The Xeon E5-2600: Dual Sandy Bridge for Servers
by Johan De Gelas on March 6, 2012 9:27 AM EST- Posted in
- IT Computing
- Virtualization
- Xeon
- Opteron
- Cloud Computing
Intel's Sandy Bridge architecture was introduced to desktop users more than a year ago. Server parts however have been much slower to arrive, as it has taken Intel that long to transpose this new engine into a Xeon processor. Although the core architecture is the same, the system architecture is significantly different from the LGA-1155 CPUs, making this CPU quite a challenge, even for Intel. Completing their work late last year, Intel first introduced the resulting design as the six-core high-end Sandy Bridge-E desktop CPU, and since then have been preparing SNB-E for use in Xeon processors. This has taken a few more months but Xeon users' waits are at an end at last, as today Intel is launching their first SNB-E based Xeons .
Compared to its predecessor, the Xeon X5600, the Xeon E5-2600 offers a number of improvements:
A completely improved core, as described here in Anand's article. For example, the µop cache lowers the pressure on the decoding stages and lowers power consumption, killing two birds with one stone. Other core improvements include an improved branch prediction unit and a more efficient Out-of-Order backend with larger buffers.
A vastly improved Turbo 2.0. The CPU can briefly go beyond the TDP limits, and when returning to the TDP limit, the CPU can sustain higher "steady-state" clockspeed. According to Intel, enabling turbo allows the Xeon E5 to perform 14% better in the SAP S&D 2 tier test. This compares well with the Turbo inside the Xeon 5600 which could only boost performance by 4% in the SAP benchmark.
Support for AVX Instructions combined with doubling the load bandwidth should allow the Xeon to double the peak floating point performance compared to the Xeon "Westmere" 5600.

A bi-directional 32 byte ring interconnect that connects the 8 cores, the L3-cache, the QPI agent and the integrated memory controller. The ring replaces the individual wires from each core to the L3-cache. One of the advantages is that the wiring to the L3-cache can be simplified and it is easier to make the bandwidth scale with the number of cores. The disadvantage is that the latency is variable: it depends on how many hops a certain piece of data inside the L3-cache must cross before ends up at the right core.
A faster QPI: revision 1.1, which delivers up to 8 GT/s instead of 6.4 GT/s (Westmere).
Lower latency to PCI-e devices. Intel integrated a PCIe 3.0 I/O subsystem inside the die which sits on the same bi-directional 32 bit ring as the cores. PCIe 3.0 runs at 8 GT/s (PCIe 2.0: 5 GT/s), but the encoding has less overhead. As a result, PCIe 3.0 can deliver up to 1 GB full duplex per second per lane, which is twice as much as PCIe 2.0.
Removing the I/O lowered PCIe latency by 25% on average according to Intel. If you only access the local memory, Intel measured 32% lower read latency.
The access latency to PCIe I/O devices is not only significantly lower, but Intel's Data Direct I/O Technology allows the PCIe NICs to read and write directly to the L3-cache instead of to the main memory. In extremely bandwidth constrained situations (using 4 infiniband controllers or similar), this lowers power consumption and reduces latency by another 18%, which is a boon to HPC users with 10G Ethernet or Infiniband NICs.
The new Xeon also supports faster DDR-3 1600, up to 2 DIMMs per channel can run at 1600 MHz.
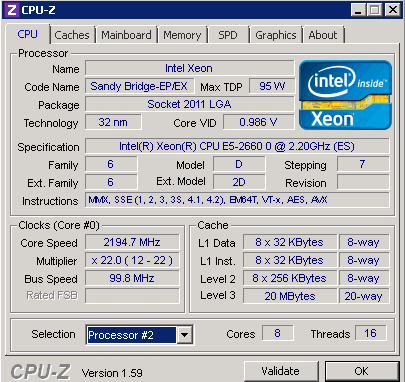
Last but certainly not least: 2 additional cores and up to 66% more L3 cache (20 MB instead of 12 MB). Even with 8 cores and a PCIe agent (40 lanes), the Xeon E5 still runs at 2.2 GHz within a 95W TDP power envelope. Pretty impressive when compared with both the Opteron 6200 and Xeon 5600.








