The Xeon E5-2600: Dual Sandy Bridge for Servers
by Johan De Gelas on March 6, 2012 9:27 AM EST- Posted in
- IT Computing
- Virtualization
- Xeon
- Opteron
- Cloud Computing
Rendering Performance: Cinebench
Cinebench, based on MAXON's CINEMA 4D software, is probably one of the most popular benchmarks around as it is pretty easy to perform this benchmark on your own home machine. The benchmark supports 64 threads, more than enough for our 24- and 32-thread test servers. First we tested single-threaded performance, to evaluate the performance of each core.
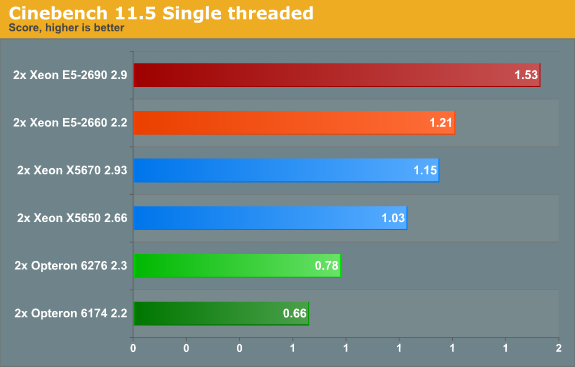
Cinebench achieves an IPC between 1.4 and 1.8 and is mostly dominated by SSE2 code. The Sandy Bridge core offers about 33% better single-threaded SSE performance. We checked: the 33% can be split up into 21% gains from architectural improvements and 12% from the improved Turbo capabilities.
Let's check out the multi-threaded score.
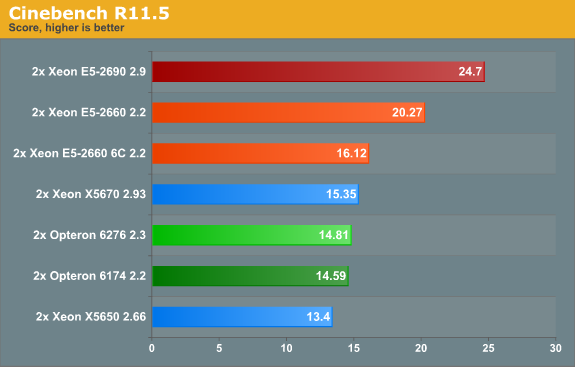
Prior to the launch of the Xeon E5 series, the Opteron 6276 offered a better performance per dollar ratio than comparable Xeon 5600s due to their similar performance at a much lower pricepoint. Now that the Xeon E5 has arrived, the tables have turned. If Xeon E5 servers are in the same price range as Xeon 5600 servers, the Xeon E5-2630 will offer the best performance/price ratio.
And if you want top performance, Intel is the only option. Case in point: a dual Xeon E5-2690 comes close to what a Quad Opteron 6276 can deliver, with the dual Xeon scoring 24.7 while the quad Opteron scores 26.4.








81 Comments
View All Comments
JohanAnandtech - Wednesday, March 7, 2012 - link
Argh. You are absolutely right. I reversed all divisions. I am fixing this as we type. Luckily this does not alter the conclusion: LS-DYNA does not scale with clockspeed very well.alpha754293 - Wednesday, March 7, 2012 - link
I think that I might have an answer for you as to why it might not scale well with clock speed.When you start a multiprocessor LS-DYNA run, it goes through a stage where it decomposes the problem (through a process called recursive coordinate bisection (RCB)).
This decomposition phase is done every time you start the run, and it only runs on a single processor/core. So, suppose that you have a dual-socket server where the processors say...are hitting 4 GHz. That can potentially be faster than say if you had a four-socket server, but each of the processors are only 2.4 GHz.
In the first case, you have a small number of really fast cores (and so it will decompose the domain very quickly), whereas in the latter, you have a large number of much slower cores, so the decomposition will happen slowly, but it MIGHT be able to solve the rest of it slightly faster (to make up for the difference) just because you're throwing more hardware at it.
Here's where you can do a little more experimenting if you like.
Using the pfile (command line option/flag 'p=file'), not only can you control the decomposition method, but you can also tell it to write the decomposition to a file.
So had you had more time, what I would have probably done is written out the decompositions for all of the various permutations you're going to be running. (n-cores, m-number of files.)
When you start the run, instead of it having to decompose the problem over and over again each time it starts, you just use the decomposition that it's already done (once) and then that way, you would only be testing PURELY the solving part of the run, rather than from beginning to end. (That isn't to say that the results you've got is bad - it's good data), but that should help to take more variables out of the equation when it comes to why it doesn't scale well with clock speed. (It should).
IntelUser2000 - Tuesday, March 6, 2012 - link
Please refrain from creating flamebait in your posts. Your post is almost like spam, almost no useful information is there. If you are going to love one side, don't hate the other.Alexko - Tuesday, March 6, 2012 - link
It's not "like spam", it's just plain spam at this point. A little ban + mass delete combo seems to be in order, just to cleanup this thread—and probably others.ultimav - Wednesday, March 7, 2012 - link
My troll meter is reading off the charts with this guy. Reading between the lines, he's actually a hardcore AMD fan trying to come across as the Intel version of Sharikou to paint Intel fans in a bad light. Pretty obvious actually.JohanAnandtech - Wednesday, March 7, 2012 - link
We had to mass delete his posts as they indeed did not contain any useful info and were full of insults. The signal to noise ratio has been good the last years, so we must keep it that way.Inteluser2000, Alexko, Ultimav, tipoo: thx for helping to keep the tone civil here. Appreciate it.
- Johan.
tipoo - Wednesday, March 7, 2012 - link
And thank you for removing that stuff.tipoo - Tuesday, March 6, 2012 - link
We get it. Don't spam the whole place with the same post.tipoo - Tuesday, March 6, 2012 - link
No, he's just a rational persons. I don't care which company you like, if you say the same thing 10 times in one article someones sure to get annoyed and with justification.MySchizoBuddy - Tuesday, March 6, 2012 - link
I'm again requesting that when you do the benchmarks please do a Performance per watt metric along with stress testing by running folding@home for straight 48hours.