The Intel Ivy Bridge (Core i7 3770K) Review
by Anand Lal Shimpi & Ryan Smith on April 23, 2012 12:03 PM EST- Posted in
- CPUs
- Intel
- Ivy Bridge
While compute functionality could technically be shoehorned into DirectX 10 GPUs such as Sandy Bridge through DirectCompute 4.x, neither Intel nor AMD's DX10 GPUs were really meant for the task, and even NVIDIA's DX10 GPUs paled in comparison to what they've achieved with their DX11 generation GPUs. As a result Ivy Bridge is the first true compute capable GPU from Intel. This marks an interesting step in the evolution of Intel's GPUs, as originally projects such as Larrabee Prime were supposed to help Intel bring together CPU and GPU computing by creating an x86 based GPU. With Larrabee Prime canceled however, that task falls to the latest rendition of Intel's GPU architecture.
With Ivy Bridge Intel will be supporting both DirectCompute 5—which is dictated by DX11—but also the more general compute focused OpenCL 1.1. Intel has backed OpenCL development for some time and currently offers an OpenCL 1.1 runtime for their CPUs, however an OpenCL runtime for Ivy Bridge will not be available at launch. As a result Ivy Bridge is limited to DirectCompute for the time being, which limits just what kind of compute performance testing we can do with Ivy Bridge.
Our first compute benchmark comes from Civilization V, which uses DirectCompute 5 to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. And while games that use GPU compute functionality for texture decompression are still rare, it's becoming increasingly common as it's a practical way to pack textures in the most suitable manner for shipping rather than being limited to DX texture compression.
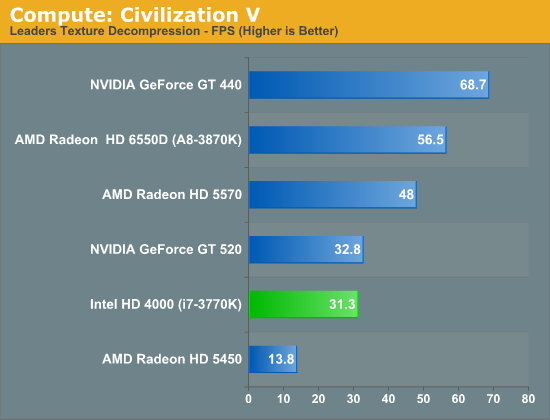
As we alluded to in our look at Civilization V's performance in game mode, Ivy Bridge ends up being compute limited here. It's well ahead of the even more DirectCompute anemic Radeon HD 5450 here—in spite of the fact that it can't take a lead in game mode—but it's slightly trailing the GT 520, which has a similar amount of compute performance on paper. This largely confirms what we know from the specs for HD 4000: it can pack a punch in pushing pixels, but given a shader heavy scenario it's going to have a great deal of trouble keeping up with Llano and its much greater shader performance.
But with that said, Ivy Bridge is still reaching 55% of Llano's performance here, thanks to AMD's overall lackluster DirectCompute performance on their pre-7000 series GPUs. As a result Ivy Bridge versus Llano isn't nearly as lop-sided as the paper specs tell us; Ivy Bridge won't be able to keep up in most situations, but in DirectCompute it isn't necessarily a goner.
And to prove that point, we have our second compute test: the Fluid Simulation Sample in the DirectX 11 SDK. This program simulates the motion and interactions of a 16k particle fluid using a compute shader, with a choice of several different algorithms. In this case we’re using an (O)n^2 nearest neighbor method that is optimized by using shared memory to cache data.

Thanks in large part to its new dedicated L3 graphics cache, Ivy Bridge does exceptionally well here. The framerate of this test is entirely arbitrary, but what isn't is the performance relative to other GPUs; Ivy Bridge is well within the territory of budget-level dGPUs such as the GT 430, Radeon HD 5570, and for the first time is ahead of Llano, taking a lead just shy of 10%. The fluid simulation sample is a very special case—most compute shaders won't be nearly this heavily reliant on shared memory performance—but it's the perfect showcase for Ivy Bridge's ideal performance scenario. Ultimately this is just as much a story of AMD losing due to poor DirectCompute performance as it is Intel winning due to a speedy L3 cache, but it shows what is possible. The big question now is what OpenCL performance is going to be like, since AMD's OpenCL performance doesn't have the same kind of handicaps as their DirectCompute performance.
Synthetic Performance
Moving on, we'll take a few moments to look at synthetic performance. Synthetic performance is a poor tool to rank GPUs—what really matters is the games—but by breaking down workloads into discrete tasks it can sometimes tell us things that we don't see in games.
Our first synthetic test is 3DMark Vantage’s pixel fill test. Typically this test is memory bandwidth bound as the nature of the test has the ROPs pushing as many pixels as possible with as little overhead as possible, which in turn shifts the bottleneck to memory bandwidth so long as there's enough ROP throughput in the first place.

