Intel's Medfield & Atom Z2460 Arrive for Smartphones: It's Finally Here
by Anand Lal Shimpi on January 10, 2012 8:00 PM ESTThe CPU
Medfield is the platform, Penwell is the SoC and the CPU inside Penwell is codenamed Saltwell. It's honestly not much different than the Bonnell core used in the original Atom, although it does have some tweaks for both power and performance.
Almost five years ago I wrote a piece on the architecture of Intel's Atom. Luckily (for me, not Intel), Atom's architecture hasn't really changed over the years so you can still look back at that article and have a good idea of what is at the core of Medfield/Penwell. Atom is still a dual-issue, in-order architecture with Hyper Threading support. The integer pipeline is sixteen stages long, significantly deeper than the Cortex A9's. The longer pipeline was introduced to help reduce Atom's power consumption by lengthening some of the decode stages and increasing cache latency to avoid burning through the core's power budget. Atom's architects, similar to those who worked on Nehalem, had the same 2:1 mandate: every new feature added to the processor's design had to deliver at least a 2% increase in performance for every 1% increase in power consumption.
Atom is a very narrow core as the diagram below will show:
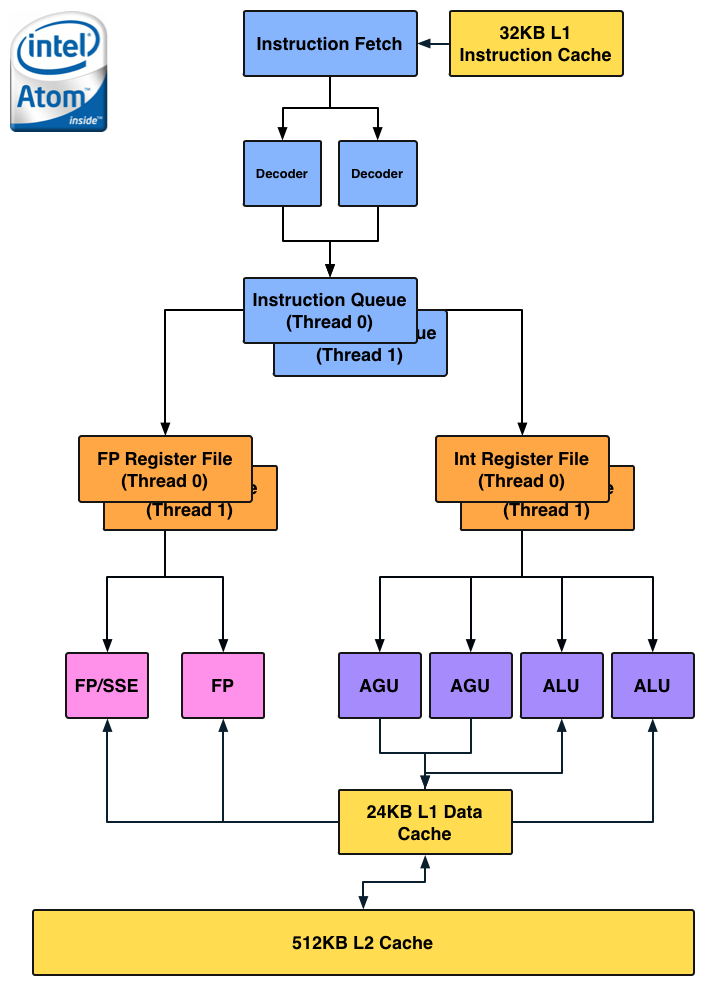
There are no dedicated integer multiply or divide units, that's all shared with the FP hardware. Intel duplicated some resources (e.g. register files, queues) to enable Hyper Threading support, but stopped short of increasing execution hardware to drive up efficiency. The tradeoff seems to have worked because Intel is able to deliver performance better than a dual-core Cortex A9 from a single HT enabled core. Intel also lucks out because while Android is very well threaded, not all tasks will continually peg both cores in a dual-core A9 machine. At higher clock speeds (1.5GHz+) and with heavy multi-threaded workloads, it's possible that a dual-core Cortex A9 could outperform (or at least equal) Medfield but I don't believe that's a realistic scenario.
