AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
Compute: The Real Reason for GCN
Moving on from our game tests we’ve now reached the compute benchmark segment of our review. While the gaming performance of the 7970 will have the most immediate ramifications for AMD and the product, it is the compute performance that I believe is the more important metric in the long run. GCN is both a gaming and a compute architecture, and while its gaming pedigree is well defined its real-world compute capabilities still need to be exposed.
With that said, we’re going to open up this section with a rather straightforward statement: the current selection of compute applications for AMD GPUs is extremely poor. This is especially true for anything that would be suitable as a benchmark. Perhaps this is because developers ignored Evergreen and Northern Islands due to their low compute performance, or perhaps this is because developers still haven’t warmed up to OpenCL, but here at the tail end of 2011 there just aren’t very many applications that can make meaningful use of the pure compute capabilities of AMD’s GPUs.
Aggravating this some is that of the applications that can use AMD’s compute capabilities, some of the most popular ones among them have been hand-tuned for AMD’s previous architectures to the point that they simply will not run on Tahiti right now. Folding@Home, FLACC, and a few other candidates we looked into for use as compute benchmarks all fall under this umbrella, and as a result we only have a limited toolset to work with for proving the compute performance of GCN.
So with that out of the way, let’s get started.
Since we just ended with Civilization V as a gaming benchmark, let’s start with Civilization V as a compute benchmark. We’ve seen Civilization V’s performance skyrocket on 7970 and we’ve theorized that it’s due to improvements in compute shader performance, and now we have a chance to prove it.
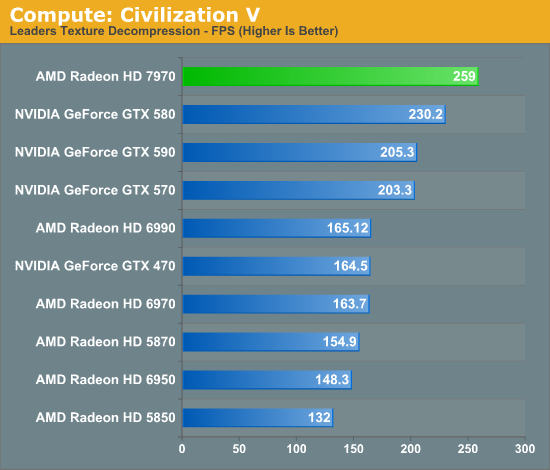
And there’s our proof. Compared to the 6970, the 7970’s performance on this benchmark has jumped up by 58%, and even the previously leading GTX 580 is now beneath the 7970 by 12%. GCN’s compute ambitions are clearly paying off, and in the case of Civilization V it’s even enough to dethrone NVIDIA entirely. If you’re AMD there’s not much more you can ask for.
Our next benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. We’re now using a development build from the version 2.0 branch, and we’ve moved on to a more complex scene that hopefully will provide a greater challenge to our GPUs.

Again the 7970 does incredibly well here compared to AMD’s past architectures. AMD already did rather well here even with the limited compute performance of their VLIW4 architecture, and with GCN AMD once again puts their old architectures to shame, and puts NVIDIA to shame too in the process. Among single-GPU cards the GTX 580 is the closest competitor and even then the 7970 leads it by 72%. The story is much the same for the 7970 versus the 6970, where the 7970 leads by 74%. If AMD can continue to deliver on performance gains like these, the GCN is going to be a formidable force in the HPC market when it eventually makes its way there.
For our next benchmark we’re once again looking at compute shader performance, this time through the Fluid simulation sample in the DirectX SDK. This program simulates the motion and interactions of a 16k particle fluid using a compute shader, with a choice of several different algorithms. In this case we’re using two of them: a highly optimized grid search that Microsoft based on an earlier CUDA implementation, and an (O)n^2 nearest neighbor method that is optimized by using shared memory to cache data.