It's interesting to note here that as DDR3 clockspeeds have crept up over time, IVB now has as much memory bandwidth as most entry-to-mainstream level video cards, where 128bit DDR3 is equally common. Or on a historical basis, at this point it's half as much bandwidth as powerhouse video cards of yesteryear such as the 256bit GDDR3 based GeForce 8800GT.
Altogether, with 29.6GB/sec of memory bandwidth available to Ivy Bridge with our DDR3-1866 memory, Ivy Bridge ends up being able to push more pxiels than Llano, more pixels than the entry-level dGPUs, and even more pixels the budget-level dGPUs such as GT 440 and Radeon HD 5570 which have just as much dedicated memory bandwidth. Or put in numbers, Ivy Bridge is pushing 42% more pixels than Sandy Bridge and 25% more pixels than the otherwise more powerful Llano. And since pixel fillrates are so memory bandwidth bound Intel's L3 cache is almost certainly once again playing a role here, however it's not clear to what extent that's the case.
Moving on, our second synthetic test is 3DMark Vantage’s texture fill test, which provides a simple FP16 texture throughput test. FP16 textures are still fairly rare, but it's a good look at worst case scenario texturing performance.

After Ivy Bridge's strong pixel fillrate performance, its texture fillrate brings us back down to earth. At this point performance is once again much closer to entry level GPUs, and also well behind Llano. Here we see that Intel's texture performance increases also exactly linearly with the increase in EUs from Sandy Bridge to Ivy Bridge, indicating that those texture units are being put to good use, but at the same time it means Ivy Bridge has a long way to go to catch Llano's texture performance, achieving only 47% of Llano's performance here. The good news for Intel here is that texture size (and thereby texel density) hasn't increased much over the past couple of years in most games, however the bad news is that we're finally starting to see that change as dGPUs get more VRAM.
Our final synthetic test is the set of settings we use with Microsoft’s Detail Tessellation sample program out of the DX11 SDK. Since IVB is the first Intel iGPU with tessellation capabilities, it will be interesting to see how well IVB does here, as IVB is going to be the de facto baseline for DX11+ games in the future. Ideally we want to have enough tessellation performance here so that tessellation can be used on a global level, allowing developers to efficiently simulate their worlds with fewer polygons while still using many polygons on the final render.


The results here are actually pretty decent. Compared to what we've seen with shader and texture performance, where Ivy Bridge is largely tied at the hip with the GT 520, at lower tessellation factors Ivy Bridge manages to clearly overcome both the GT 520 and the Radeon HD 5450. Per unit of compute performance, Intel looks to have more tessellation performance than AMD or NVIDIA, which means Intel is setting a pretty good baseline for tessellation performance. Tessellation performance at high tessellation factors does dip however, with Ivy Bridge giving up much of its performance lead over the entry-level dGPUs, but still managing to stay ahead of both of its competitors.








