Samsung Galaxy S 2 (International) Review - The Best, Redefined
by Brian Klug & Anand Lal Shimpi on September 11, 2011 11:06 AM EST- Posted in
- Smartphones
- Samsung
- Galaxy S II
- Exynos
- Mobile
Understanding Rendering Techniques
It's been years since I've had to describe the differences in rendering techniques but given the hardware we're talking about today it's about time for a quick refresher. Despite the complexities involved in CPU and GPU design, both processors work in a manner that's pretty easy to understand. The GPU fundamentally has one function: to determine the color of each pixel displayed on the screen for a given frame. The input the GPU receives however is very different from a list of pixel coordinates and colors.
A 3D application or game will first provide the GPU with a list of vertex coordinates. Each set includes the coordinates for three vertices in space, these describe the size, shape and position of a triangle. A single frame is composed of hundreds to millions of these triangles. Literally everything you see on screen is composed of triangles:
Having more triangles (polygons) can produce more realistic scenes but it requires a lot more processing on the front end. The trend in 3D gaming has generally been towards higher polygon counts over time.
The GPU's first duty is to take this list of vertices and convert them into triangles on a screen. Doing so results in a picture similar to what we've got above. We're dealing with programmable GPUs now so its possible to run code against these vertexes to describe their interactions or effects on them. An explosion in an earlier frame may have caused the vertices describing a character's elbow to move. The explosion will also impact lighting on our character. There's going to be a set of code that describes how the aforementioned explosion impacts vertices and another snippet of code that describes what vertices it impacts. These code segments run and modify details of the vertices at this stage.
With the geometry defined the GPU's next job is rasterization: figure out what pixels cover each triangle. From this point on the GPU stops dealing in vertices and starts working in pixel coordinates.
Once rasterized, it's time to give these pixels some color. The color of each pixel is determined by the texture that covers that pixel and/or the pixel shader program that runs on that pixel. Similar to vertex shader programs, pixel shader programs describe effects on pixels (e.g. flicker bright orange at interval x to look like fire).
Textures are exactly what they sound like: wallpaper for your polygons. Knowing pixel coordinates the GPU can go out to texture memory, fetch the texture that maps to those pixels and use it to determine the color of each pixel that it covers.
There's a lot of blending and other math that happens at this stage to deal with corner cases where you don't have perfect mapping of textures on polygons, as well as dealing with what happens when you've got translucency in your textures. After you get through all of the math however the GPU has exactly what it wanted in the first place: a color value for every pixel on the screen.
Those color values are written out to a frame buffer in memory and the frame buffer is displayed on the screen. This process continues (hopefully) dozens of times per second in order to deliver a smooth visual experience.
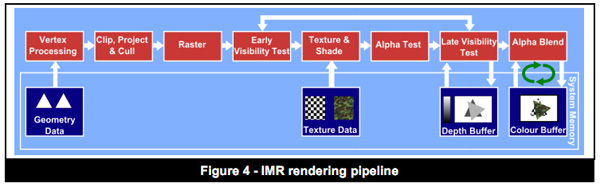
The pipeline I've just described is known as an immediate mode renderer. With a few exceptions, immediate mode renderers were the common architectures implemented in PC GPUs over the past 10+ years. These days pure immediate mode renderers are tough to find though.

IMRs render the full car and the tree, even though part of the car is occluded
Immediate mode renderers (IMRs) brute force the problem of determining what to draw on the screen. They take polygons as they receive them from the CPU, manipulate and shade them. The biggest problem here is although data for every polygon is sent to the GPU, some of those polygons will never be displayed on the screen. A character with thousands of polygons may be mostly hiding behind a pillar, but a traditional immediate mode renderer will still put in all of the work necessary to plot its geometry and shade its pixels, even though they'll never be seen. This is called overdraw. Overdraw unfortunately wastes time, memory bandwidth and power - hardly desirable when you're trying to deliver high performance and long battery life. In the old days of IMRs it wasn't uncommon to hear of 4x overdraw in a given scene (i.e. drawing 4x the number of pixels than are actually visible to the user). Overdraw becomes even more of a problem with scene complexity.
