The Xeon E5-2600: Dual Sandy Bridge for Servers
by Johan De Gelas on March 6, 2012 9:27 AM EST- Posted in
- IT Computing
- Virtualization
- Xeon
- Opteron
- Cloud Computing
Rendering: Blender 2.6.0
Blender is a very popular open source renderer with a large and active community. We tested the 64-bit Windows edition, using version 2.6.0a. If you like, you can perform this benchmark very easily too. We used the metallic robot, a scene with rather complex lighting (reflections) and raytracing. Furthermore to make the benchmark more repetitive, we changed the following parameters:
- The resolution was set to 2560x1600
- Antialiasing was set to 16
- We disabled compositing in post processing
- Tiles were set to 16x16 (X=16, Y=16)
- Threads was set to auto (one thread per CPU is set).
As we have explained, the current 24 and 32 core CPUs benefit from using a much larger number of tiles than we have previously used (64, 8x8). That is why we raised the number of tiles to 256 (16x16), though all CPUs perform better at this setting.
To make the results easier to read, we again converted the reported render time into images rendered per hour, so higher is better.
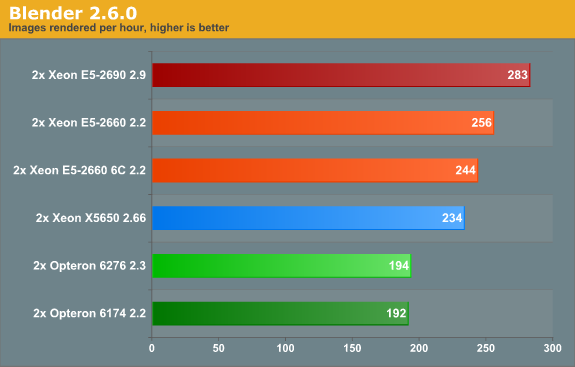
Blender is Xeon territory for sure, as Blender mostly runs in the L1 and L2 cache. Therefore a E5-2630 (2.3 GHz, 15 MB L3, $612) will probably perform about 4% faster than the six-core Xeon E5-2660 in this test. Our six-core Xeon E5-2660 is about 26% faster than the best Opteron. We estimate that the Xeon E5-2630 will offer more or less the same performance at an almost 30% lower pricepoint than the Opteron 6276. Whether you have a lot or little to spend, the Xeon E5 is your best bet for Blender.
Rendering Performance: 3DSMax 2012
As requested, we're reintroducing our 3DS Max benchmark. We used the "architecture" scene which is included in the SPEC APC 3DS Max test. As the Scanline renderer is limited to 16 threads, we're using the iray render engine, which is basically an self-configuring Mental Ray render engine.

We rendered at 720p (1280x720) resolution. We measured the time it takes to render 10 frames (from 20 to 29) with SSE enabled. We recorded the time and then calculated (3600 seconds * 10 frames / time recorded) how many frames a certain CPU configuration could render in one hour. All results are reported as rendered images per hour; higher is thus better. We used the 64-bit version of 3ds Max 2008 on 64-bit Windows 2008 R2 SP1.
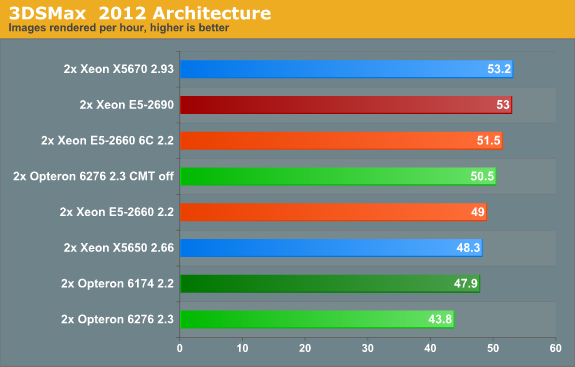
Even with the advanced iray renderer, 3DS Max rendering reaches our scaling limits. The 32-thread Xeons do not come close to 100% CPU load (more like 90%) and in between the frames there are small periods of single threaded processing. Amdahl's law is most likely reason here. We suspect that highly clocked lower core count models can pass the 53 fps barrier we're seeing here.








