Apple iPhone 4S: Thoroughly Reviewed
by Anand Lal Shimpi & Brian Klug on October 31, 2011 7:45 PM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone
- iPhone 4S
GPU Performance Using Unreal Engine 3
In our iPad 2 review I called the PowerVR SGX 543MP2 Apple's gift to game developers. Apple boasted a roughly 9x improvement in raw GPU compute power over the A4 into the A5. The increase came through more execution resources and a higher GPU clock. The A5 in the iPhone 4S gets the same GPU, simply clocked lower than the iPad 2 version. Apple claims the iPhone 4S can deliver up to 7x the GPU performance of the iPhone 4, down from 9x in the iPad 2 vs. iPad 1 comparison. Why the delta?
The iPad 2 has both a larger battery and a higher resolution display. There are 28% more pixels to deal with on the iPad 2 vs the iPhone 4S and 9x vs 7x actually works out to be a 28% increase. The lower clocked GPU goes along with the lower clocked CPU in the 4S' version of the A5 to keep power consumption in check and because the platform doesn't need the performance as much as the iPad 2 with its higher resolution display.
| Mobile SoC GPU Comparison | |||||||||||
| Adreno 225 | PowerVR SGX 540 | PowerVR SGX 543 | PowerVR SGX 543MP2 | Mali-400 MP4 | GeForce ULP | Kal-El GeForce | |||||
| SIMD Name | - | USSE | USSE2 | USSE2 | Core | Core | Core | ||||
| # of SIMDs | 8 | 4 | 4 | 8 | 4 + 1 | 8 | 12 | ||||
| MADs per SIMD | 4 | 2 | 4 | 4 | 4 / 2 | 1 | ? | ||||
| Total MADs | 32 | 8 | 16 | 32 | 18 | 8 | ? | ||||
| GFLOPS @ 200MHz | 12.8 GFLOPS | 3.2 GFLOPS | 6.4 GFLOPS | 12.8 GFLOPS | 7.2 GFLOPS | 3.2 GFLOPS | ? | ||||
| GFLOPS @ 300MHz | 19.2 GFLOPS | 4.8 GFLOPS | 9.6 GFLOPS | 19.2 GFLOPS | 10.8 GFLOPS | 4.8 GFLOPS | ? | ||||
GLBenchmark continues to be our go-to guy for GPU performance under iOS. While there are other reputable 3D benchmarks, GLBench remains the only good cross-platform (iOS and Android) solution we have today.
The performance gains live up to Apple's expectations (Update: our original 4S for Egypt/Pro were incorrect. We had two sets of graphs, one internal and one external - the latter had incorrect data. We have since updated the charts to reflect the 4S' actual performance. Sorry for the mixup!):
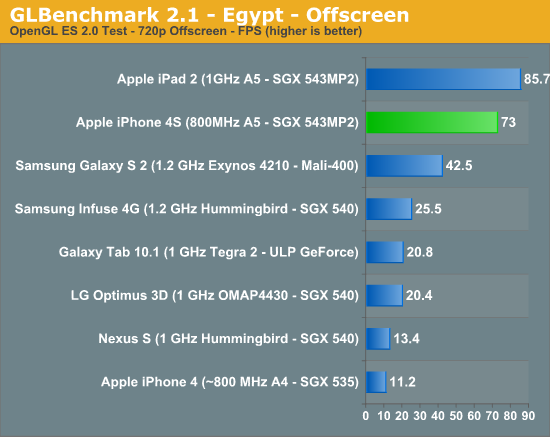
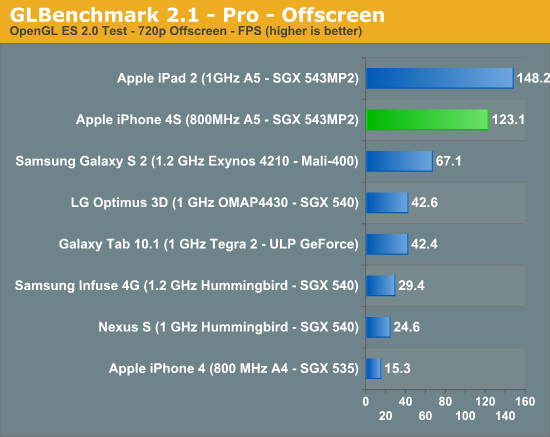
GLBenchmark gets around vsync by rendering offscreen, so the 4S is allowed to run as fast as it can. Here we see a 6.46x higher frame rate compared to the iPhone 4.
