The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTIPC Analysis: What Is Going On?
We decided to focus our attention on our MS SQL Server benchmark and profile it on the most important hardware events (IPC, cache, and branch prediction). We used Intel's VTune Amplifier XE 2011 and AMD's Code Analyst 3.4.1037.88 to get a better understand of this benchmark. To put things into perspective, we compared the results with the extremely popular Cinebench benchmark and the 7-Zip compression benchmark.
Note that VTune has a rather steep learning curve and the numbers presented are more detailed but also harder to interprete than those of Code Analyst. In some cases we had doubts about our measurements on the brand spanking new Xeon E5. That is why we are refraining from publishing those numbers until we are absolutely sure they are accurate, so some of the Xeon E5 numbers are missing.
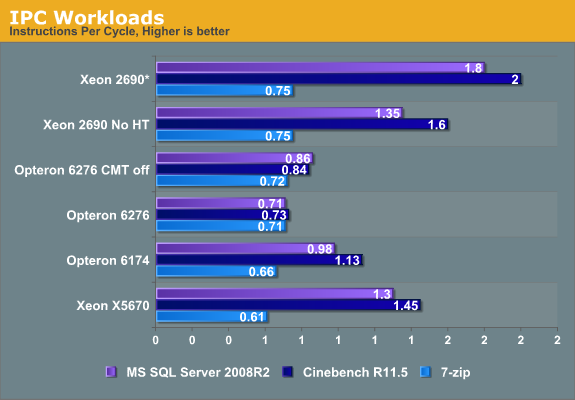
* We add the IPC of the two threads up
It is interesting to note the high Instruction Level Parallelism (ILP) that the Xeon E5 "Sandy Bridge" is able to extract out of these server benchmarks. Almost 1.4 instructions per clock cycle are retired and if you add SMT (Simultaneous Multi Threading), another 0.4 IPC flows through a single core. That is pretty remarkable for a benchmark that consists mostly of SQL statements that result in many branches and loads.
Our Opteron 6200 reveals a bit more about its internal working. Using the extra integer cluster inside the Opteron module causes the separate threads to slow down somewhat. In the case of Cinebench, this is not a real surprise since it contains a lot of SSE floating point commands; a single thread can have the out of order FP cluster all to itself while two threads have to share the SMT capable floating point engine.
But in case of our datamining benchmarks, something else is going on. Single-threaded performance regresses by 18% once you enable the second cluster. We get a 65% speed up (2x 0.71 vs 0.86), which is somewhat lower than the 80% predicted by the AMD slides discussing CMT. So some of the shared resources are slowing down the total performance of our module. We will find out more on the next page.








84 Comments
View All Comments
ArteTetra - Wednesday, May 30, 2012 - link
"A core this complex in my opinion has not been optimized to its fullest potential. Expect better performance when AMD introduces later steppings of this core with regard to power consumption and higher clock frequencies."You don't say?
JohanAnandtech - Thursday, May 31, 2012 - link
A quote by a reader, not ours :-). The idea is probably that Bulldozer was AMD's very first implementation of their new architecture.haplo602 - Wednesday, May 30, 2012 - link
now this was a great read. finaly something interesting (the consumer benchmarks are NOT intereseted anymore for me).I hope there will be a differential analysis once you have Piledriver CPUs available.
JohanAnandtech - Thursday, May 31, 2012 - link
Piledriver analysis: definitely. Thanks for the encouraging words :-)mikato - Friday, June 1, 2012 - link
I agree - great critical thinking in this article! This subject definitely needed more research.Spunjji - Wednesday, June 6, 2012 - link
+1. This is the sort of thing I come here for!Beenthere - Wednesday, May 30, 2012 - link
Expecting Vishera to be an Intel killer is foolish as it's not going to happen and there is no need for it to happen. Ivy Bridge is very much like FX in that it's only 5% faster than SB and runs hot. At least FX chips OC and scale well unlike Ivy Bridge.If AMD can use some of the techniques imployed in Trinity they should be able to get a 15+% improvement over the FX CPUs. This combined with higher clockspeeds now that GloFo has sorted 32nm production should provide a nice performance bump in Vishera.
95% of consumers do not buy the fastest, most over-hyped and over-priced CPU on the planet for their PC or server apps. Mainstream use is what AMD is shooting for at the moment and doing pretty well at it. Eventually they will release APUs for all PC market segments that perform well, use less power and cost less than discrete CPU/GPU combo. THAT is what 95% of the X86 world will be using.
Homeles - Wednesday, May 30, 2012 - link
"Ivy Bridge is very much like FX in that it's only 5% faster than SB and runs hot"I think you need to go read about Intel's tick-tock strategy.
Also, unlike Bulldozer, Ivy Bridge was a step forward. A small one, but performance per watt went up, while with Bulldozer it often went backwards.
Process maturity from GloFo will help, but probably not as much as you would think.
Finally, "95% of users" aren't going to benefit best from a processor built with server workloads in mind. Even with server workloads, Bulldozer fails to deliver. APUs are definitely the future, but keep in mind that Intel's had an APU out for as long as AMD has. If you think that AMD's somehow going to pull a fast one on Intel, you're delusional. Intel and Nvidia as well are very, very well aware of heterogeneous computing.
The_Countess - Wednesday, May 30, 2012 - link
looking at how much the performance per watt went up with piledriver compared with llano, I think they''ll have a lot more headroom on the desktop and server space to increase the clock frequencies to where they are suppose to be with the bulldozer launch.Homeles - Wednesday, May 30, 2012 - link
Yeah, Piledriver will likely perform the way AMD had intended Bulldozer to perform.