There are many things we can gather from this data, but let’s address the most important conclusions first. Regardless of the algorithm used, AMD’s VLIW4 and VLIW5 architectures had relatively poor performance in this simulation; NVIDIA meanwhile has strong performance with the grid search algorithm, but more limited performance with the shared memory algorithm. 7970 consequently manages to blow away the 6970 in all cases, and while it can’t beat the GTX 580 at the grid search algorithm it is 45% faster than the GTX 580 with the shared memory algorithm.
With GCN AMD put a lot of effort into compute performance, not only with respect to their shader/compute hardware, but with the caches and shared memory to feed that hardware. I don’t believe we have enough data to say anything definitive about how Tahiti/GCN’s cache compares to Fermi’s cache, this benchmark does raise the possibility that GCN cache design is better suited for less than optimal brute force algorithms. In which case what this means for AMD could be huge, as it could open up new HPC market opportunities for them that NVIDIA could never access, and certainly it could help AMD steal market share from NVIDIA.
Moving on to our final two benchmarks, we’ve gone spelunking through AMD’s OpenCL archive to dig up a couple more compute scenarios to use to evaluate GCN. The first of these is AESEncryptDecrypt, an OpenCL AES encryption routine that AES encrypts/decrypts an 8K x 8K pixel square image file. The results of this benchmark are the average time to encrypt the image over a number of iterations of the AES cypher.

We went into the AMD OpenCL sample archives knowing that the projects in it were likely already well suited for AMD’s previous architectures, and there is definitely a degree of that in our results. The 6970 already performs decently in this benchmark and ultimately the GTX 580 is the top competitor. However the 7970 still manages to improve on the 6970 by a sizable degree, and accomplishes this encryption task in only 65% the time. Meanwhile compared to the GTX 580 it trails by roughly 12%, which shows that if nothing else Fermi and GCN are going to have their own architectural strengths and weaknesses, although there’s obviously some room for improvement.
One interesting fact we gathered from this compute benchmark is that it benefitted from the increase in bandwidth offered by PCI Express 3.0. With PCIe 3.0 the 7970 improves by about 10%, showcasing just how important transport bandwidth is for some compute tasks. Ultimately we’ll reach a point where even games will be able to take full advantage of PCIe 3.0, but for right now it’s the compute uses that will benefit the most.
Our final benchmark also comes from the AMD OpenCL archives, and it’s a variant of the Monte Carlo method implemented in OpenCL. Here we’re timing how long it takes to execute a 400 step simulation.

For our final benchmark the 7970 once again takes the lead. The rest of the Radeon pack is close behind so GCN isn’t providing an immense benefit here, but AMD still improves upon the 6970 by 14%. Meanwhile the lead over the GTX 580 is larger at 33%.
Ultimately from these benchmarks it’s clear that AMD is capable of delivering on at least some of the theoretical potential for compute performance that GCN brings to the table. Not unlike gaming performance this is often going to depend on the task at hand, but the performance here proves that in the right scenario Tahiti is a very capable compute GPU. Will it be enough to make a run at NVIDIA’s domination with Tesla? At this point it’s too early to tell, but the potential is there, which is much more than we could say about VLIW4.