Tile Based Deferred Rendering
On the opposite end of the spectrum we have tile based deferred rendering (TBDR). Immediate mode renderers work in a very straightforward manner. They take vertices, create polygons, transform and light those polygons and finally texture/shade/blend the pixels on them. Tile based deferred renderers take a slightly different approach.

TBDRs subdivide the scene into smaller tiles on the order of a few hundred pixels. Vertex processing and shading continue as normal, but before rasterization the scene is carved up into tiles. This is where the deferred label comes in. Rasterization is deferred until after tiling and texturing/shading is deferred even longer, until after overdraw is eliminated/minimized via hidden surface removal (HSR).
Hidden surface removal is performed long before we ever get to the texturing/shading stage. If the frontmost surface being rendered is opaque, there's absolutely zero overdraw in a TBDR architecture. Everything behind the frontmost opaque surface is discarded by performing a per-pixel depth test once the scene has been tiled. In the event of multiple overlapping translucent surfaces, overdraw is still minimized. Only surfaces above the farthest opaque surface are rendered. HSR is performed one tile at a time, only the geometry needed for a single tile is depth tested to keep the problem manageable.
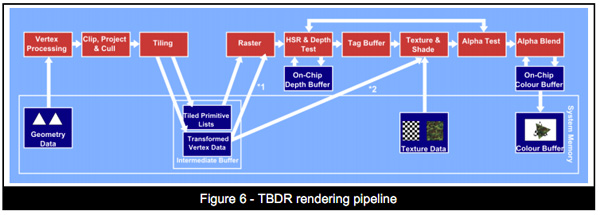
With all hidden surfaces removed then, and only then, is all texture data fetched and all pixel shader code executed. Rendering (or more precisely texturing and shading) is deferred until after a per-pixel visibility test is passed. No additional work is expended and no memory bandwidth wasted. Only what is visible in the final scene is rasterized, textured and shaded on each tile.
The application doesn't need to worry about the order polygons are sent for rendering when dealing with a TBDR, the hidden surface removal process takes care of everything.
In memory bandwidth constrained environments TBDRs do incredibly well. Furthermore, the efficiencies of a TBDR really shine when running applications and games that are more shader heavy rather than geometry heavy. As a result of the extensive hidden surface removal process, TBDRs tend not to do as well in scenes with lots of complex geometry.
What's In Between Immediate Mode and Deferred Rendering?
These days, particularly in the mobile space, many architectures refer to themselves as "tile based". Unfortunately these terms can have a wide variety of meanings. The tile based deferred rendering architecture I described above really only applies to GPUs designed by Imagination Technologies. Everything else falls into the category of tile based immediate mode renderers, or immediate mode renderers with early-z.
These GPUs look like IMRs but they implement one or both of the following: 1) scene tiling, 2) early z rejection.
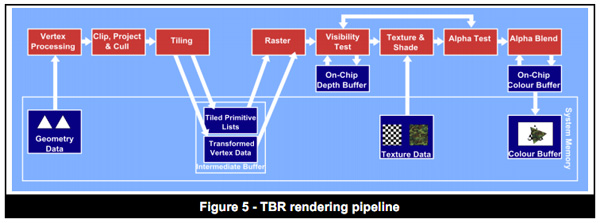
Scene tiling is very similar to what I described in the section on TBDRs. Each frame is divided up into tiles and work is done on a per-tile basis at some point in the rendering pipeline. The goal of dividing the scene into tiles is to simplify the problem of rendering and better match the workload to the hardware (e.g. since no GPU is a million execution units wide, you make the workload more manageable for your hardware). Also by working on small tiles caches behave a lot better.
The big feature that this category of GPUs implements is early-z rejection. Instead of waiting until after the texturing/shading stage to determine pixel visibility, these architectures implement a coarse test for visibility earlier in the pipeline.
