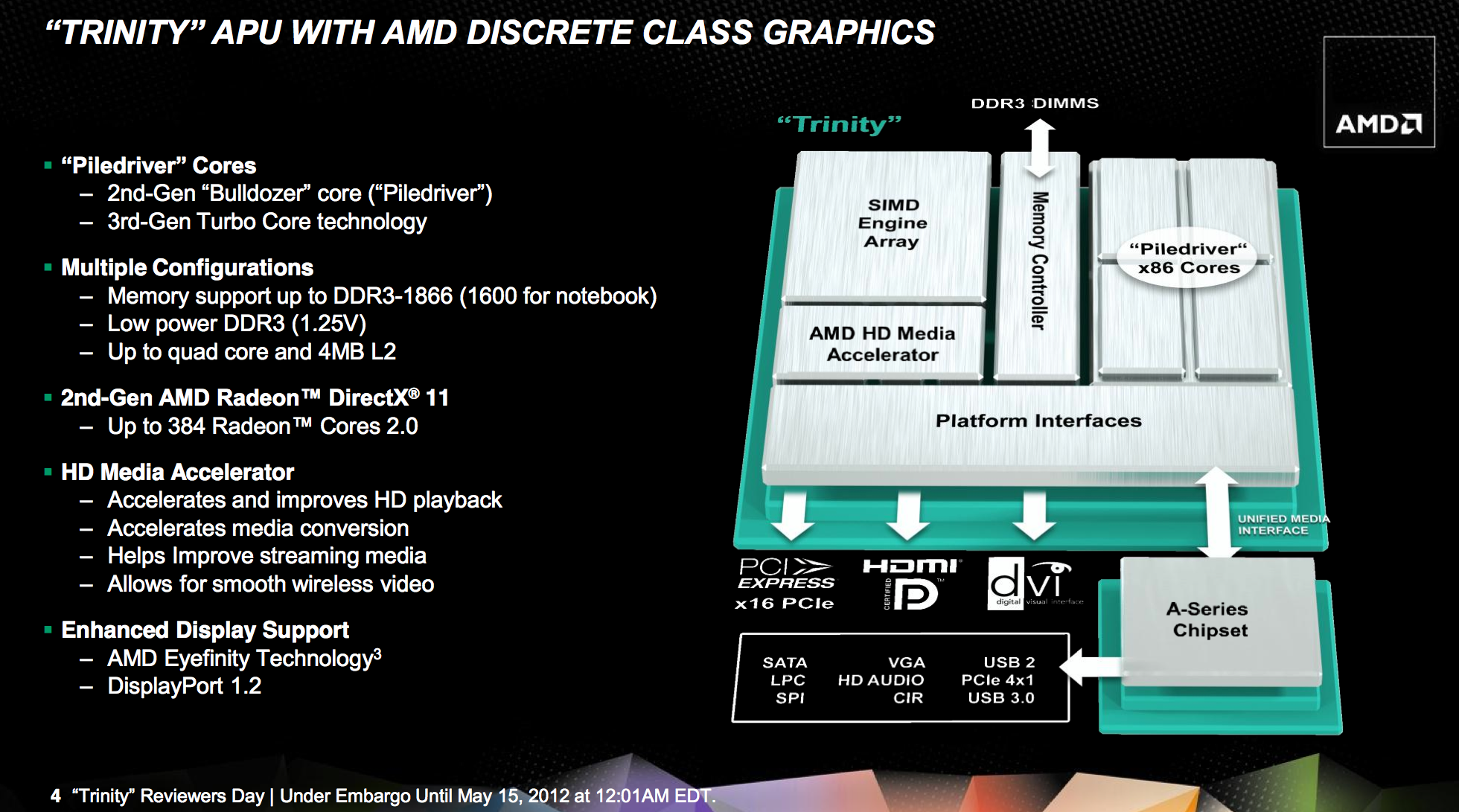
At a high level, Trinity combines 2-4 Piledriver x86 cores (1-2 Piledriver modules) with up to 384 VLIW4 Northern Islands generation Radeon cores on a single 32nm SOI die. The result is a 1.303B transistor chip (up from 1.178B in Llano) that measures 246mm^2 (compared to 228mm^2 in Llano).
| Trinity Physical Comparison | |||||
| Manufacturing Process | Die Size | Transistor Count | |||
| AMD Llano | 32nm | 228mm2 | 1.178B | ||
| AMD Trinity | 32nm | 246mm2 | 1.303B | ||
| Intel Sandy Bridge (4C) | 32nm | 216mm2 | 1.16B | ||
| Intel Ivy Bridge (4C) | 22nm | 160mm2 | 1.4B | ||
Without a change in manufacturing process, AMD is faced with the tough job of increasing performance without ballooning die size. Die size has only gone up by around 7%, but both CPU and GPU performance see double-digit increases over Llano. Power consumption is also improved over Llano, making Trinity a win across the board for AMD compared to its predecessor. If you liked Llano, you'll love Trinity.