173 Comments
View All Comments
frozentundra123456 - Tuesday, April 24, 2012 - link
On the desktop, you are correct, especially if one overclocks. On the mobile front, IVB is a definite step up on the graphics front. My main reason for the responses to this thread was that it seemed premature for the original poster to imply that this site is being unfair to AMD/Trinity before we even know how much the improvement will be or read a review.iwod - Tuesday, April 24, 2012 - link
I read other press about 22nm 3D transistor as 11 years in the making. 11 years! Did anyone remember a article Anandtech posted a long time ago. It was about 3D transistors and Die Stacking. I did Google and Site search but could not find it. I cant record when was the article written but i was a long time. We have been waiting forever on these tech. We thought we wont see it for another 5 years.... and this is 11 years since then!Bit About Haswell Monster Graphics. Charlie also pointed towards CrystalWell, or a piece of silicon L4 SRAM Cache that is built for Graphics. Could Die Stacking be it, a piece of SRAM Cache on top or under?
I hope we do get more then 300% increase in performance. These way Ultrabook can really do get away with discrete graphics.
Well Ivy Bridge QuickSync wasn't as fast as we first thought. 7 min to transfer to iPad is fast, but what we want is sub 3 min. I.e the time transcode 1080P to portable format should be the same time to transfer 2.5 GB File from a USB 2.0 to iPad. Both Process should be happening in the same time. So when you "transfer" you are literally transcoding on the fly.
JarredWalton - Tuesday, April 24, 2012 - link
I'd say most of the same things to you. If you think the 15% clock speed increase of the CPU in Llano MX chips will somehow magically translate into significantly faster GPU performance, you're dreaming. Best-case it would improve some titles 15%, but of the 15 games I tested I can already tell you that CPU speed won't matter in over half of them--the HD 6620G isn't fast enough to use a more powerful CPU. The 10W TDP difference only matters for CPU performance, not the GPU performance, as the CPU clocks change but the GPU clocks don't.JarredWalton - Tuesday, April 24, 2012 - link
No, I think they're equal because these are the parts that are being sold, and they perform roughly the same. Actually, I think that the laptops most people buy with Llano are actually WORSE than Ivy Bridge's HD 4000, because what most people are buying with Llano is the cheap A6 chips, but that's not what we compared.But let's just say that we add DDR3-1600 memory to Llano, and we test with 8GB RAM. (Again, if you think 8GB actually helps in gaming performance, you don't understand technology.) Let's also say that every single game is CPU limited on Llano for kicks. With an MX chip in our hypothetical laptop, the best Llano would d would be to average 15% faster than HD 4000.
That's meaningless. It's the difference between 35FPS and 40FPS in a game, or 30FPS and 26FPS. Congratulations: you GPU might be 15% faster on average buy your CPU is half the speed. That's not a "win" for AMD.
Here's the facts: What was a gap of 50% with mobile Sandy Bridge vs. mobile Llano is now less than 5% on average. AMD has better drivers, but Intel is closing the gap. Trinity will improve GPU performance, and likely do very little for CPU performance. The end.
Riek - Tuesday, April 24, 2012 - link
Hi Anand & Ryan,Would it be possible to use one type of comparison through the pages?
Currently there are pages 'A8 is xx%faster than IvB' and their are pages ivyB trails A8 performance by .. or something similar.
My assumption is (since english is not my native language):
Trailing by 55% means that a A8 122% faster or vice versa. (e.g. it is is 55%slower than the A8)
Achieving 55% of the A8 means that A8 is 81% faster (e.g. it has 55% of the A8 score. if A8 scores 100, it scores 55).
Would great if the reader knows which one you use an can stick by it instead of having to recalculate it after they read every sentence twice. (and assume the understanding of the sentence is correct). I believe the general use would be part A is x% faster than part B or use the 2600K as a baseline and calculate all others as faster than compared to it.
JarredWalton - Tuesday, April 24, 2012 - link
I'll bet you $100 I can put 8GB RAM in the Llano laptop and it won't change any of the benchmark results by more than 2%. If I swap out the RAM for DDR3-1600, it will potentially increase gaming performance in a few titles by 5-10%, but that's about it.Anand's testing on the desktop showed that DDR3-1600 improved performance on the A8-3850 by around 12-14%, but the A8-3850 also has the 400 cores clocked 35% higher and can thus make better use of additional memory bandwidth. It's similar to DDR3-1866 vs. DDR3-1600 on desktop; the 17% increase in RAM speed only delivers an additional 6%, because the 600MHz HD 6550D cores are the bottleneck at that point. For laptops, the bottleneck is the cores a lot earlier; why do you think so many Llano laptops ship with DDR3-1333 still?
If you'd like to see someone's extensive testing (with a faster A8-3510MX chip even), here's a post that basically confirms everything I've said:
http://forum.notebookreview.com/gaming-software-gr...
BSMonitor - Wednesday, May 2, 2012 - link
Kudos Jarred on the professional way you handled that.Tough to argue with someone who doesn't base their arguments on facts, rather their impression/belief on how things work/perform.
Hrel - Tuesday, April 24, 2012 - link
If I have Ivy Bridge on the desktop, and have my monitor plugged into a dedicated GPU can I still use Quick Sync?Or do I still have to plug the monitor into the motherboard and be using integrated graphics?
Frankly quick sync is useless on the desktop if it doesn't work with a GTX560.
elkatarro - Tuesday, April 24, 2012 - link
Why the hell can't you see that comparing i7 3770K with 3,5 GHz to i7 2600K which runs at 3,4 GHz is POINTLESS?! Pretty much every other site got that point and used 2700K. Sure the 3770K will be faster than 2600K, duh...S20802 - Tuesday, April 24, 2012 - link
32 -> 22 nm, transistor dimension reduced by 31%,75% of die size, 20 % increase in transistor count. This means for the same die size there will be an increase of transistor count by 26%.
Projection
22 -> 14 nm, transistor dimension reduced by 36%.
Applying similar pattern we may get roughly 30% gain in transitor count.
However the gain may be lesser since the gain in IVB could have been due to 3D transistor tech.
So at best 30% and worst around 24% just for the decrease in transistor dimension.
This is by no means a precise calculation taking all factors into consideration.
Assuming the 14nm plant under construction goes online in 2013 with 450mm wafers, we can predict something like below
Transistor Count - nm - Die Size - Wafer Size - Dies/Wafer - Plant Capacity [Wafers/Month] - Plant Efficiency [%] - Yield [%] - Total Plants - Processors/Month
1.4B 22 160 300 441.9642857 50000 75 50 3 24,860,491.07
1.8B 14 160 450 994.4196429 50000 75 50 1 18,645,368.30
A staggering 18 Million working dies per month with 1.8B transistors at 160 mm2, with plant capacity of 50000 wafers/month, plant efficiency 75% and yield 50%, with 1 plant
Lets not forget the partly defective dies will be fused off to become some low end part which means the yield could touch 60%, taking the working dies to 22 Millions per month!!
This means Intel is going to make really cheap processors. 450mm wafer + 14nm = Game changer. Of course the fab is super expensive. But from what came out from Intel those first few batches of chips are paying for the ramp up to 22nm.
For an ultra mobile processor like Atom, in 2014, even a massive redesign of chip would still keep it well under 100 mm2. At 100 mm2, an Atom in 2014 will have ~1B transistors!!! Take that ARM.
My faith in Intel is rekindled. :-). AMD needs to be around to shove Intel whenever it gets too lazy. ARM is now helping AMD too in shoving Intel.