It's obvious that GLBenchmark is designed first and foremost to be bound by shader performance rather than memory bandwidth, otherwise all of these performance increases would be capped at 2x since that's the improvement in memory bandwidth from the 4 to the 4S. Note that we're clearly not overly bound by memory bandwidth in these tests if we scale pixel count by 50%, which is hardly realistic. Most games won't be shader bound, instead they should be more limited by memory bandwidth.
At the iPhone 4S introduction Epic was on stage showing off Infinity Blade 2, which will have new visual enhancements only present on the 4S thanks to its faster GPU. Thus far Epic has been using GPU performance improvements to make its games look better and not necessarily run faster (although they do) since the target is playability on all platforms. What I wanted however was a true apples-to-apples comparison using Epic's engine as it is arguably the best looking platform to develop iOS games on today.
Epic offers a free license to Unreal Engine 3 to anyone who wants to use it for non-commercial use. If you want to sell your UE3 based iOS game, you don't have to pay a large sum to license Epic's engine up front. Instead you toss Epic $99 and pay royalties (25%) on any revenue beyond the first $50K. It's a great deal for aspiring game developers since you get access to one of the best 3D engines around and don't need any additional startup capital to use it. If your game is a hit Epic gets a cut but you're still making money so all is good in the world.
The process starts with UDK, the Unreal Development Kit. Epic actually offers a great deal of documentation on developing using UDK, making the whole process extremely easy. The freely available UDK can target Windows, Mac OS X and iOS platforms. If you want Android support you'll have to pay to license the dev kit unfortunately. Given how successful Infinity Blade has been under iOS, I suspect this is a move partially designed to keep Apple happy. It's also possible the Android UE3 dev kit is simply not as far along as the iOS version.
Along with every UDK download, Epic now provides the full source code to its well known iOS Citadel demo. With access to Citadel's source code and Epic's excellent (and freely available) development tools I put together a real-world GPU test for iOS.
What's that? A frame counter in iOS? Huzzah!
The test shows us frame rate over the course of a flythrough of Epic's Citadel demo. This is simply the standard Citadel guided tour but with UE3's frame recording statistics enabled. Once again, UDK gave me the tools needed to accurately profile what was going on. For developers this would be helpful in tuning the performance of your app, but for me it gave me the one thing I've been hoping for: average frame rate in a UE3 game for iOS.
