AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute
by Ryan Smith on December 21, 2011 9:38 PM ESTMany SIMDs Make One Compute Unit
When we move up a level we have the Compute Unit, what AMD considers the fundamental unit of computation. Whereas a single SIMD can execute vector operations and that’s it, combined with a number of other functional units it makes a complete unit capable of the entire range of compute tasks. In practice this replaces a Cayman SIMD, which was a collection of Cayman SPs. However a GCN Compute Unit is capable of far, far more than a Cayman SIMD.
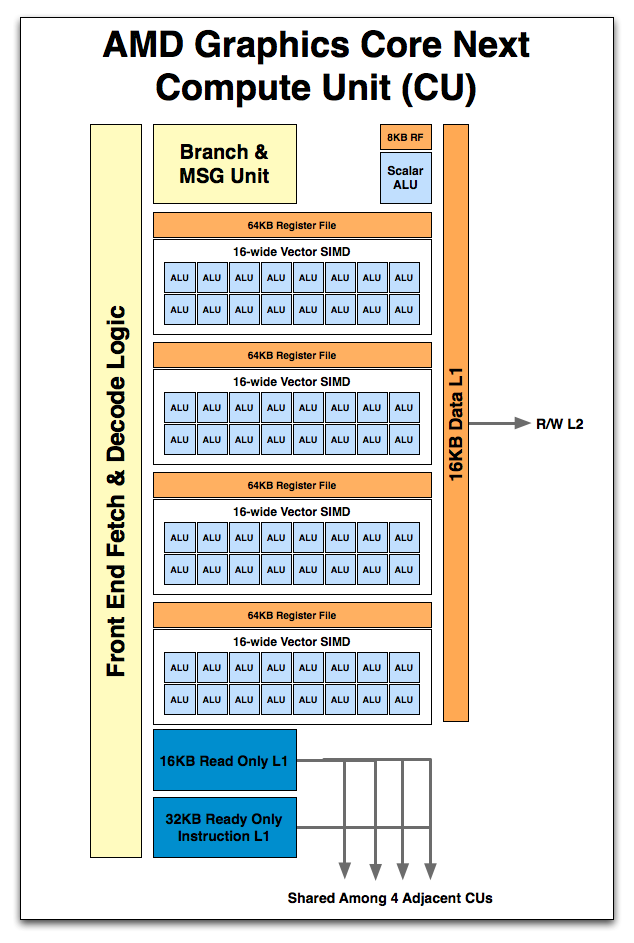
So what’s in a Compute Unit? Just as a Cayman SIMD was a collection of SPs, a Compute Unit starts with a collection of SIMDs. 4 SIMDs are in a CU, meaning that like a Cayman SIMD, a GCN CU can work on 4 instructions at once. Also in a Compute Unit is the control hardware & branch unit responsible for fetching, decoding, and scheduling wavefronts and their instructions. This is further augmented with a 64KB Local Data Store and 16KB of L1 data + texture cache. With GCN data and texture L1 are now one and the same, and texture pressure on the L1 cache has been reduced by the fact that AMD is now keeping compressed rather than uncompressed texels in the L1 cache. Rounding out the memory subsystem is access to the L2 cache and beyond. Finally there is a new unit: the scalar unit. We’ll get back to that in a bit.
But before we go any further, let’s stop here for a moment. Now that we know what a CU looks like and what the weaknesses are of VLIW, we can finally get to the meat of the issue: why AMD is dropping VLIW for non-VLIW SIMD. As we mentioned previously, the weakness of VLIW is that it’s statically scheduled ahead of time by the compiler. As a result if any dependencies crop up while code is being executed, there is no deviation from the schedule and VLIW slots go unused. So the first change is immediate: in a non-VLIW SIMD design, scheduling is moved from the compiler to the hardware. It is the CU that is now scheduling execution within its domain.
Now there’s a distinct tradeoff with dynamic hardware scheduling: it can cover up dependencies and other types of stalls, but that hardware scheduler takes up die space. The reason that the R300 and earlier GPUs were VLIW was because the compiler could do a fine job for graphics, and the die space was better utilized by filling it with additional functional units. By moving scheduling into hardware it’s more dynamic, but we’re now consuming space previously used for functional units. It’s a tradeoff.
So what can you do with dynamic scheduling and independent SIMDs that you could not do with Cayman’s collection of SPs (SIMDs)? You can work around dependencies and schedule around things. The worst case scenario for VLIW is that something scheduled is completely dependent or otherwise blocking the instruction before and after it – it must be run on its own. Now GCN is not an out-of-order architecture; within a wavefront the instructions must still be executed in order, so you can’t jump through a pixel shader program for example and execute different parts of it at once. However the CU and SIMDs can select a different wavefront to work on; this can be another wavefront spawned by the same task (e.g. a different group of pixels/values) or it can be a wavefront from a different task entirely.
