The Opteron 6276: a closer look
by Johan De Gelas on February 9, 2012 6:00 AM EST- Posted in
- IT Computing
- CPUs
- Bulldozer
- AMD
- Opteron
- Cloud Computing
- Interlagos
SQL Server 2008 Enterprise R2
We have been using the Flemish/Dutch web 2.0 website Nieuws.be for some time. 99% of the loads on the database are selects and about 5% of them are stored procedures. You can find a more detailed description here.
We have improved our testing methodology and updated the SQL Server version, so the results are no longer comparable with previous results. We used to publish the highest throughput possible, but we have found that it is not entirely fair. At the highest throughput, there was a very small (<1%) percentage of connection errors (client side timeouts), but those timeouts could make the results vary by about 5-10%. A better configured .NET data provider improved this situation. We adapted the .Net data provider to support the same timeout as the MS SQL Server standard timeout (60s), and we now meticulously scan our logs for errors and discard all results that have any error rates.
Since turbo modes are disabled in the "Balanced" Power management policy and we want to evaluate both power and performance, we tested with both the "Balanced" and "High Performance" power management policies.
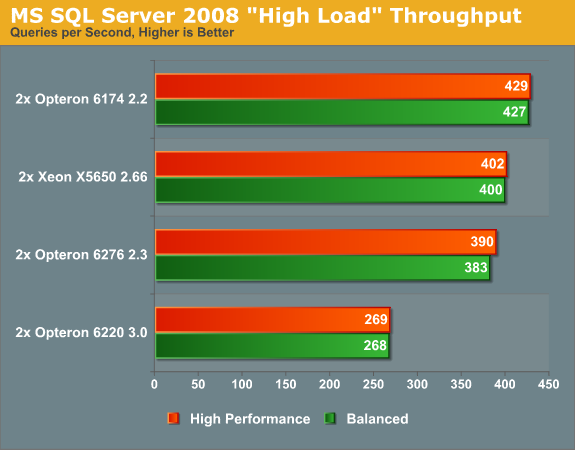
We have reported this before: when it comes to pure OLAP MS SQL server throughput, the Opteron Magny-Cours is unbeatable. Notice that both the Xeon and the new Opteron 6276 can hardly leverage Turbo (e.g. "High Performance" mode) even though both Intel and AMD talk about the potential to run at higher clockspeeds even when all cores are active. While this integer intensive workload comes nowhere close to consuming what a Linpack run would require, the TDP headroom is no longer there to enable a clockspeed boost.
Looking at the results, the Opteron 6276 disappoints somewhat as it is not capable of outperforming its older brother. However, it performs relatively close to the Xeon and is thus far from a dud.
At maximum CPU load, the response times paint a very similar picture as the throughput numbers:
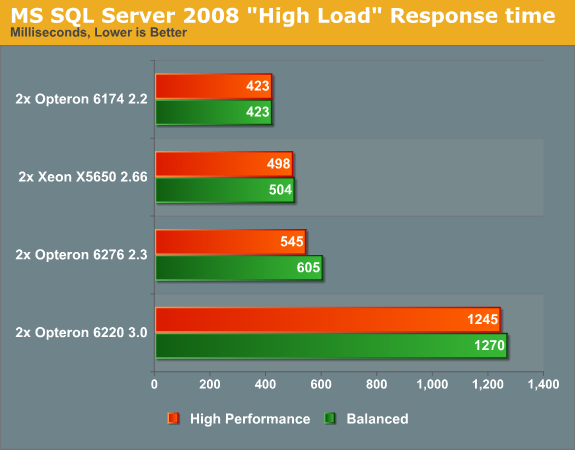
When we look at the response times, the Opteron 6174's leadership is confirmed and emphasized. The fact that a 16-cluster 2.3GHz Opteron offers 30% more throughput and twice as fast response times as its 8-cluster 3GHz brother is a clear testimony to the excellent scaling capabilities of SQL server.
Since performance/watt is an extremely important metric, we follow up with a power measurement:
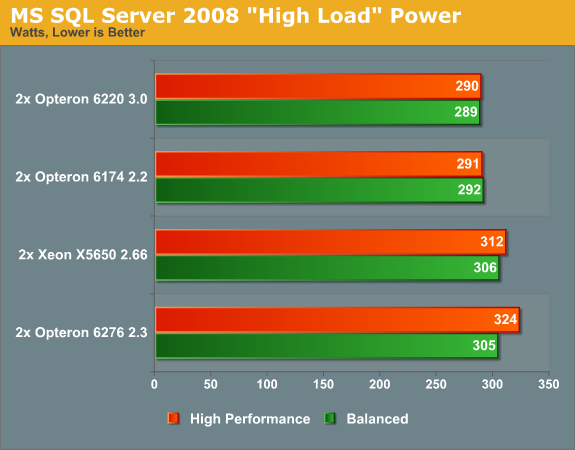
There's no doubt about it: the Opteron 6174 is the performance/watt champion in this particular task.
This is the classical way to evaluate server performance, but should you base your purchase on these numbers alone? Frankly, no. The 100% full load evaluation is incomplete, and it's not related to the real world way of using a database. It just shows what your servers can spit out when running at their maximum, a situation most people either try to avoid or never see as so many other bottlenecks (I/O, lock contention) kick in before you see 100% CPU utilization. It is the best method to evaluate HPC machines, but a short-sighted method for almost any server application (web, database, etc.).
