The Opteron 6276: a closer look
by Johan De Gelas on February 9, 2012 6:00 AM EST- Posted in
- IT Computing
- CPUs
- Bulldozer
- AMD
- Opteron
- Cloud Computing
- Interlagos
SAP S&D Benchmark
The SAP SD (sales and distribution, 2-tier internet configuration) benchmark is an interesting benchmark as it is a real world client-server application contrary to many server benchmark (such as SpecJBB, SpecIntRate, etc.). We looked at SAP's benchmark database for these results. The results below all run on Windows 2008 and MS SQL Server 2008 database (both 64-bit).
Every 2-tier Sales & Distribution benchmark was performed with SAP's latest ERP 6 enhancement package 4. These results are NOT comparable with any benchmark performed before 2009. We analyzed the SAP Benchmark in-depth in one of our earlier articles. So far, our profile of the benchmark shows:
- Very parallel resulting in excellent scaling
- Likes large caches (memory latency)
- Very sensitive to sync ("cache coherency") latency
- Low IPC
- Branch memory intensive code
We managed to get even better profiling of the benchmark. IPC is as low as 0.5 (!) on the most modern Intel CPU architectures. About 48% of the instructions are loads and stores and 18% are branches. One percent of those branches is mispredicted, so the branch misprediction ratio is slightly higher than 5% on modern Intel cores.
Especially the instruction cache is hit hard, and the hit rate is typically a lot lower than in other applications (probably 10% misses and lower). Even the large L3 caches are not capable of satisfying all requests. The SAP SD benchmarks needs between 10-30GB/s, depending on how aggressive the prefetchers are.
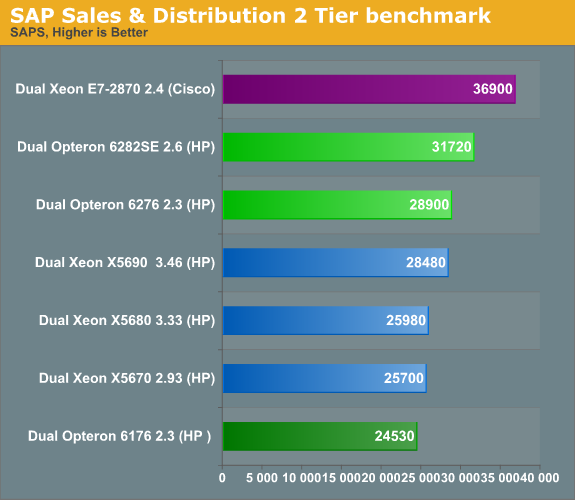
SAP is one of the benchmarks that scale very well and it is shows: the server CPUs with the highest thread count are on top. We remember from older benchmarks that enabling Hyper-Threading (on Nehalem and later) boosts SAP's performance by 35%. As the IPC of a single SAP thread is relatively low (0.5 and lower), the decoding front end of the Bulldozer core should be able to handle this easily. Therefore, the extra integer cluster on the Opteron can really do its magic.
We don't have any Xeon X5650 benchmarks, but a quick calculation tells us that the new Opteron 6276 should be about 20% faster than the X5650. It is also about 18% faster, clock for clock, than the older Opteron 6176. The new Opteron does well here.








46 Comments
View All Comments
Jaguar36 - Thursday, February 9, 2012 - link
I too would love to see more HPC related benchmarks. Finite Element Analysis (FEA) or Computational Fluid Dynamic (CFD) programs scale very well with increased core count, and are something that is highly CPU dependent. I've found it very difficult to find good performance information for CPUs under this load.I'd be happy to help out developing some benchmark problems if need be.
dcollins - Thursday, February 9, 2012 - link
These would indeed be interesting benchmarks to see. These workloads are very floating point heavy so I imagine that the new Opterons will perform poorly. 16 modules won't matter when they only have 8 FPUs. Of course, I am speculating here.Going forward, these types of workloads should be moving toward GPUs rather than CPUs, but I understand the burden of legacy software.