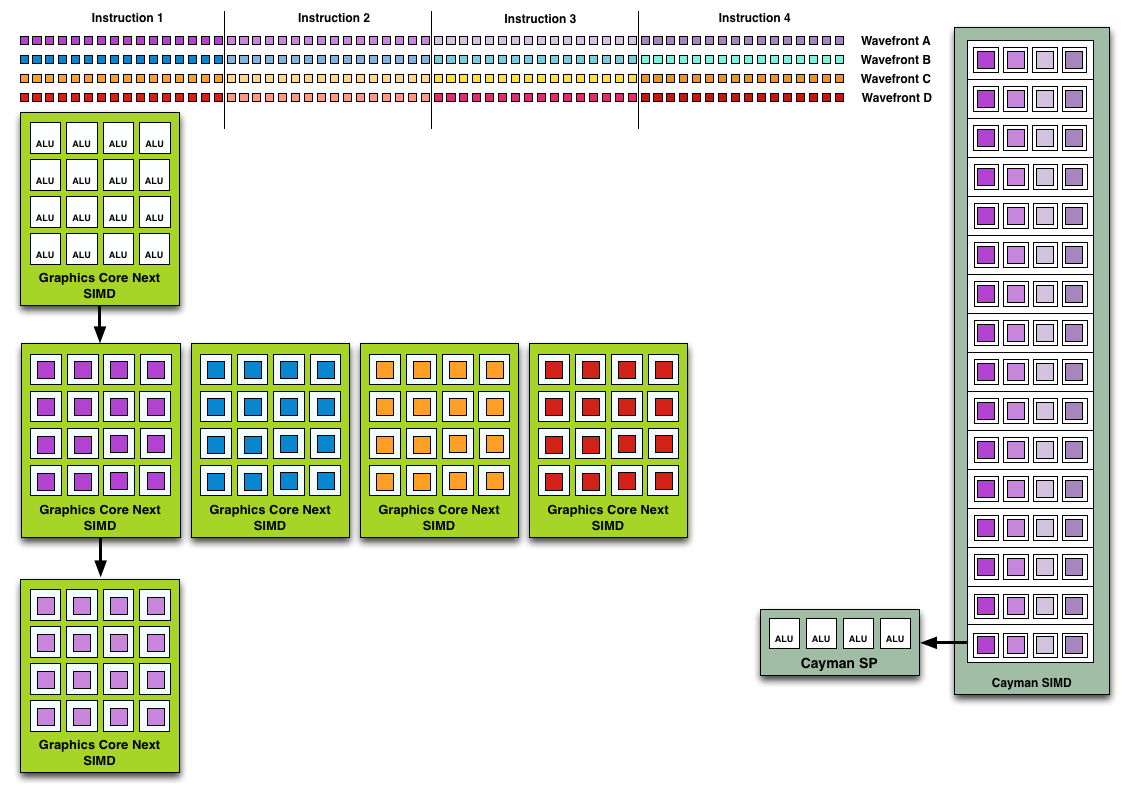
Wavefront Execution Example: SIMD vs. VLIW. Not To Scale - Wavefront Size 16
Cayman had a very limited ability to work on multiple tasks at once. While it could consume multiple wavefronts from the same task with relative ease, its ability to execute concurrent tasks was reliant on the API support, which was limited to an extension to OpenCL. With these hardware changes, GCN can now concurrently work on tasks with relative ease. Each GCN SIMD has 10 wavefronts to choose from, meaning each CU in turn has up to a total of 40 wavefronts in flight. This in a nutshell is why AMD is moving from VLIW to non-VLIW SIMD for Graphics Core Next: instead of VLIW slots going unused due to dependencies, independent SIMDs can be given entirely different wavefronts to work on.
As a consequence, compiling also becomes much easier. With the compiler freed from scheduling tasks, compilation behaves in a rather standard manner, since most other architectures are similarly scheduled in hardware. Writing a compiler still isn’t absolutely easy, but when it comes to optimizing the execution of a program the compiler can focus on other matters, making it much easier for other languages to target GCN. In fact without the need to generate long VLIW instructions or to including scheduling information, the underlying ISA for GCN is also much simpler. This makes debugging much easier since the code generated reflects the fact that scheduling is now done in hardware, which is reflected in our earlier assembly code example.