The raw data looks like this, a graph of frame render times:
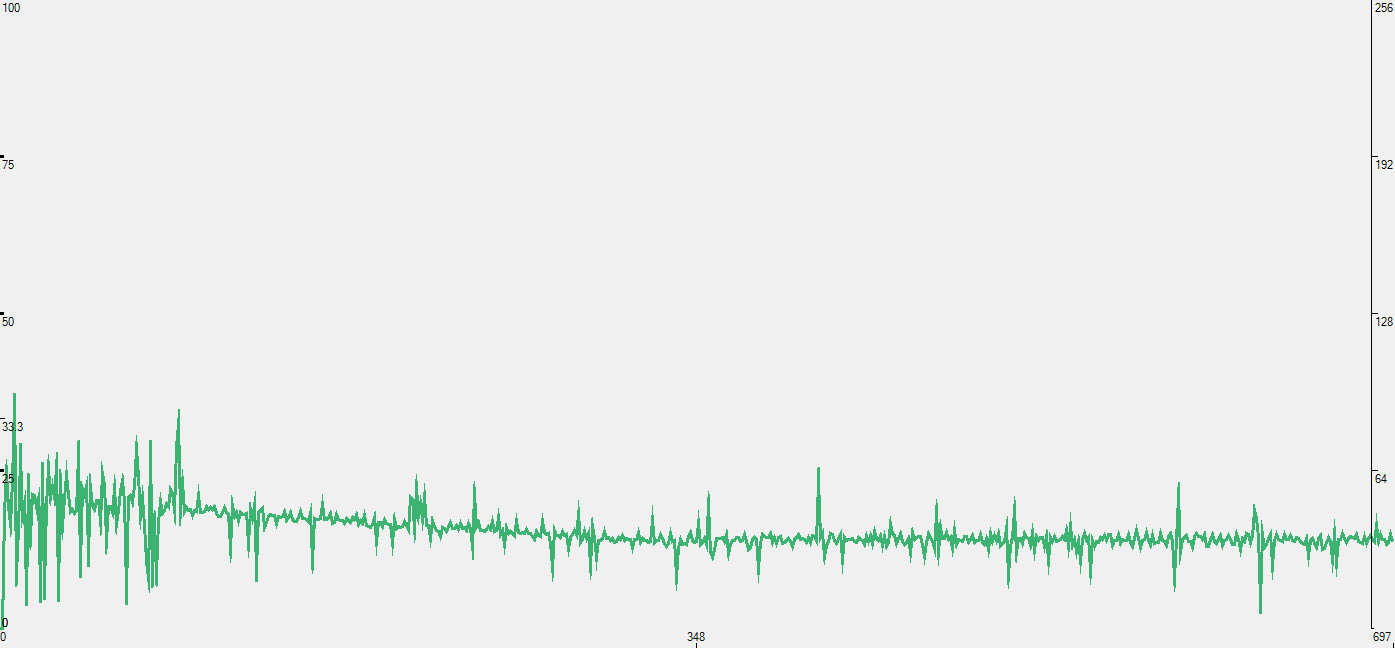
iPhone 4S frame time
You're looking at frame render time in ms, so lower numbers mean better performance. Notice how the iPhone 4S graph seems to remain mostly flat for the majority of the benchmark run? That's because it's limited by vsync. At 60Hz the frame render time is capped to 16.7ms, which is approximately where the 4S' curve flattens out to. The 4S could likely run through this demo even quicker (or maintain the same speed with a heavier graphical workload) if we had a way to disable vsync in iOS.
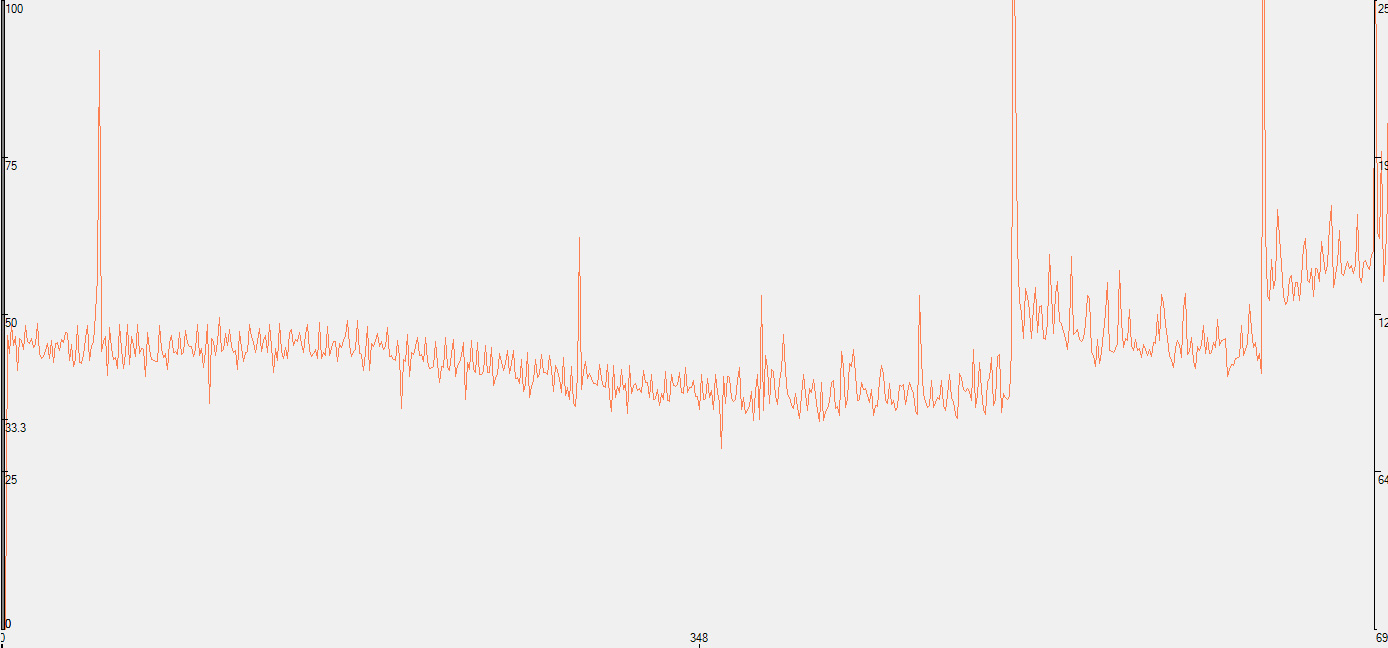
iPhone 4 frame time
On the iPhone 4 however, frame times are significantly higher - more than 2x on average. You also see significant spikes in frame time, indicating periods where the frame rate drops significantly. Not only does the 4S offer better average performance here but its performance is far more consistent, hugging vsync rather than wildly bouncing around.
The chart below summarizes the two graphs above by looking at the average frames rendered per second throughout the benchmark:
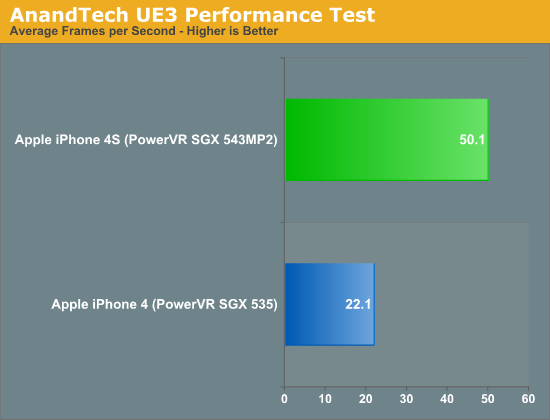
The iPhone 4S averages 2.3x the frame rate of the iPhone 4 throughout our test. I believe this gives us a more realistic value than the 6x we saw in GLBenchmark. A major cause for the difference is the vsync limitations present in all iOS apps that render to the screen. On top of that, while we're obviously not completely limited by memory bandwidth, it's clear that memory bandwidth does play a larger role here than it does in GLBenchmark.
The Citadel demo by default increases rendering quality on the iPhone 4, but a quick look at the game's configuration files didn't show any new features enabled for the 4S. Chances are the version of Citadel included with the UDK was built prior to the 4S being available. In other words, the 4 and 4S should be rendering the same workload in our benchmark. To confirm I also grabbed a couple of screenshots to ensure the two devices were running at the same settings:

iPhone 4

iPhone 4S
This is actually the most stressful scene in the level, it causes even the 4S to drop below 30 fps. With the camera stationary in roughly the same position I saw a 74% increase in performance on the 4S vs the iPhone 4.
Most game developers still target the iPhone 3GS, but the 4S allows them to significantly ramp up image quality without any performance penalty. Because of the lower hardware target for most iOS games and forced vsync I wouldn't expect to see 2x increases in frame rate for the 4S over the 4 in most games out today or in the near future. You can expect a smoother frame rate and better looking games if developers follow Epic's lead and simply enable more eye-candy on the 4S.