The problem is what happens when you step outside of AMD's world. Llano had a difficult time competing with Sandy Bridge outside of GPU workloads. AMD's hope with Trinity is that its hardware improvements combined with more available OpenCL accelerated software will improve its standing vs. Ivy Bridge.
Piledriver: Bulldozer Tuned
While Llano featured as many as four 32nm x86 Stars cores, Trinity features up to two Piledriver modules. Given the not-so-great reception of Bulldozer late last year, we were worried about how a Bulldozer derivative would stack up in Trinity. I'm happy to say that Piledriver is a step forward from the CPU cores used in Llano, largely thanks to a bunch of clean up work from the Bulldozer foundation.
Piledriver picks up where Bulldozer left off. Its fundamental architecture remains completely unchanged, but rather improved in all areas. Piledriver is very much a second pass on the Bulldozer architecture, tidying everything up, capitalizing on low hanging fruit and significantly improving power efficiency. If you were hoping for an architectural reset with Piledriver, you will be disappointed. AMD is committed to Bulldozer and that's quite obvious if you look at Piledriver's high level block diagram:
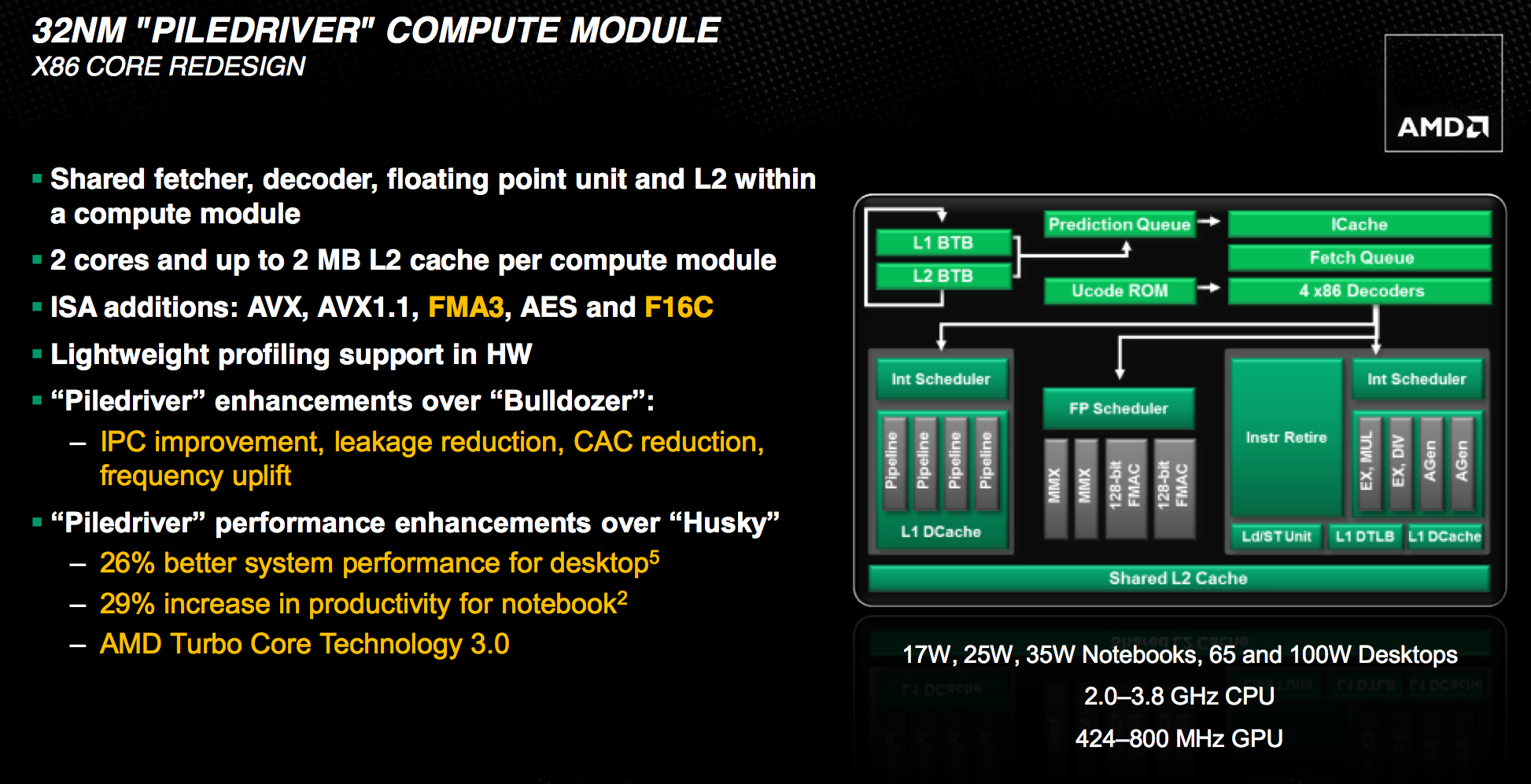
Each Piledriver module is the same 2+1 INT/FP combination that we saw in Bulldozer. You get two integer cores, each with their own schedulers, L1 data caches, and execution units. Between the two is a shared floating point core that can handle instructions from one of two threads at a time. The single FP core shares the data caches of the dual integer cores.
Each module appears to the OS as two cores, however you don't have as many resources as you would from two traditional AMD cores. This table from our Bulldozer review highlights part of problem when looking at the front end:
| Front End Comparison | |||||
| AMD Phenom II | AMD FX | Intel Core i7 | |||
| Instruction Decode Width | 3-wide | 4-wide | 4-wide | ||
| Single Core Peak Decode Rate | 3 instructions | 4 instructions | 4 instructions | ||
| Dual Core Peak Decode Rate | 6 instructions | 4 instructions | 8 instructions | ||