Now while leaving behind the drawbacks of VLIW is the biggest architectural improvement for compute performance coming from Cayman, the move to non-VLIW SIMDs is not the only benefit. We still have not discussed the final component of the CU: the Scalar ALU. New to GCN, the Scalar unit serves to further keep inefficient operations out of the SIMDs, leaving the vector ALUs on the SIMDs to execute instructions en mass. The scalar unit is composed of a single scalar ALU, along with an 8KB register file.
So what does a scalar unit do? First and foremost it executes “one-off” mathematical operations. Whole groups of pixels/values go through the vector units together, but independent operations go to the scalar unit as to not waste valuable SIMD time. This includes everything from simple integer operations to control flow operations like conditional branches (if/else) and jumps, and in certain cases read-only memory operations from a dedicated scalar L1 cache. Overall the scalar unit can execute one instruction per cycle, which means it can complete 4 instructions over the period of time it takes for one wavefront to be completed on a SIMD.
Conceptually this blurs a bit more of the remaining line between a scalar GPU and a vector GPU, but by having both types of units it means that each unit type can work on the operations best suited for it. Besides avoiding feeding SIMDs non-vectorized datasets, this will also improve the latency for control flow operations, where Cayman had a rather nasty 44 cycle latency.








83 Comments
View All Comments
haplo602 - Saturday, June 18, 2011 - link
I hope that AMD delivers. This is exactly what I expected them to do once Llano was anounced. GPU as a coprocessor. Actualy I hoped that AMD would implement a HTX capable GPU, so I can just plug it into a C32 socket (for example) along with an Opteron.The future past Trinity looks interesting.
jamescox - Monday, June 20, 2011 - link
It would be interesting if they produced a form factor with CPU+GPU on a separate card with memory. Ever since AMD moved the memory controller on die, I wondered if we would see CPU + memory on a separate card. It seems to make a lot of sense. A 4 socket motherboard is huge, especially where each socket has 4 to 6 memory slots associated with it. If the CPU and memory were on a separate card, then you could pack them a lot denser, like you can run 4 GPUs off an ATX board now. It might be cheaper than a massive 4 socket board also. I don't know how many HT links you can run through a slot, but you could always use extra cables/connectors like they use for multiple graphics cards.With the GPU using the same memory space as the CPU, then why leave the CPU attached to the slow system memory? Just put one of these hybrid chips attached to some high-speed graphics card like memory on a separate board. Move the slow system memory out to the chipset again. The current memory hierarchy is not exactly optimal in my opinion. I am using a slightly older macbook pro, which only supports 3 GB of memory. With all of the stuff I run, it is paging a lot to a super slow laptop hard drive. I have been tempted to get an SSD to speed it up rather than a new laptop.
Anyway, with the way the memory hierarchy works now, system memory is kind of like a cache for the swap space on disk. System memory has gotten a lot faster, but disk have not, so people are using SSDs to fill the gap. If you directly connect the "graphics memory" to a CPU/GPU combo, then you don't need as much total memory in the system because you would not need multiple copies of the data. You would just pass pointers to data back and forth between the CPU and GPU components.
Also, it would be nice to switch to something non-volatile for the memory connected to the chipset; just use disk as mass storage only. "System" memory wouldn't need to be that fast, since you would probably have a GB or two of high-speed memory on each processor board. The "system" memory would be used more like the SSD boot/swap drive in a current system. I don't think flash is quite there yet, and the other types of non-volatile memory (magnetic RAM , phase-shift RAM, etc) that promise much better performance and durability seem to still be all talk with no real products.
With keeping the current form factor, it would be nice if they could put a large amount of memory in with the CPU/GPU package to act as high-speed memory for the GPU and L4 cache for the CPU. This form factor doesn't support scaling up to multiple chips easily (too large of main-board), but it would be very power efficient for laptops and other small form factor systems. It would require very little off-module communication which saves a lot of power. Maybe they could use a low-power, wide-interface dram chip originally meant for mobile devices.
Hopefully Trinity is more than just a meaningless code name...
Quantumboredom - Sunday, June 19, 2011 - link
On page 4 ("Many SIMDs Make One Compute Unit") there are two figures showing wavefront scheduling on VLIW4 versus GCN. As I read it the figures seem to indicate that in VLIW4, one 4-wide VLIW handles operations from four wavefronts in parallel, but that's not how I've understood AMD's VLIW4. Only a single work-item is executing on a VLIW4-core at any point in time, the occupancy problems of VLIW4 come from ILP within a work-item, not across wavefronts.At any one point in time, a Cayman/VLIW4 compute unit is only executing instructions from a single wavefront (though they need at least two wavefronts to switch between on VLIW4). Again at any one point in time only 16 work-items are actually being executed, and it's within those 16 work-items that ILP must be extraced to fill the VLIW4 units. Since each work-item is executing on a VLIW4-processor, a total of 16*4=64 operations can be done in parallel, but that requires ILP within the work-items.
