AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
Partially Resident Textures: Not Your Father’s Megatexture
John Carmack’s id Software may not be the engine licensing powerhouse it was back in the Quake 3 days, but that hasn’t changed the revolutionary nature of his engine designs. The reason we bring this up is because there’s a great deal of GPU technology that can be directly mapped to concepts Carmack first implemented. For id Tech 4 Carmack implemented shadow volume technology, which was then first implemented in hardware by NVIDIA as their UltraShadow technology, and has since then been implemented in a number of GPUs. For id Tech 5 the trend has continued, now with AMD doing a hardware implementation of a Carmack inspired technology.
Among the features added to Graphics Core Next that were explicitly for gaming, the final feature was Partially Resident Textures, which many of you are probably more familiar with in concept as Carmack’s MegaTexture technology. The concept behind PRT/Megatexture is that rather than being treated as singular entities, due to their size textures should be broken down into smaller tiles, and then the tiles can be used as necessary. If a complete texture isn’t needed, then rather than loading the entire texture only the relevant tiles can be loaded while the irrelevant tiles can be skipped or loaded at a low quality. Ultimately this technology is designed to improve texture streaming by streaming tiles instead of whole textures, reducing the amount of unnecessary texture data that is streamed.

Currently MegaTexture does this entirely in software using existing OpenGL 3.2 APIs, but AMD believes that more next-generation game engines will use this type of texturing technology. Which makes it something worth targeting, as if they can implement it faster in hardware and get developers to use it, then it will improve game performance on their cards. Again this is similar to volume shadows, where hardware implementations sped up the process.
In order to implement this in hardware AMD has to handle two things: texture conversion, and cache management. With texture conversion, textures need to be read and broken up into tiles; AMD is going with a texture format agnostic method here that can simply chunk textures as they stand, keeping the resulting tiles in the same format. For AMD’s technology each tile will be 64KB, which for an uncompressed 32bit texture would be enough room for a 128 x 128 chunk.
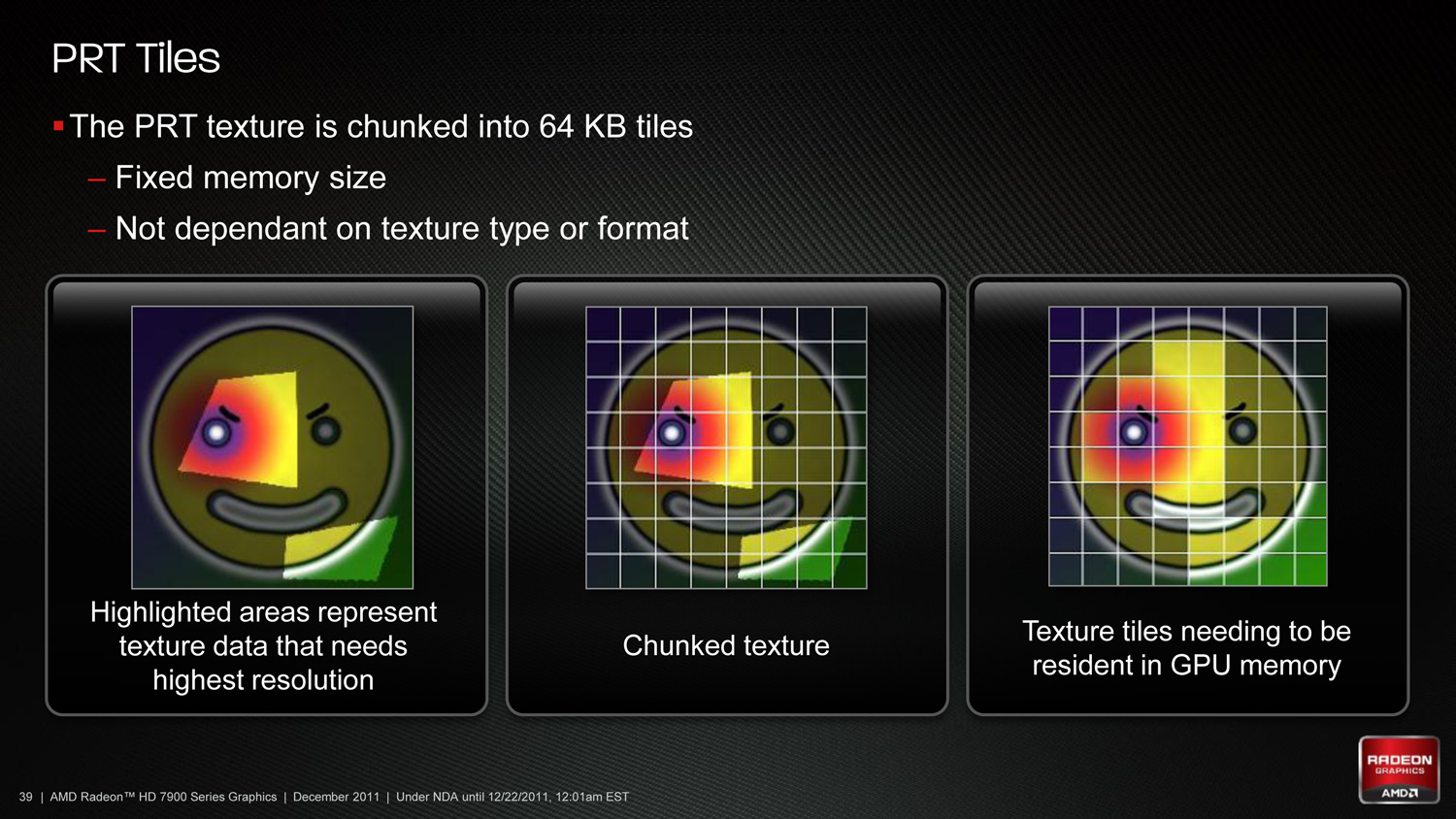
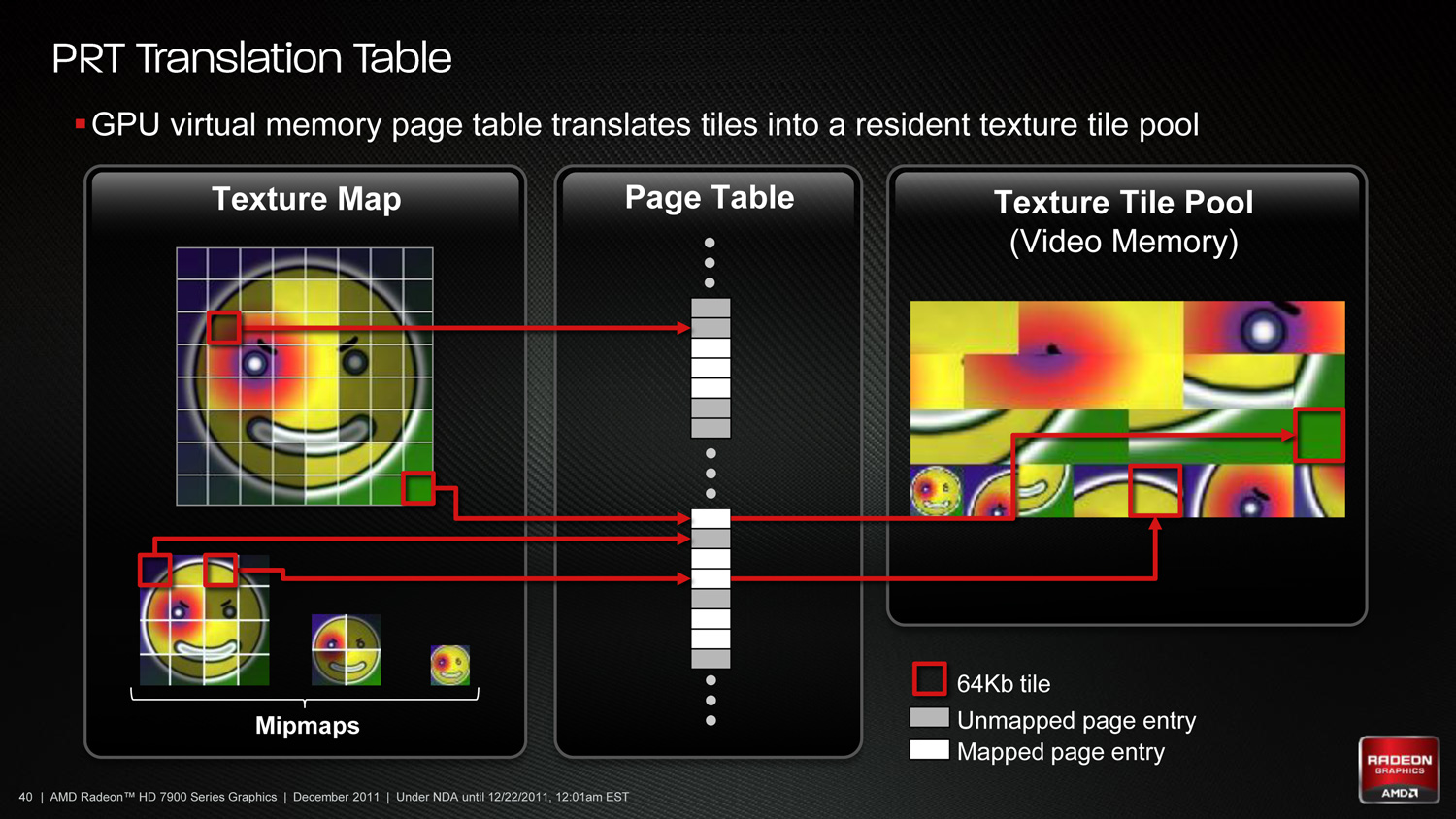
The second aspect of PRT is managing the tiles. In essence PRT reduces local video memory to a very large cache, where tiles are mapped/pinned as necessary and then evicted as per the cache rules, and elsewhere the hardware handles page/tile translation should a tile not already be in the cache. Large tomes have been written on caching methods, and this aspect is of particular interest to AMD because what they learn about caching here they can apply to graphical workloads (i.e. professional) and not just gaming.