In other words, server benchmarks at 100% are just one datapoint, but we should test at lower concurrencies as well. That is why we simulated 40, 80, 100, 125, 200, 300, 400, 600 and 800 users with our vApus stress testing client. Each user starts a query with between 900 and 1100 ms "thinking time" (so on average 1 second). At 600 and 800 users, our servers achieve their maximum throughput, but how do these servers handle "low" and "midrange" workloads? Let us see what happened when we tested with everyday "normal" loads.








46 Comments
View All Comments
Scali - Saturday, February 11, 2012 - link
"It also reduces throughput."No, it improves throughput, assuming we are talking from improvement going from 1 physical core to 2 logical cores.
Clearly two logical cores (on the same physical core) have less throughput than two physical cores, but that's obvious since you only have half the hardware.
And that, together with the fact that Intel's SMT chips have far better single-threaded performance to begin with, results in very good performance per die area (you know, that thing that people used to praise AMD GPUs for).
"Yes, it does, via the implementation of all that shared hardware on the chip."
You can't say that, since there is no non-modular version of Bulldozer (just as there is no non-HT version of the Intel architectures).
However, if you compare a 4-core HT architecture with a non-HT architecture, be that a Core2 Quad or a Phenom X4, Intel's transistorcount is clearly in the same ballpark, so HT does not add much in terms of transistorcount.
With CMT we see little or no indication of reduced transistorcount. AMD's 4-module chips are MUCH larger than regular 4-core chips have been. In fact, AMD"s 4-module design is even larger than Intel's 6-core design with HT.
"Two different approaches to the same idea."
I disagree. SMT is a very different idea from CMT (which is a bogus marketing term invented by AMD anyway). CMT is more of a marketing excuse for not having proper SMT, and shows no merit in actual silicon.
"but I don't think we can label one as inherently better than the other yet."
Well clearly we disagree on that then.
I think SMT is clearly inherently better than CMT. SMT has far more flexible sharing of resources than AMD's half-baked approach.
And any theoretical disadvantages (fighting over resources and all that) can be put to bed with benchmarking such as in this review: the disadvantages may exist, but the net performance is unbeatable anyway. A midrange Xeon schools a CMT-based chip of twice the size.
Andexxx - Wednesday, February 15, 2012 - link
Well, there are a lot of factors affecting single-threaded performance in real life. So CMT indeed has its scaling advantages as tests suggested. At least most of the things should be constant when comparing CMT-on and CMT-off, while comparing SMT and CMT on different implementations is not. Lack of single-threaded performance is not a valid point of blaming CMT.If you want to *proof* CMT is a half-baked marketing crap while SMT is the only solution, what you need is a SMT-based AMD BD monolithic core or a CMT-based Intel monolithic module for comparison.
For the transistors counting, well, that's their choice of making such a cache and uncore configuration. You can keep telling 4-module chip is blahblahblah, but in some cases it beats a 4C8T Xeon chips. Transistors is not a big matter from customer viewpoint but just the producer viewpoint. If you want to argue with GPU's performance metrics, GPU is a data-parallel processor with bunch of logic units, while CPU is a latency-sensitive girlfriend of caches. Large amount of cache can make your Performance/mm^2 or Performance/transistors look worse. So trade-offs on the amount of cache should have been done before they started to design the chip.
Scali - Wednesday, February 15, 2012 - link
Well, one of the reasons why AMD's current CPUs have such poor single-threaded performance is because they moved from 3 ALUs per thread to 2 ALUs per thread.This is part of the whole CMT design.
So in that sense, CMT can be blamed for the poor single-threaded performance at least.
And since single-threaded performance is so bad, it is only logical that scaling to more threads is relatively good.
On a CPU with faster single-threaded performance, you run into IO limits sooner (memory, disk etc), so it is more difficult to maintain similar scaling with increased thread count.
The strength of SMT is that Intel did not have to cut any ALUs when implementing HT. Pentium 4 Northwood with HT still had two double-pumped ALUs, like the non-HT Willamette that went before it.
Likewise, Core i7 still has 3 ALUs, like Core2.
Another strength of SMT is that even with one less ALU per 2 threads than CMT, it still reaches similar performance in multithreaded scenarios. CMT can not share these ALUs between threads, while SMT can.
Conclusion: CMT is nonsense.
For the full version, see: http://scalibq.wordpress.com/2012/02/14/the-myth-o...
slycer.tech - Monday, February 13, 2012 - link
If Bulldozer arc really bad, how about this?http://www.marketwatch.com/story/amd-opterontm-620...
Can someone prove this award is a big liar?
duploxxx - Tuesday, February 14, 2012 - link
read the article, the baseline they use for price/performance is based on spec results....lots of companies still use these results to decide on a platform.but then again, benchmarks don't always show the real world value or even hard to compare since many have in house applications that don't scale or scale different like the ones benchmarked in reviews. 90% of the datacenters don't even require more then any midrange cpu, anything above midrange is wasted money and both vendors provide more then adequate solutions to that. It's the human mind that is often blocking sanity. Investing that wasted money in other solutions often provide a better total performing solution.
anti_shill - Monday, April 2, 2012 - link
shill_detector by anti_shill on Monday, April 02, 2012Here's a more accurate reflection of Bulldozer/ interlagos performance, untainted by intel ad bucks...
http://www.phoronix.com/scan.php?page=article&...
But if u really want to see what the true story is, have a look at AMD's stock price lately, and their server wins. They absolutely smoke intel on virtualization, and anything that requires a lot of threads. It's not even close.