292 Comments
View All Comments
CeriseCogburn - Thursday, March 8, 2012 - link
Interesting, amd finally copied nvidia..." This problem forms the basis of this benchmark, and the NQueen test proves once more that AMD's Radeon HD 7970 tremendously benefits from leaving behind the VLIW architecture in complex workloads. Both the HD 7970 and the GTX 580 are nearly twice as fast as the older Radeons. "
When we show diversity we should also show that amd radeon has been massively crippled for a long time except when "simpleton" was the key to speed. "Superior architecture" actually means "simple and stupid" - hence "fast" at repeating simpleton nothings, but unable to handle "complex tasks".
LOL - the dumb gpu by amd has finally "evolved".
chizow - Thursday, December 22, 2011 - link
....unfortunately its going to be pitted against Kepler for the long haul.There's a lot to like about Southern Islands but I think its going to end up a very similar situation as Evergreen vs. Fermi, where Evergreen released sooner and took the early lead, but Fermi ultimately won the generation. I expect similar with Tahiti holding the lead for the next 3-6 months until Kepler arrives, but Kepler and its refresh parts winning this 28nm generation once they hit the streets.
Overall the performance and changes AMD made with Tahiti look great compared to Northern Islands, but compared to Fermi parts, its just far less impressive. If you already owned an AMD NI or Evergreen part, there'd be a lot of reason to upgrade, but if you own a Fermi generation Nvidia card there's just far less reason to, especially at the asking price.
I do like how AMD opened up the graphics pipeline with Tahiti though, 384-bit bus, 3GB framebuffer, although I wonder if holding steady with ROPs hurts them compared to Kepler. It would've also been interesting to see how the 3GB GTX 580 compared at 2560 since the 1.5GB model tended to struggle even against 2GB NI parts at that resolution.
ravisurdhar - Thursday, December 22, 2011 - link
My thoughts exactly. Can't wait to see what Kepler can do.Also...4+B transistors? mind=blown. I remember when we were ogling over 1B. Moore's law is crazy.... :D
johnpombrio - Wednesday, December 28, 2011 - link
Exactly. If you look at all the changes that AMD did on the card, I would have expected better results: the power consumption decrease with the Radeon 7970 is mainly due to the die shrink to 28nm. NVidia is planning on a die shrink of their existing Fermi architecture before Kepler is released:http://news.softpedia.com/news/Nvidia-Kepler-Is-On...
Another effect of the die shrink is that clock speed usually increases as there is less heat created at the lower voltage needed with a smaller transistor.
The third change that is not revolutionary is the bump of AMD's 7970's memory bus from 384 bits (matching the 580) from the 6970's 256 bits along with 3GB DDR5 memory vs the GTX580's 1.5GB and the 6970's 2GB.
The final non revolutionary change is bumping the number of stream processors by 33% from 1,536 to 2,048.
Again, breaking out my calculator, the 35% bump in the number of stream processors ALONE causes the increase in the change in the benchmark differences between the 7970 and the 6970.
The higher benchmark, however, does not show ANY OTHER large speed bumps that SHOULD HAVE OCCURED due to the increase in the memory bus size, the higher amount of memory, compute performance, texture fill rate, or finally the NEW ARCHITECTURE.
If I add up all the increases in the technology, I would have expected benchmarks in excess of 50-60% over the previous generation. Perhaps I am naive in how much to expect but, hell, a doubling of transistor count should have produced a lot more than a 35% increase. Add the new architecture, smaller die size, and more memory and I am underwhelmed.
CeriseCogburn - Thursday, March 8, 2012 - link
Well, we can wait for their 50%+ driver increase package+ hotfixes - because after reading that it appears they are missing the boat in drivers by a wide margin.Hopefully a few months after Kepler blows them away, and the amd fans finally allow themselves to complain to the proper authorities and not blame it on Nvida, they will finally come through with a "fix" like they did when the amd (lead site review mastas) fans FINALLY complained about crossfire scaling....
KaarlisK - Thursday, December 22, 2011 - link
What is the power consumption with multiple monitors? Previously, you could not downclock GDDR5, so the resulting consumption was horrible.Ryan Smith - Thursday, December 22, 2011 - link
"On that note, for anyone who is curious about idle clockspeeds and power consumption with multiple monitors, it has not changed relative to the 6970. When using a TMDS-type monitor along with any other monitor, AMD has to raise their idle clockspeeds from 350MHz core and 600Mhz memory to 350MHz core and the full 5.5GHz speed for memory, with the power penalty for that being around 30W. Matched timing monitors used exclusively over DisplayPort will continue to be the only way to be able to use multiple monitors without incurring an idle penalty."KaarlisK - Thursday, December 22, 2011 - link
Thank you for actually replying :)I am so sorry for having missed this.
ltcommanderdata - Thursday, December 22, 2011 - link
Great review.Here's hoping that AMD will implement 64-bit FP support across the whole GCN family and not just the top-end model. Seeing AMD's mobile GPUs don't use the highest-end chip, settling for the 2nd highest and lower, there hasn't been 64-bit FP support in AMD mobile GPUs since the Mobility HD4800 series. I'm interested in this because I can then dabble in some 64-bit GPGPU programming on the go. It also has implications for Apple since their iMacs stick to mobile GPUs, so would otherwise be stuck without 64-bit FP support which presumably could be useful for some of their professional apps.
In regards to hardware accelerated Megatexture, is it directly applicable to id Tech 5's OpenGL 3.2 solution? ie. Will id Tech 5 games see an immediate speed-up with no recoding needed? Or does Partially Resident Texture support require a custom AMD specific OpenGL extension? If it's the later, I can't see it going anywhere unless nVidia agrees to make it a multivendor EXT extension.
Ryan Smith - Thursday, December 22, 2011 - link
Games will need to be specifically coded for PRT; it won't benefit any current games. And you are correct in that it will require and AMD OpenGL extension to use (it won't be accessible from D3D at this time).