On GCN this is quite different, where the four 16-wide vector units are actually executing 64 work-items at a time (four times as many as in Cayman). However the point is that each of these work-items are basically executing on a scalar processor, there's no need for ILP anymore. So again we are executing 64 operations in parallel, but now without any need for ILP.
At least this is how I understood the presentation (I was at AFDS). Basically I agree with how the GCN scheduling is illustrated in this article, but the Cayman part looks wrong to me. A Cayman CU can only execute one wavefront at a time, and it only needs two wavefronts to switch between to be able to fully utilize the hardware, not four like the figures here seem to suggest.
Now I'm just a programmer, not an architecture guy, so if anyone could clear this up for me it would be greatly appreciated :)
Ryan Smith - Monday, June 20, 2011 - link
Hi Quantum;After further consideration you're basically right. I should have made a distinction in the figures between instructions and wholly distinct wavefronts. While there are some ILP considerations to be had, basically the elements Cayman accepts should all be instructions from the same wavefront rather than different wavefronts. Cayman can't really work on multiple wavefronts at once.
I don't have the original files on me, but we'll get this fixed in the morning to show that Cayman is consuming multiple instructions from the same wavefront.
-Thanks
Ryan Smith
jamescox - Monday, June 20, 2011 - link
Would a CPU/GPU integrated chip only be a replacement for integrated graphics, or does it have the possibility to move a little farther up? With multi-threading, 4 to 8 thread CPUs will be common in the mainstream, but that will not be a very big die on smaller processes. Most PC software doesn't make use of more than 4 compute intensive threads, so how much room does that leave for GPU hardware? If they solve the memory speed problem by integrating some high-speed memory into the socket (multi-chip module), or something, then it seems like they could possibly get more mainstream performance out of an integrated chip.
If the integrated GPU isn't being used for graphics, then I really don't see that much software that would use it for compute in the PC space. One of the main things mentioned was usually video encode/decode, but it seems that the best solution is to include specific media encode/decode hardware like sandy bridge does. It seems to be just as fast and much more power efficient. If AMD doesn't include a media processing engine, then that could still be a reason to go with Intel. What other PC software could use the compute power?
There is plenty of software that could use it in professional/HPC markets, so it makes sense to make a GPU that can be used for both if it doesn't sacrifice the graphics performance. The newest generations of GPUs have some things in common with Larrabee and Sony's Cell processors, except both of those tried to move too much of the graphics processing abilities into software. AMD didn't make that mistake, but talk of compute abilities for GPUs in the PC/consumer space seems a bit premature without any real applications to take advantage of it.
GaMEChld - Monday, June 20, 2011 - link
Llano already has low level discrete GPU performance, and that's just the tip of the iceberg. You are correct that on smaller processes they will be able to allocate more space to the GPU while maintaining CPU performance. I believe the successor to Trinity (which is the Bulldozer based successor to Llano) is supposed to be on 28nm. If everything goes exactly right, you could potentially have some kind of monster that has i5-2500K CPU performance with Radeon 6800 GPU performance in some maintstream laptop chip a year or two down the road. (Those numbers are all pure speculation)I encourage everyone to take a moment and remember the first computer you ever used, just to pay homage to what we are capable of as a species in just a few short years.
I remember an IBM computer flipped on by a big red toggle that took 2 minutes to boot to a dos prompt...
Targon - Monday, June 20, 2011 - link
I remember the Timex Sinclaire, with 2KB of memory standard hooked up to a black and white TV and cassette tapes to save/load programs. Z80 running at 1MHz...the old 5.25 inch floppies were MUCH better, at least you could get a list of what was on the storage medium without having to load it.jabber - Monday, June 20, 2011 - link
If only our attitudes to each other and other issues had advanced as much as well.GaMEChld - Monday, June 20, 2011 - link
"Because in the end, aren't all religions the same? They tell us what to eat, when to pray, that this lump of clay called Man can somehow shape himself to resemble the divine. But we can never attain that perfect grace if we have hatred in our hearts. So let us celebrate our commonalites. Some of us don't eat pork. Some of us don't eat shellfish. But we all eat chicken. So spread the word: peace and chicken!"~HOMER SIMPSON
:-D
Cyber.Angel - Saturday, October 15, 2011 - link
off-topic?7th day Adventist don't eat meat, yes, not even chicken
AND
in Christian religion it's God who sacrifices, not human
PLUS
there is a requirement of TOTAL change according to Jesus
That is, the "ME" is buried, forgotten and God lives inside of you
meaning a total change in life
God bless America - but...where is the change?