To that end AMD put together a technology demo for PRT based on Per-Face Texture Mapping (PTEX), a Disney-developed texture mapping technique that maps textures to polygons in a 1:1 ratio. Disney uses this technique for production rendering, as by constraining textures to a single polygon they don’t have to deal with any complexities that arise as a result of mapping a texture over multiple polygons. In the case of AMD’s demo it not only benefits for the reasons that Disney uses it, but also because when combined with tessellation it trivializes vector displacement, making art generation for tessellated games much easier to create. Finally, PRT fits into all of this by improving the efficiency of accessing and storing the Ptex texture chunks.
Wrapping things up, for the time being while Southern Islands will bring hardware support for PRT software support will remain limited. As D3D is not normally extensible it’s really only possible to easily access the feature from other APIs (e.g. OpenGL), which when it comes to games is going to greatly limit the adoption of the technology. AMD of course is working on the issue, but there are few ways around D3D’s tight restrictions on non-standard features.











292 Comments
View All Comments
mczak - Thursday, December 22, 2011 - link
Oh yes _for this test_ certainly 32 ROPs are sufficient (FWIW it uses FP16 render target with alpha blend). But these things have caches (which they'll never hit in the vantage fill test, but certainly not everything will have zero cache hits), and even more important than color output are the z tests ROPs are doing (which also consume bandwidth, but z buffers are highly compressed these days).You can't really say if 32 ROPs are sufficient, nor if they are somehow more efficient judged by this vantage test (as just about ANY card from nvidia or amd hits bandwidth constraints in that particular test long before hitting ROP limits).
Typically it would make sense to scale ROPs along with memory bandwidth, since even while it doesn't need to be as bad as in the color fill test they are indeed a major bandwidth eater. But apparently AMD disagreed and felt 32 ROPs are enough (well for compute that's certainly true...)
cactusdog - Thursday, December 22, 2011 - link
The card looks great, undisputed win for AMD. Fan noise is the only negative, I was hoping for better performance out the new gen cooler but theres always non-reference models for silent gaming.Temps are good too so theres probably room to turn the fan speed down a little.
rimscrimley - Thursday, December 22, 2011 - link
Terrific review. Very excited about the new test. I'm happy this card pushes the envelope, but doesn't make me regret my recent 580 purchase. As long as AMD is producing competitive cards -- and when the price settles on this to parity with the 580, this will be the market winner -- the technology benefits. Cheers!nerfed08 - Thursday, December 22, 2011 - link
Good read. By the way there is a typo in final words.faster and cooler al at once
Anand Lal Shimpi - Thursday, December 22, 2011 - link
Fixed, thank you :)Take care,
Anand
hechacker1 - Thursday, December 22, 2011 - link
I think most telling is the minimum FPS results. The 7970 is 30-45% ahead of the previous generation; in a "worse case" situation were the GPU can't keep up or the program is poorly coded.Of course they are catching up with Nvidia's already pretty good minimum FPS, but I am glad to see the improvement, because nothing is worse than stuttering during a fasted pace FPS. I can live with 60fps, or even 30fps, as long as it's consistent.
So I bet the micro-stutter problem will also be improved in SLI with this architecture.
jgarcows - Thursday, December 22, 2011 - link
While I know the bitcoin craze has died down, I would be interested to see it included in the compute benchmarks. In the past, AMD has consistently outperformed nVidia in bitcoin work, it would also be interesting to see Anandtech's take as to why, and to see if the new architecture changes that.dcollins - Thursday, December 22, 2011 - link
This architecture will most likely be a step backwards in terms of bitcoin mining performance. In the GCN architecture article, Anand mentioned that buteforce hashing was one area where a VLIW style architecture had an advantage over a SIMD based chip. Bitcoin mining is based on algorithms mathematically equivalent to password hashing. With GCN, AMD is changing the very thing that made their card better miners than Nvidia's chips.The old architecture is superior for "pure," mathematically well defined code while GCN is targeted at "messy," more practical and thus widely applicable code.
wifiwolf - Thursday, December 22, 2011 - link
a bit less than expected, but not really an issue:http://www.tomshardware.co.uk/radeon-hd-7970-bench...
dcollins - Thursday, December 22, 2011 - link
You're looking at a 5% increase in performance for a whole new generation with 35% more compute hardware, increased clock speed and increased power consumption: that's not an improvement, it's a regression. I don't fault AMD for this because Bitcoin mining is a very niche use case, but Crossfire 68x0 cards offer much better performance/watt and performance/$.