| Quad Core Peak Decode Rate | 12 instructions | 8 instructions | 16 instructions | ||
| Six/Eight Core Peak Decode Rate | 18 instructions (6C) | 16 instructions | 24 instructions (6C) | ||
It's rare that you get anywhere near peak hardware utilization, so don't be too put off by these deltas, but it is a tradeoff that AMD made throughout Bulldozer. In general, AMD opted for better utilization of fewer resources (partially through increasing some data structures and other elements that feed execution units) vs. simply throwing more transistors at the problem. AMD also opted to reduce the ratio of integer to FP resources within the x86 portion of its architecture, clearly to support a move to the APU world where the GPU can be a provider of a significant amount of FP support. Piledriver doesn't fundamentally change any of these balances. The pipeline depth remains unchanged, as does the focus on pursuing higher frequencies.
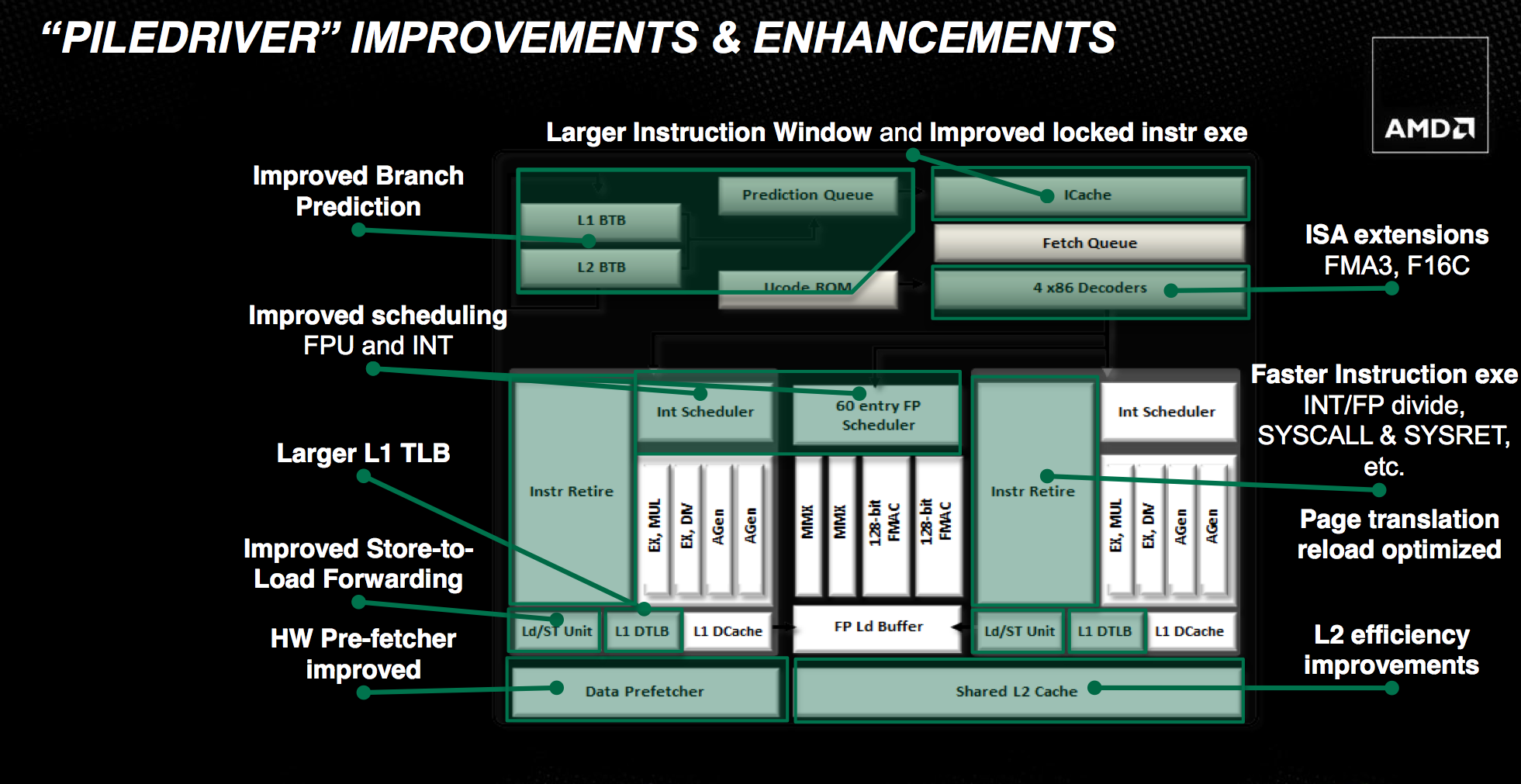
Fundamental to Piledriver is a significant switch in the type of flip-flops used throughout the design. Flip-flops, or flops as they are commonly called, are simple pieces of logic that store some form of data or state. In a microprocessor they can be found in many places, including the start and end of a pipeline stage. Work is done prior to a flop and committed at the flop or array of flops. The output of these flops becomes the input to the next array of logic. Normally flops are hard edge elements—data is latched at the rising edge of the clock.
In very high frequency designs however, there can be a considerable amount of variability or jitter in the clock. You either have to spend a lot of time ensuring that your design can account for this jitter, or you can incorporate logic that's more tolerant of jitter. The former requires more effort, while the latter burns more power. Bulldozer opted for the latter.