Each vertex has a depth value and using those values you can design logic to find out what polygons (or parts of polygons) are occluded from view. GPU makers like ATI and NVIDIA introduced these early visibility tests years ago (early-z or hierarchical-z are some names you may have heard). The downside here is that early-z techniques only work if the application submits vertices in a front-to-back order, which does require extra work on the application side. IMRs process polygons in the order they're received, and you can't reject anything if you're not sure if anything will be in front of it. Even if an application packages up vertex data in the best way possible, there are still situations where overdraw will occur.
The good news is you get some of the benefits of a TBDR without running into trouble should geometry complexities increase. The bad news is that a non-TBDR architecture will still likely have higher amounts of overdraw and be less memory bandwidth efficient than a TBDR.
Most modern PC GPUs fall into this category. Both NVIDIA's Fermi and AMD's Cayman GPUs do some amount of tiling although they have their roots in immediate mode rendering.
The Mobile Landscape
Understanding the difference between IMRs, IMRs with early-z, TBRs and TBDRs, where do the current ultra mobile GPUs fall? Imagination Technologies' PowerVR SGX 5xx is technically the only tile based deferred renderer that allows for order independent hidden surface removal.
Qualcomm's Adreno 2xx and ARM's Mali-400 both appear to be tile based immediate mode renderers that implement early-z. This is particularly confusing because ARM lists the Mali-400 as featuring "advanced tile-based deferred rendering and local buffering of intermediate pixel states". The secret is in ARM's optimization documentation that states: "One specific optimization to do for Mali GPUs is to sort objects or triangles into front-to-back order in your application. This reduces overdraw." The front-to-back sort requirement is necessary for most early-z technologies to work properly. These GPUs fundamentally tile the scene but don't perform full order independent hidden surface removal. Some aspects of the traditional rendering pipeline are deferred but not to the same extent as Imagination's design.
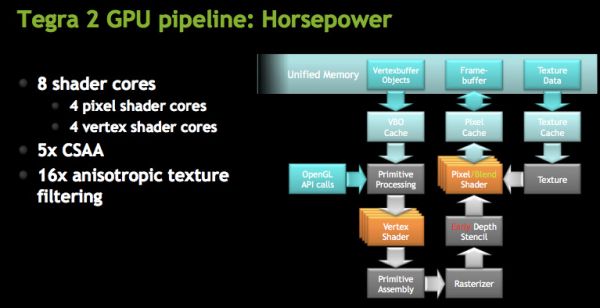
NVIDIA's GeForce ULP in the Tegra 2 is an IMR with early-z. NVIDIA has long argued that its design is the best for future games with increasing geometry complexities as a result of its IMR design.
Today there's no real benefit to not building a TBDR in the ultra mobile space. Geometry complexities aren't very high and memory bandwidth does come at a premium. Moving forward however, the trend is likely going to mimic what we saw in the PC space: towards more polygon heavy games. There is one hiccup though: Apple.

In the evolution of the PC graphics industry the installed base of tile based deferred renderers was extremely small. Imagination's technology surfaced in two discrete GPUs: STMicro's Kyro and Kyro II, but neither was enough to stop NVIDIA's momentum at the time. Since immediate mode renderers were the norm, games simply developed around their limitations. AMD and NVIDIA both eventually implemented elements of tiling and early-z rejection, but TBDRs never took off in PCs.
In the ultra mobile space Apple exclusively uses Imagination Technologies GPUs, which I mentioned above are tile based deferred renderers. Apple also happens to be a major player, if not the biggest, in the smartphone/tablet gaming space today. Any game developer looking to put out a successful title is going to make sure it runs well on iOS hardware. Game developers will likely rely on increasing visual quality through pixel shader effects rather than ultra high polygon counts. As long as Imagination Technologies is a significant player in this space, game developers will optimize for TBDRs.








132 Comments
View All Comments
kreacher - Monday, September 12, 2011 - link
I was disappointed to see that there is no mention of the screen 's inability to display 24bit gradients while Samsung claims its a screen capable of displaying 16M colors.supercurio - Monday, September 12, 2011 - link
See my answer for Astri.Maybe you only checked a gradient in Web Browser or a specific app that forces 16bit surfaces.
Each app has the ability to choose how the rendering is done in this regard.