Architecturally the Cortex A9 doesn't look very different from Atom:
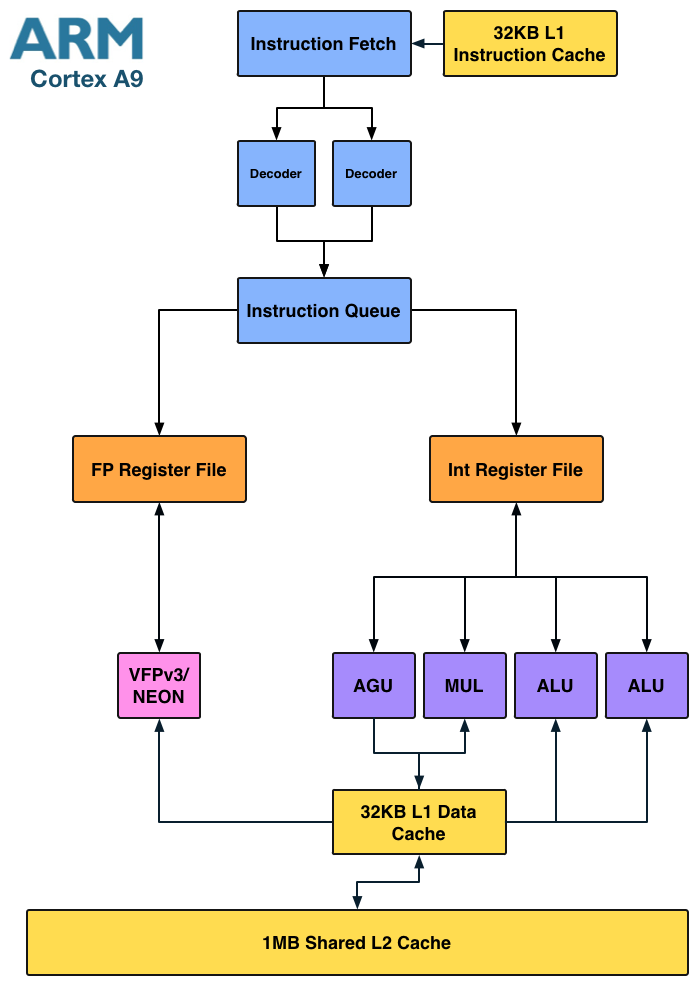
Here we see a dedicated integer multiply unit (shared with one of the ALU ports) but only a single port for FP/NEON. It's clear that the difference between Atom and the Cortex A9 isn't as obvious at the high level. Instead it's the lower level architectural decisions that gives Intel a performance advantage.
Where Intel is in trouble is if you look at the Cortex A15:
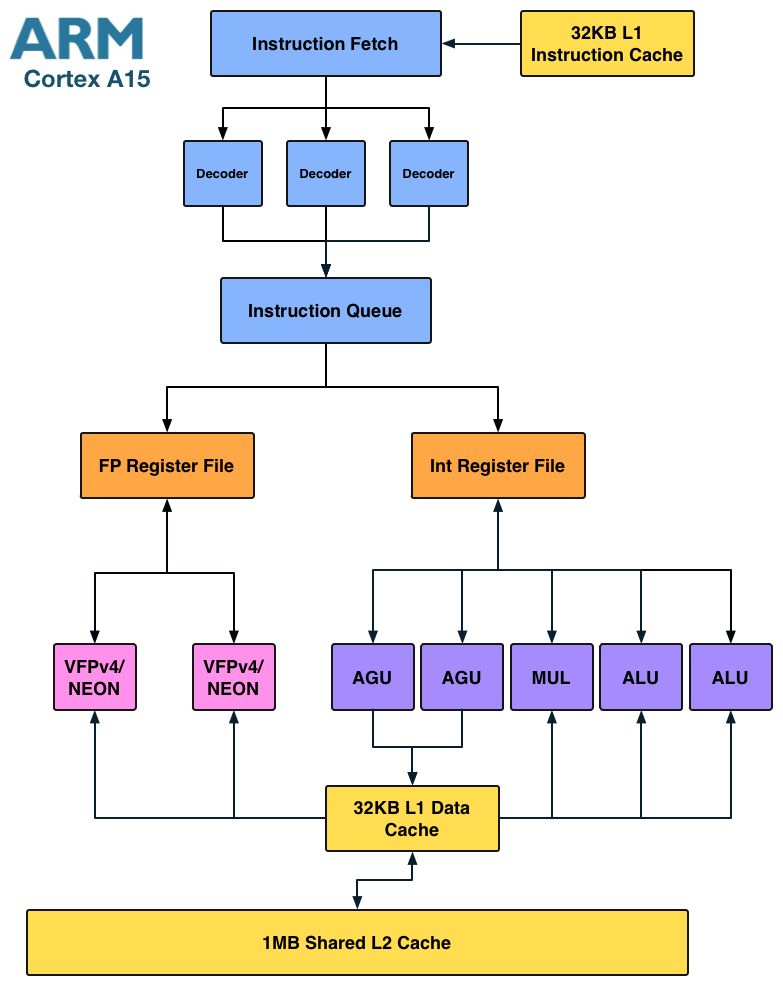
The A15 is a far more modern design, also out of order but much wider than A9. I fully expect that something A15-class can outperform Medfield, especially if the former is in a dual-core configuration. Krait falls under the A15-class umbrella so I believe Medfield has the potential to lose its CPU performance advantage within a couple of quarters.