In order to get Bulldozer to market as quickly as possible, after far too many delays, AMD opted to use soft edge flops quite often in the design. Soft edge flops are the opposite of their harder counterparts; they are designed to allow the clock signal to spill over the clock edge while still functioning. Piledriver on the other hand was the result of a systematic effort to swap in smaller, hard edge flops where there was timing margin in the design. The result is a tangible reduction in power consumption. Across the board there's a 10% reduction in dynamic power consumption compared to Bulldozer, and some workloads are apparently even pushing a 20% reduction in active power. Given Piledriver's role in Trinity, as a mostly mobile-focused product, this power reduction was well worth the effort.
At the front end, AMD put in additional work to improve IPC. The schedulers are now more aggressive about freeing up tokens. Similar to the soft vs. hard flip flop debate, it's always easier to be conservative when you retire an instruction from a queue. It eases verification as you don't have to be as concerned about conditions where you might accidentally overwrite an instruction too early. With the major effort of getting a brand new architecture off of the ground behind them, Piledriver's engineers could focus on greater refinement in the schedulers. The structures didn't get any bigger; AMD just now makes better use of them.
The execution units are also a bit beefier in Piledriver, but not by much. AMD claims significant improvements in floating point and integer divides, calls and returns. For client workloads these gains show minimal (sub 1%) improvements.
Prefetching and branch prediction are both significantly improved with Piledriver. Bulldozer did a simple sequential prefetch, while Piledriver can prefetch variable lengths of data and across page boundaries in the L1 (mainly a server workload benefit). In Bulldozer, if prefetched data wasn't used (incorrectly prefetched) it would clog up the cache as it would come in as the most recently accessed data. However if prefetched data isn't immediately used, it's likely it will never be used. Piledriver now immediately tags unused prefetched data as least-recently-used, allowing the cache controller to quickly evict it if the prefetch was incorrect.