81 Comments
View All Comments
BSMonitor - Tuesday, March 6, 2012 - link
My question as well.What is the Intel roadmap for Ivy Bridge in this arena. Would be the same timeframe as IVB-E I would guess.
Wondering if my Intel dividends will pile up enough for me to afford one! Haha
devdeepc - Friday, September 2, 2016 - link
Based on the paper specs, AMD's 6276, 6274 and Intel's 2640 and 2630 are in a neck-and-neck race.fredisdead - Saturday, April 7, 2012 - link
From the 'article' .....'The Opteron might also have a role in the low end, price sensitive HPC market, where it still performs very well. It won't have much of chance in the high end clustered one as Intel has the faster and more power efficient PCIe interface'
Well, if that's the case, why exactly would AMD be scoring so many design wins with Interlagos. Including this one ...
http://www.pcmag.com/article2/0,2817,2394515,00.as...
http://www.eweek.com/c/a/IT-Infrastructure/Cray-Ti...
U think those guys at Cray were going for low performance ? In fact, seems like AMD has being rather cleaning up in the HPC market since the arrival of Interlagos. And the markets have picked up on it, AMD stock is thru the roof since the start of the year. Or just see how many Intel processors occupy the the top 10 supercomputers on the planet. Nuff said ...
iwod - Tuesday, March 6, 2012 - link
And not find a single comment on how and why "making this CPU quite a challenge, even for Intel."In my view It seems Intel is now using Server Market and Atom / SoC for their 32nm capacity when ever they introduce a new node in consumer products.
extide - Tuesday, March 6, 2012 - link
A large part of Intel's long-term strategies include keeping the fabs occupied.Latest gen fabs (currently 22nm) produce bleeding edge cpu's, usually in the consumer space
One gen back (32nm) produces server/workstation/mobile cpus
two gens back (45nm) produces other things like chipsets, and possibly itanium chips
even three gens back (65nm) probably still exists in some places making some chipsets as well.
Their goal is to as much use as possible from their investment into building the fabs themselves.
Kevin G - Tuesday, March 6, 2012 - link
65 nm is still used for Itanium, though the Poulson chip is due sometime this year made on a 32 nm process. If you want to compare die sizes, the 65 nm Tukwila design is 699 mm^2 in size.The main reason why 32 nm Sandybridge-E has been released so close to the release of 22 nm Ivy Bridge chips is that the initial Ivy Bridge chips are consumer centric. Intel performs additional testing on its server centric designs. This is particularly true as Sandybridge-E is not just replacing the dual socket Westmere-EP chips but some of the quad socket Westmere-EX market. RAS demands jump from going from dual to quad socket and that is reflected in additional testing. Implementing PCI-E 3.0 and QPI 1.1 also contributed to the time for additional testing.
Though you are correct that Intel does uses its older process nodes for various chipsets and IO chips. However, as Intel is marching toward SoC designs, the actual utility of keeping these older process nodes in action is decreasing.
meloz - Tuesday, March 6, 2012 - link
>And not find a single comment on how and why "making this CPU quite a challenge, even for Intel."Because it is such a massive die? 416 mm²? Large dies usually have a lower yield, and Intel's 32 nm process is still cutting edge (if only for a few more weeks, heh).
Look at how TSMC, Global Flounderings et al are struggling. An impressive achievement by Intel.
MrSpadge - Tuesday, March 6, 2012 - link
A significant amount of functionality has been added to the SB cores, and Intel can't afford mistakes in such CPUs.BSMonitor - Tuesday, March 6, 2012 - link
More than that though, the SNB-E, Xeon E cores are not duplicates of the SNB desktop cores.Look at Anand's die shot of SNB-E, vs die shot of SNB. The CPU cores, L3 cache, controllers, are arranged completely different. Which makes sense as SNB-E doesn't have to deal with 40% of the die being GPU transistors. So, what we have now with Intel is two completely different dies between Xeon/SNB-E and Core. The individual CPU cores are the same, but the rest of the die is completely different.
SNB-E:
http://www.anandtech.com/show/5091/intel-core-i7-3...
SNB:
http://www.anandtech.com/show/4083/the-sandy-bridg...
cynic783 - Tuesday, March 6, 2012 - link
omg these benches are so biased it's not even funny. everyone knows amd offers clock-for-clock more punch than intel and lower power as well