81 Comments
View All Comments
think-ITB-live-OTB - Tuesday, March 6, 2012 - link
Can i ask you a question? do you at least get paid when you bend over for Intel?These are Server Chips - who cares about single-threaded application performance.. or Corporate IPOs. AMD has delivered far greater TCO/performance than Intel has for at least a Decade and running.
You want to praise a company like a Deity? ARM Holdings. nuff said. They can design a 35 dollar computer that can decode H.264 better than Intel can on SoCs that run 4x's the price. Currently have more Chips in more devices than in Intels entire history and Push Power envelopes far beyond anything Intel could ever muster.
Just you wait before the Storm ARM and its Licensees unleash as it will eventually take over ALL markets including the Server space (Calxeda much?). Oh and as for Apple. (an ARM Licensee itself... i can see them moving to in-house ARM designs pretty soon). 4-6-8 Core Cortex A15 (with A7 core for low power iPod/tablet sync) Macbook Airs anyone?
Intel is becoming the strongest of the Dinosaurs. But even the T-Rex fell eventually.
swizeus - Wednesday, March 7, 2012 - link
We have been using the Flemish/Dutch Web 2.0 website Nieuws.be as a benchmark for some time. 99% of the loads on the database are selects and about 5% of them are stored procedures.The database is loaded 104%. is it possible ?
JohanAnandtech - Wednesday, March 7, 2012 - link
Stored procedures can contain selects :-)fredisdead - Saturday, April 7, 2012 - link
From the 'article' .....'The Opteron might also have a role in the low end, price sensitive HPC market, where it still performs very well. It won't have much of chance in the high end clustered one as Intel has the faster and more power efficient PCIe interface'
Well, if that's the case, why exactly would AMD be scoring so many design wins with Interlagos. Including this one ...
http://www.pcmag.com/article2/0,2817,2394515,00.as...
http://www.eweek.com/c/a/IT-Infrastructure/Cray-Ti...
U think those guys at Cray were going for low performance ? In fact, seems like AMD has being rather cleaning up in the HPC market since the arrival of Interlagos. And the markets have picked up on it, AMD stock is thru the roof since the start of the year. Or just see how many Intel processors occupy the the top 10 supercomputers on the planet. Nuff said ...
InsaneScientist - Wednesday, March 7, 2012 - link
Johan, where in the specs where you have this line:Transistors (Billion) 2,26 2x 1,2 2x 904 1,17
I sure hope that 2x 904 (Billion) is a typo... otherwise AMD has some serious explaining to do. ;)
Should be 2x ,904 (I think? Would be 2x .904 for me, I assume you follow the same rules...)
iliev - Wednesday, March 7, 2012 - link
Page 5, Benchmark ConfigurationR2208GZ4GSSPP specs table... E5-2660 is 2.2Ghz, and not 2.9GHz
dodge776 - Wednesday, March 7, 2012 - link
Hi Johan,Always look forward to reading your server reviews at AT, but no SAPS benchmarks this time?
ppennisi - Wednesday, March 7, 2012 - link
For maximum VMware performance on Opteron Interlagos cpu under VMWARE it's better to disable C1E and enable, where available, HPC mode.I found myself on a fresh installation of ESXi 5.0 on Dell R715 that leaving C1E enable literally crippled vm performance.
boudini - Thursday, March 8, 2012 - link
I'm not sure I would recommend using iray as a reliable benchmark renderer in 3ds max. It is not a self configuring mental ray, but an unbiased renderer which behaves fairly differently to mental ray, and most other renderers such as vray, final render and brazil. It is comparible to maxwell and fryrender, but is very new compared to those two longer established unbiased render engines. It also attempts to use the gpu to add to its calculations as well - which could significantly skew results.Using mental ray or vray might well give you quite a different result, and besides I don't think iray is widely used in the industry.
omega4711 - Friday, March 9, 2012 - link
This. The results of iray are mostly dependent on the GPU. The lack of proper scaling certainly isn't due to Amdahl's law. Just use mentalray with small enough render buckets and you can easily satisfy 64+ threads.Also, due to the limitations of iray, it can (at this moment) only be used in about 1-3% of real world scenarios.
Please, for all the people that care about these benchmarks, use mentalray and/or vray.
Otherwise, it's a brilliant article.