Another change is that Piledriver includes a perceptron branch predictor that supplements the primary branch predictor in Bulldozer. The perceptron algorithm is a history based predictor that's better suited for predicting certain branches. It works in parallel with the old predictor and simply tags branches that it is known to be good at predicting. If the old predictor and the perceptron predictor disagree on a tagged branch, the perceptron's path is taken. Improving branch prediction accuracy is a challenge, but it's necessary in highly pipelined designs. These sorts of secondary predictors are a must as there's no one-size-fits-all when it comes to branch prediction.
Finally, Piledriver also adds new instructions to better align its ISA with Haswell: FMA3 and F16C.








271 Comments
View All Comments
Spunjji - Wednesday, May 16, 2012 - link
Go away, please.silverblue - Thursday, May 17, 2012 - link
Can you and sans2212 go into a room and fight it out, please? One of you hates AMD, the other wants its babies, and I've a sneaky suspicion that, like matter and antimatter, you might actually cancel each other out.(they also both cease to exist, but I thought that'd be a bit cruel)
e36Jeff - Tuesday, May 15, 2012 - link
oh well, thanks for checking, and thanks for the reply. I guess I'll just have to wait for you guys to get your hands on an actual LV/ULV trinity chip.plonk420 - Tuesday, May 15, 2012 - link
is the Dell V131 tested 2, 4, or 6gb? (i.e. single or dual channel) and how about the other laptops?JarredWalton - Tuesday, May 15, 2012 - link
I actually stuck in 2x4GB DDR3-1600 from the IVY system to make things "equal". Sorry for not noting that. I did the same for Llano, Trinity, and QC SNB. Same SSD, same RAM -- though Llano and SNB ran the RAM at DDR3-1333.Iketh - Tuesday, May 15, 2012 - link
Awesome article Jarred!I caught only one mistake...
"Power consumption is also improved over Llano, making Trinity is a win across the board for AMD compared to its predecessor."
SuperVeloce - Tuesday, May 15, 2012 - link
"Llano was already faster in general use than Core 2 Duo and Athlon X2 class hardware."This is so wrong, it's beggar belief. Just for comparison, my old C2D T8300 (2,4ghz, 3mb L2) is actually faster than A4-3300 overclocked to 2,8ghz in every task and benchmark i throw at them. Even at 2,6ghz it's only on par with T7500 (2,2ghz, 4mb L2, year 2006 my friends).
Well yes, I guess A4 (not overclocked) is less power-hungry and can do quite a bit of undervolting but you see my point... liano is slower than equivalent mobile c2d, if Open-CL from gpu is not in use.
JarredWalton - Tuesday, May 15, 2012 - link
Care to provide some specific benchmarks that prove this out? Because by my numbers, it doesn't look that way:http://www.anandtech.com/show/2585/6
I didn't post Cinebench 10 in the article, but Trinity scores 2834 single-threaded and 8222 multi-threaded. That makes the single-threaded score basically tied with the Core 2 Duo X7900 (2.8GHz) and the multi-threaded score is 50% faster. Llano on the other hand scores 2037 and 6824 in the same tests -- slightly slower than P8400 on single threads but faster on multi-threaded.
PCMark 05 I can provide results for as well, though the SSD certainly skews things on Trinity. Trinity = 10824, Llano (HDD) = 6236, P8400 = 6561 (close enough to Llano), and X7900 = 7544. But I'm not talking specific tasks; I simply said "faster in general use" -- depending on which version of Llano you're talking about. The fastest Core 2 vs. the slowest A8 would probably be a tossup on the CPU side.
eanazag - Tuesday, May 15, 2012 - link
I am disappointed that the desktop versions are not available till Q3. I was thinking this would replace my Core i3 540 at home soon.PolarisOrbit - Tuesday, May 15, 2012 - link
I am wondering if there is a better way to communicate value other than pricing because throughout the article the reviewer estimates Trinity at $600, while in the comments to readers the same reviewer's estimates vary from $700-$800.What is to be made of this discrepency? I am wondering if it wouldn't be better to just avoid price predictions altogether. Surely there is some other way of describing relative value. Maybe estimates of what other setups would have similar performance is enough by itself.