Quick update: more Interlagos testing
by Johan De Gelas on December 8, 2011 5:11 AM EST- Posted in
- IT Computing
- IT Computing general
- Cloud Computing
As promised in our last Opteron "Interlagos" review, we have been taking the time to deepen our understanding of AMD's newest Interlagos server platform and the "Bulldozer" architecture. Server reviewing remains a complex undertaking: some of the benchmarks take hours to set up and run, and power management policies, I/O subsystems and configuration settings can completely alter the outcome of a benchmark. That sounds very obvious right? It is not in practice.
Let me give you an example how subtle server benchmarking can be. One of the benchmarks missing in the original review was the MS SQL server benchmark, and for a reason. We did some extensive scaling benchmarks and our gut feeling told us that some of the results were a bit off the mark. So we kept the benchmark out of the original review until we pinpointed the problem.
Just a few days ago, we found out that a tiny bit of time-outs (1%, caused mostly by a data provider time out setting) can boost the results by about 20% erroneously as the actual workload is decreased. So our MS SQL server benchmark was not as accurate as we thought it was. Luckily we have solved all problems, and the benchmark is now more accurate than ever. You can expect to see the MS SQL server benchmarks on different server platforms and an in depth analysis in a forthcoming article.
While solving the MS SQL Server benchmark issues required a lot of testing, analysis and debate with Dieter, the lead developer of our stress testing tool vApus, we missed a more obvious tweak that could have improved our blender benchmarking. Luckily, we still have a community that is willing to give us valuable feedback. Greg Wereszko point out that our Blender benchmark cuts the render job up into only 64 tiles (X=8, Y=8). The result is that near the end of the test several cores are inactive, especially on the Interlagos Opteron (32 cores/threads).
So we increased the number of tiles beyond 8x8, to check if this improves performance on our 32 and 24 thread machines, and it did. (Quick note: the Blender benchmark on Windows is one of the worst benchmarks for the Opteron Interlagos, so see this as "worst case" performance point.)
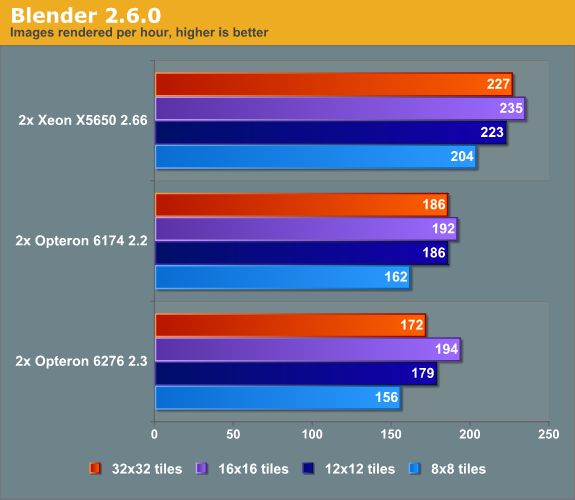
Instead of trailing behind the Opteron 6174, the Opteron "Interlagos" 6276 manages to perform a tiny bit better than its older sibling when we use 256 (16x16) tiles. The Opteron 6276 improves performance by 24%, the Xeon X5650 and Opteron 6174 by 19%.
Using more tiles, all CPUs are able to show their top performance. It also shows the rather "fragile performance profile" of the new Opteron. Many users are going to use standard settings and will never bother with this kind of tuning. As a result they are not going to use the full potential of the new Opteron. The Xeon's higher single-threaded performance makes it less vulnerable to less optimal software settings.
At the other side of the coin, once well tuned the Opteron 62xx offers an interesting performance per dollar ratio and this "fragile performance profile" may become very robust in FP intensive applications once the use of AVX gets widespread. We are taking quite a bit of time to make sure that the next server article can give more detailed information, but rest assured that we did not give up: we will update our server benchmarking...when it is finished.








30 Comments
View All Comments
davegraham - Thursday, December 8, 2011 - link
johan,have you been testing with DDR3-1600 ECC/REG?
d
JohanAnandtech - Thursday, December 8, 2011 - link
yes. 8x 8 GB of DDR3-1600. The RAM that was inside the AMD review server.davegraham - Thursday, December 8, 2011 - link
thanks. I've been testing for several months on B2 silicon. I've noticed perf differences between 2k8 r2 SP1 and non-SP1 systems as well as differences with win7 sp1 and non-SP1. Linux kernels w/3.x and greater tend to perform a bit better as well (Suse, in particular) than their windows counterparts.d
Klimax - Friday, December 9, 2011 - link
Not suprising. When you use arch specific optimisation then by definition other archs will not be used optimally. (small exception is Core arch)I'd say it would be more strange to see both CPUs to get better/stay same with arch specific opt.
Morg. - Tuesday, December 13, 2011 - link
I don't think you get it : an interlagos-optimized beat a xeon-optimized hands down . no surprise though.But this goes to show that half-assed benchmarks cannot show wether a cpu is better than another one.
Elite99 - Thursday, December 8, 2011 - link
And here's the article and benchmark: http://www.heise.de/artikel-archiv/ct/2011/25/158/RaggedRaz - Thursday, December 8, 2011 - link
Benchmarks: synthetic, real world, niche users? Compilers and -O flags? Clearly Bulldozer's failure or success does not answer to oversimplified metrics. I am a big AMD fan, but clearly they have made some undefendable gambles: slightly too deep a pipeline, lower IPC and of course no AMD optimized compilers! Not to mention the lack of in house fab capability (sure their existence depended on spinning off to GBF, but too late on HKMG, a bulk node behind, killing off phenom II, betting on TSMC... you get the idea).... aesthetically it is a pleasing design, and hopefully with an iteration or two, bulldozer +fusion with a decent GPU, and more true GPGPU optimized programs/Oses and we'll see some wisdom in their choices. Just hope they don't go bankrupt before we get to a truly heterogeneous computing era...TiGr1982 - Thursday, December 8, 2011 - link
I fully agree; let's hope they'll survive at least to deliver "Steamroller"/"Excavator" CPU generations...Filiprino - Thursday, December 8, 2011 - link
Yeah, AMD f***ed up a bit and for quite a while.davegraham - Thursday, December 8, 2011 - link
Open64 is AMD optimized and is frightfully easy to use. pretty sure that it'll do the job.