Enhancements in Saltwell
Although the CPU core is mated to a 512KB L2 cache, there's a separate 256KB low power SRAM that runs on its own voltage plane. This ULP SRAM holds CPU state and data from the L2 cache when the CPU is power gated in the deepest sleep state. The reasoning for the separate voltage plane is simple. Intel's architects found that the minimum voltage for the core was limited by Vmin for the ULP SRAM. By putting the two on separate voltage planes it allowed Intel to bring the CPU core down to a lower minimum power state as Vmin for the L2 is higher than it is for the CPU core itself. The downside to multiple power islands is an increase in die area. Since Medfield is built on Intel's 32nm LP process while the company transitions to 22nm, spending a little more on die area to build more power efficient SoCs isn't such a big deal. Furthermore, Intel is used to building much larger chips, making Medfield's size a relative nonissue for the company.
The die size is actually very telling as it's a larger SoC than a Tegra 2 with two Cortex A9s despite only featuring a single core. Granted the rest of the blocks around the core are different, but it goes to show you that the CPU core itself (or number of cores) isn't the only determination of the die size of an SoC.
The performance tweaks come from the usual learnings that take place over the course of any architecture's lifespan. Some instruction scheduling restrictions have been lifted, memory copy performance is up, branch predictor size increased and some microcode flows run faster on Saltwell now.
Clock Speeds & Turbo
Medfield's CPU core supports several different operating frequencies and power modes. At the lowest level is its C6 state. Here the core and L2 cache are both power gated with their state is saved off in a lower power on-die SRAM. Total power consumption in C6 of the processor island is effectively zero. This isn't anything new, Intel has implemented similar technologies in desktops since 2008 (Nehalem) and notebooks since 2010 (Arrandale).
When the CPU is actually awake and doing something however it has a range of available frequencies: 100MHz all the way up to 1.6GHz in 100MHz increments.
The 1.6GHz state is a burst state and shouldn't be sustained for long periods of time, similar to how Turbo Boost works on Sandy Bridge desktop/notebook CPUs. The default maximum clock speed is 1.3GHz, although just as is the case with Turbo enabled desktop chips, you can expect to see frequencies greater than 1.3GHz on a fairly regular basis.
Power consumption along the curve is all very reasonable:
| Medfield CPU Frequency vs. Power | ||||||
| 100MHz | 600MHz | 1.3GHz | 1.6GHz | |||
| SoC Power Consumption | ~50mW | ~175mW | ~500mW | ~750mW | ||
Since most ARM based SoCs draw somewhere below 1W under full load, these numbers seem to put Medfield in line with its ARM competitors - at least on the CPU side.
It's important to pay attention to the fact that we're dealing with similar clock frequencies to what other Cortex A9 vendors are currently shipping. Any performance advantages will either be due to Medfield boosting up to 1.6GHz for short periods of time, inherently higher IPC and/or a superior cache/memory interface.