Internally, the Super AMOLED controller works in much more than 24bit in order to proceed to complex color-space conversions between the a digital frame buffer and an analog, very large dynamic range OLEDs.
lemmo - Monday, September 12, 2011 - link
Great review, and incredible detail on the audio quality. Shame the SGS2 has taken a step backwards on audio. Any info on the likely spec for the audio on the Samsung Nexus Prime?Also, any recommendations on reviews of best smartphones for audio quality? cheers :)
supercurio - Monday, September 12, 2011 - link
Thanks for the feedback!I really need it in order to improve next review.
Organize it differently for better readability, maybe evaluate other aspects as well (like recording)
I have no info about what's in Nexus Prime but I'd like to :P
If somebody can send me a report: https://market.android.com/details?id=org.projectv... I'll study it.
Best devices I know in terms of audio quality:
- with Voodoo Sound: Nexus S, Galaxy S family, Galaxy Tab 7".
- with or without Voodoo sound: Asus Transformer
- soon with Voodoo Sound: Galaxy Tab 10.1 (incredible power stage for the headphone amp)
- iPhones/iPad: clean DAC but boring headphone amp (unable to drive many cans to adequate levels)
And.. many I don't know! (yet?)
lemmo - Wednesday, September 14, 2011 - link
Thanks supercurio, very helpful. I'll keep looking for more info on the Nexus Prime.Shame none of the other phones/tablets you mention have got the right spec for me.
In practice, do you think the 'average user' will notice the poorer audio quality on the SGS2?
yellowchilli - Monday, September 12, 2011 - link
a very very good read thank youi've owned the sgs2 since its EU launch..it's interesting to see the slight differences/improvements samsung has put into the US release (e.g. the power button, camera ui)
mcquade181 - Monday, September 12, 2011 - link
I've had my SGS2 here in Australia for two months now and on a recent snow trip noticed some deficiencies compared to my friends Nokia N8. We both use the same provider (Telstra 3G on 850MHz):1. Whilst travelling there were periods where I completely lost reception whereas the N8 still had a signal and was able to make calls. This suggests that the SGS2 is a bit lacking in cellular sensitivity (and note that the N8 is not all that flash either when compared to the old Nokia N95).
2. In our snow accomodation I could not get a reliable WiFi signal from the local hotspot whereas the N8 could (it was marginal, but it did work).
3. Bluetooth on the SGS2 is unreliable with some devices. It keeps disconnecting after a few minutes.
That said I do like my SGS2 and is better in many other ways to the Nokia N8 - in particular earphone volume and call clarity where the N8 is deficient. Of course android has a much wider selection of available apps than does the Nokia, although surprisingly ALL my favourite apps are also available for the Nokia.
Regards from down under, Graham Rawolle.
willstay - Monday, September 12, 2011 - link
What a coincidence. After two Androids, I actually bought N8 and later sold it to get SGS2. Before Belle, swype was only available in landscape and my must-have apps are not there for Symbian.jcompagner - Tuesday, September 13, 2011 - link
yes that is the only drawback i also can find of the SGS2..Wifi reception is really not up to standards.
kmmatney - Monday, September 12, 2011 - link
I'm not happy with the battery tests - they don't show real life usage. I'd still like to know what happens with the battery if you just leave the phone in your pocket for most of the day, or what happens if you leave it in standby overnight. All of my co-workers complain about battery life with their Android phones, and all want to get iPhones the next time around. The batteries seem to drain excessively with the phones doing nothing, and they are often dead when they go to use them. Who cares if you can browse the web for 7 hours or whatever...I just want the phone to be ready to use if its been sitting on my desk for half the day, or if I forget to charge it overnight. This is way more important - at least for someone like me who travels. (actually, I work a lot in wafer fabs around the world, and crappy reception in the fabs often drain battery quickly).I guess it will depend on what Apps are installed, and you use push notifications, but it would be useful to have a test where you charge the phone, and then let it sit for 8 hours doing nothing, and then report the battery life. The older Android phones seemed terrible at this, while my iPhone 3GS is great.
This phone looks awesome, but I would need this information before I would consider buying it.