silverblue - Friday, February 10, 2012 - link
They have 8 FPUs capable of 16x 128-bit or 8x 256-bit instructions per clock. On that level, it shouldn't be at a disadvantage.bnolsen - Sunday, February 12, 2012 - link
GPUs are pretty poor for general purpose HPC. If someone wants to fork out tons of $$$ to hack their problem onto a gpu (or they get lucky and somehow their problem fits a gpu well) that's fine but not really smart considering how short release cycles are, etc.I have access to a quad socket magny cours built mid last year. In december I put together a sandy-e 3930k portable demo system. Needless to say the 3930k had at least 10% more throughput on heavy processing tasks (enabling all intel sse dropped in another 15%). It also handily beat our dual xeon nehalem development system as well. With mixed IO and cpu heavy loads the advantage dropped but was still there.
I'd love to be able to test these new amds just to see but its been much easier telling customers to stick with intel, especially with this new amd cpu.
MySchizoBuddy - Friday, March 9, 2012 - link
"GPUs are pretty poor for general purpose HPC."tell that to the #2, #4 and #5 most powerful supercomputers in the world. I'm sure no one told them.
hooflung - Thursday, February 9, 2012 - link
I think I'd rather see some benchmarks based around Java EE6 and an appropriate container such as Jboss AS 7. I'd also like to see some Java 7 application benchmarks ( server oriented ).I'd also like to see some custom Java benchmarks using Akka library so we can see some Software transactional memory benchmarks. Possibly a node.js benchmark as well to see if these new technologies can scale.
What I've seen here is that the enterprise circa 2006 has a love hate relationship with AMD. I'd also like to see some benchmarks of the Intel vs AMD vs SPARC T4 in both virtualized and non virtualized J2EE environments. But this article does have some really interesting data.
jibberegg - Thursday, February 9, 2012 - link
Thanks for the great and informative article! Minor typo for you..."Using a PDU for accurate power measurements might same pretty insane"
should be
"Using a PDU for accurate power measurements might seem pretty insane"
phoenix_rizzen - Thursday, February 9, 2012 - link
MySQL has to be the absolute worst possible choice for testing multi-core CPUs (as evidenced in this review). It just doesn't scale beyond 4-8 cores, depending on CPU choice and MySQL version.A much better choice for "alternative SQL database" would be PostgreSQL. That at least scales to 32 cores (possibly more, but I've never seen a benchmark beyond 32). Not to mention it's a much better RDBMS than MySQL.
MySQL really is only a toy. The fact that many large websites run on top of MySQL doesn't change that fact.
PixyMisa - Friday, February 10, 2012 - link
This is a very good point. While it can be done, it's very fiddly to get MySQL to scale to many CPUs, much simpler to just shard the database and run multiple instances of MySQL. (And replication is single-threaded anyway, so if you manage to get one MySQL instance running with very high inserts/updates, you'll find replication can't keep up.)Same goes for MongoDB and, of course, Redis, which is single-threaded.
We have ten large Opteron servers running CentOS 6, five 32-core and five 48-core, and all our applications are sharded and virtualised at a point where the individual nodes still have room to scale. Since our applications are too large to run un-sharded anyway, and the e7 Xeons cost an absolute fortune, the Opteron was the way to go.
The only back-end software we've found that scales smoothly to large numbers of CPUs is written in Erlang - RabbitMQ, CouchDB, and Riak. We love RabbitMQ and use it everywhere; unfortunately, while CouchDB and Riak scale very nicely, they start out pretty darn slow.
We actually ran a couple of 40-core e7 Xeon systems for a few months, and they had some pretty serious performance problems for certain workloads too - where the same workload worked fine on either a dual X5670 or a quad Opteron. Working out why things don't scale is often more work than just fixing them so that they do; sometimes the only practical thing to do is know what platform works for what workload, and use the right hardware for the task at hand.
Having said all that, the MySQL results are still disappointing.
JohanAnandtech - Friday, February 10, 2012 - link
"It just doesn't scale beyond 4-8 cores, depending on CPU choice and MySQL version."You missed something: it does scale beyond 12 Xeon cores, and I estimate that scaling won't be bad until you go beyond 24 cores. I don't see why the current implementation of MySQL should be called a toy.
PostgreSQL: interesting several readers have told me this too. I hope it is true, because last time we test PostgreSQL was worse than the current MySQL.