164 Comments
View All Comments
french toast - Wednesday, January 18, 2012 - link
Yea dont tell us you have never heard of intel anti competitive practises?? hell they have already been fined billions of $ for it.jaffa62 - Wednesday, May 16, 2012 - link
Typical smartphone malware leverages platform vulnerabilities that allow it to gain root access on the device in the background. Using this access the malware installs additional software to target communications, location, or other personal identifying information. Thanks.Regards,
http://www.scottsdale-azsearchforhomes.com/scottsd...
ltcommanderdata - Tuesday, January 10, 2012 - link
So Intel has switched from the DirectX compliant SGX535 to the OpenGL ES only SGX540? Does this mean they have no plans to support Windows Phone or Windows with Medfield?In regards to the memory interface, many Cortex A9 implementations include a 64-bit memory controller just like Medfield. If Intel is saying Cortex A9 is still memory bandwidth limited does that mean that ARM memory controllers are currently inefficient? Would increasing L2 cache from the current 512KB per core Cortex A9 implementations be an effective way to mitigate this?
guilmon19 - Tuesday, January 10, 2012 - link
" Atom can support far more outstanding misses in L2 than the Cortex A9, which chokes bandwidth to the processor for anything not already in the L2 cache."It looks like its cache that is the problem and its more of a controller problem then the size of the cache itself, but increase the size of the cache would help, but it wouldn't be the most efficient solution.
wumpus - Wednesday, January 11, 2012 - link
The article implies that the core somehow handles it. Claiming that an in-order CPU can handle cache misses better than an out-of-order one has to be wrong. I wouldn't be surprised if the intel cache/memory controller is sufficiently better to cause these results.Exophase - Wednesday, January 11, 2012 - link
Those in-flight memory requests that miss L2 wouldn't be coming from the CPU instructions themselves but the hardware prefetcher. So being in-order doesn't stop it from making requests. Plus it has SMT.It wouldn't surprise me if Atom's auto prefetcher is better than Cortex-A9's. Intel has a lot more experience with them, this is the first one ARM has done. It also goes directly into L1 cache, while Cortex-A9's just goes into L2 (the core gives prefetch hints to the L2 controller), but it can load into L1 directly with manual prefetch instructions.
You can see some comparisons here:
http://www.7-cpu.com/cpu/Cortex-A9.html
http://www.7-cpu.com/cpu/Atom.html
L2 latency is higher on A9 due to being less tightly coupled and shared between two cores. Somewhat mitigated by being OoO and (usually) having more of it. L2 bandwidth is comparable. Other latencies are also comparable. Effective read bandwidth is a lot higher on Atom, while effective write bandwidth higher on this A9. I'm sure the former highlights the differences in L2 misses in flight Intel is talking about, while the latter highlights differences in store queue depth.
I doubt bandwidth is going to be a key player for most benchmarks or you'd see Exynos and OMAP4 have a big advantage over Tegra 2 (it doesn't), not to say that it doesn't matter for GPU performance.
dethrophes - Wednesday, April 8, 2015 - link
Having worked with both, in my openion intel wins hands down.The arm paper specs look ok until you have to work with it,
Intel have an integrated cache solution. I always feel with arm cache that some guys just hacked together various components with gaffa tape. There are also so many errata with regard to the caches that a lot of the features such as the l2 prefetcher get disabled by default.
milli - Tuesday, January 10, 2012 - link
SGX535 = DX 9.0cSGX540 = DX 10.1
A CPU still needs to be able to take advantage of the available memory bandwidth (through technologies like prefetching, ...). A good example can be found in the desktop space between Intel and AMD, where Intel CPU's have much higher memory bandwidth (while both have similar theoretical bandwidth).
While increasing the L2 cache on an A9 SOC would mitigate this to some extend, don't expect wonders. It's also not very realistic ATM to have more than 1MB cache in a mobile SOC.
ltcommanderdata - Tuesday, January 10, 2012 - link
The SGX540 does not have DirectX support. In the Series5/5XT line, the DX compliant cores are:SGX535: DX9.0c
SGX544/554: DX9 level 3
SGX545: DX10.1
The SGX520/530/531/540/543 only support OpenGL ES 2.0 and not full DX compliance.
milli - Tuesday, January 10, 2012 - link
It seems you're right. Wikipedia is wrong about this.