Bulldozer for Servers: Testing AMD's "Interlagos" Opteron 6200 Series
by Johan De Gelas on November 15, 2011 5:09 PM ESTMaxwell Render Suite
The developers of Maxwell Render Suite--Next Limit--aim at delivering a renderer that is physically correct and capable of simulating light exactly as it behaves in the real world. As a result their software has developed a reputation of being powerful but slow. And "powerful but slow" always attracts our interest as such software can be quite interesting benchmarks for the latest CPU platforms. Maxwell Render 2.6 was released less than two weeks ago, on November 2, and that's what we used.

We used the "Benchwell" benchmark, a scene with HDRI (high dynamic range imaging) developed by the user community. Note that we used the "30 day trial" version of Maxwell. We converted the time reported to render the scene in images rendered per hour to make it easier to interprete the numbers.
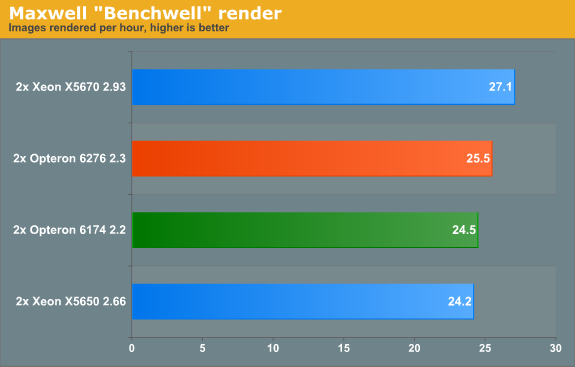
Since Magny-cours made its entrance, AMD did rather well in the rendering benchmarks and Maxwell is no difference. The Bulldozer based Opteron 6276 gives decent but hardly stunning performance: about 4% faster than the predecessor. Interestingly, the Maxwell renderer is not limited by SSE (Floating Point) performance. When we disable CMT, the AMD Opteron 6276 delivered only 17 frames per second. In other words the extra integer cluster delivers 44% higher performance. There is a good chance that the fact that you disable the second load/store unit by disabling CMT is the reason for the higher performance that the second integer cluster delivers.
Rendering: Blender 2.6.0
Blender is a very popular open source renderer with a large community. We tested with the 64-bit Windows version 2.6.0a. If you like, you can perform this benchmark very easily too. We used the metallic robot, a scene with rather complex lighting (reflections) and raytracing. To make the benchmark more repetitive, we changed the following parameters:
- The resolution was set to 2560x1600
- Antialias was set to 16
- We disabled compositing in post processing
- Tiles were set to 8x8 (X=8, Y=8)
- Threads was set to auto (one thread per CPU is set).
To make the results easier to read, we again converted the reported render time into images rendered per hour, so higher is better.
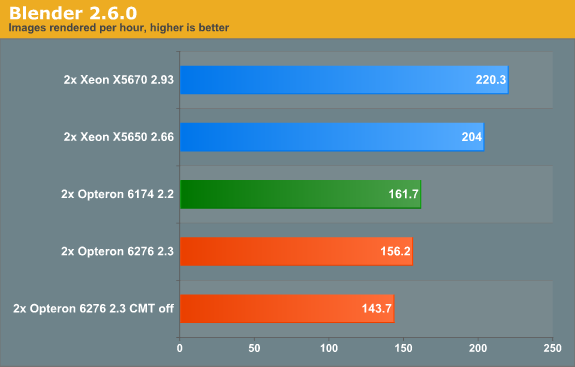
Last time we checked (Blender 2.5a2) in Windows, the Xeon X5670 was capable of 136 images per hour, while the Opteron 6174 did 113. So the Xeon was about 20% faster. Now the gap widens: the Xeon is now 36% faster. The interesting thing that we discovered is that the Opteron is quite a bit faster when benchmarked in linux. We will follow up with some Linux numbers in the next article. The Opteron 6276 is in this benchmark 4% slower than its older brother, again likely due in part to the newness of its architecture.








106 Comments
View All Comments
JohanAnandtech - Thursday, November 17, 2011 - link
1) Niagara is NOT a CMT. It is interleaved multipthreading with SMT on top.
I haven't studied the latest Niagaras but the T1 was a fine grained mult-threaded CPU. It switched like a gatling gun between threads, and could not execute two threads at the same time.
Penti - Thursday, November 17, 2011 - link
SPARC T2 and onwards has additional ALU/AGU resources for a half physical two thread (four logically) solution per core with shared scheduler/pipeline if I remember correctly. That's not when CMT entered the picture according to SUN and Sun engineers any way. They regard the T1 as CMT as it's chip level. It's not just a CMP-chip any how. SMT is just running multiple threads on the cpus, CMP is working the same as SMP on separate sockets. It is not the same as AMDs solution however.Phylyp - Tuesday, November 15, 2011 - link
Firstly, this was a very good article, with a lot of information, especially the bits about the differences between server and desktop workloads.Secondly, it does seem that you need to tune either the software (power management settings) or the chip (CMT) to get the best results from the processor. So, what advise is AMD offering its customers in terms of this tuning? I wouldn't want to pony up hundreds of dollars to have to then search the web for little titbits like switching off CMT in certain cases, or enabling High-performance power management.
Thirdly, why is the BIOS reporting 32 MB of L2 cache instead of 8 MB?
mino - Wednesday, November 16, 2011 - link
No need for tuning - turbo is OS-independent (unless OS power management explicitly disables it aka Windows).Just disable the power management on the OS level (= high performance fro Windows) and you are good to go.
JohanAnandtech - Thursday, November 17, 2011 - link
The BIOS is simply wrong. It should have read 16 MB (2 orochi dies of 8 MB L3)gamoniac - Tuesday, November 15, 2011 - link
Thanks, Johan. I run HyperV on Windows Server 2008 R2 SP1 on Phonem II X6 (my workstation) and have noticed the same CPU issue. I previously fixed it by disabling AMD's Cool'n'Quiet BIOS setting. After switching to high performance increase my overall power usage by 9 watts but corrected the CPU capping issue you mentioned.Yet another excellent article from AnandTech. Well done. This is how I don't mind spending 1 hour of my precious evening time.
mczak - Tuesday, November 15, 2011 - link
L1 data and instruction cache are swapped (instruction is 8x64kB 2-way data is 16x16kB 4-way)L2 is 8x2MB 16-way
JohanAnandtech - Thursday, November 17, 2011 - link
fixed. My apologies.hechacker1 - Tuesday, November 15, 2011 - link
Curious if those syscalls for virtualization were improved at all. I remember Intel touting they improved the latency each generation.http://www.anandtech.com/show/2480/9
I'm guessing it's worse considering the increased general cache latency? I'm not sure how the latency, or syscall, is related if at all.
Just curious as when I do lots of compiling in a guest VM (Gentoo doing lots of checking of packages and hardware capabilities each compile) it tends to spend the majority of time in the kernel context.
hechacker1 - Tuesday, November 15, 2011 - link
Just also wanted to add: Before I had a VT-x enabled chip, it was unbearably slow to compile software in a guest VM. I remember measuring latencies of seconds for some operations.After getting an i7 920 with VT-x, it considerably improved, and most operations are in the hundred or so millisecond range (measured with latencytop).
I'm not sure how the latests chips fare.