199 Comments
View All Comments
doobydoo - Friday, December 2, 2011 - link
Its still absolute nonsense to claim that the iPhone 4S can only use '2x' the power when it has available power of 7x.Not only does the iPhone 4s support wireless streaming to TV's, making performance very important, there are also games ALREADY out which require this kind of GPU in order to run fast on the superior resolution of the iPhone 4S.
Not only that, but you failed to take into account the typical life-cycle of iPhones - this phone has to be capable of performing well for around a year.
The bottom line is that Apple really got one over all Android manufacturers with the GPU in the iPhone 4S - it's the best there is, in any phone, full stop. Trying to turn that into a criticism is outrageous.
PeteH - Tuesday, November 1, 2011 - link
Actually it is about the architecture. How GPU performance scales with size is in large part dictated by the GPU architecture, and Imagination's architecture scales better than the other solutions.loganin - Tuesday, November 1, 2011 - link
And I showed it above Apple's chip isn't larger than Samsung's.PeteH - Tuesday, November 1, 2011 - link
But chip size isn't relevant, only GPU size is.All I'm pointing out is that not all GPU architectures scale equivalently with size.
loganin - Tuesday, November 1, 2011 - link
But you're comparing two different architectures here, not two carrying the same architecture so the scalability doesn't really matter. Also is Samsung's GPU significantly smaller than A5's?Now we've discussed back and forth about nothing, you can see the problem with Lucian's argument. It was simply an attempt to make Apple look bad and the technical correctness didn't really matter.
PeteH - Tuesday, November 1, 2011 - link
What I'm saying is that Lucian's assertion, that the A5's GPU is faster because it's bigger, ignores the fact that not all GPU architectures scale the same way with size. A GPU of the same size but with a different architecture would have worse performance because of this.Put simply architecture matters. You can't just throw silicon at a performance problem to fix it.
metafor - Tuesday, November 1, 2011 - link
Well, you can. But it might be more efficient not to. At least with GPU's, putting two in there will pretty much double your performance on GPU-limited tasks.This is true of desktops (SLI) as well as mobile.
Certain architectures are more area-efficient. But the point is, if all you care about is performance and can eat the die-area, you can just shove another GPU in there.
The same can't be said of CPU tasks, for example.
PeteH - Tuesday, November 1, 2011 - link
I should have been clearer. You can always throw area at the problem, but the architecture dictates how much area is needed to add the desired performance, even on GPUs.Compare the GeForce and the SGX architectures. The GeForce provides an equal number of vertex and pixel shader cores, and thus can only achieve theoretical maximum performance if it gets an even mix of vertex and pixel shader operations. The SGX on the other hand provides general purpose cores that work can do either vertex or pixel shader operations.
This means that as the SGX adds cores it's performance scales linearly under all scenarios, while the GeForce (which adds a vertex and a pixel shader core as a pair) gains only half the benefit under some conditions. Put simply, if a GeForce core is limited by the number of pixel shader cores available, the addition of a vertex shader core adds no benefit.
Throwing enough core pairs onto silicon will give you the performance you need, but not as efficiently as general purpose cores would. Of course a general purpose core architecture will be bigger, but that's a separate discussion.
metafor - Tuesday, November 1, 2011 - link
I think you need to check your math. If you double the number of cores in a Geforce, you'll still gain 2x the relative performance.Double is a multiplier, not an adder.
If a task was vertex-shader bound before, doubling the number of vertex-shaders (which comes with doubling the number of cores) will improve performance by 100%.
Of course, in the case of 543MP2, we're not just talking about doubling computational cores.
It's literally 2 GPU's (I don't think much is shared, maybe the various caches).
Think SLI but on silicon.
If you put 2 Geforce GPU's on a single die, the effect will be the same: double the performance for double the area.
Architecture dictates the perf/GPU. That doesn't mean you can't simply double it at any time to get double the performance.
PeteH - Tuesday, November 1, 2011 - link
But I'm not talking about relative performance, I'm talking about performance per unit area added. When bound by one operation adding a core that supports a different operation is wasted space.So yes, doubling space always doubles relative performance, but adding 20 square millimeters means different things to the performance of different architectures.