AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute
by Ryan Smith on December 21, 2011 9:38 PM ESTFinal Words
As GPUs have increased in complexity, the refresh cycle has continued to lengthen. 6 month cycles have largely given way to 1 year cycles, and even then it can be 2+ years between architecture refreshes. This is not only a product of the rate of hardware development, but a product of the need to give developers time to breathe and to absorb information about new architectures.
The primary purpose of the AMD Fusion Developer Summit and the announcement of the AMD Graphics Core Next is to give developers even more time to breathe by extending the refresh window backwards as well as forwards. It can take months to years to deliver a program, so the sooner an architecture is introduced the sooner a few brave developers can begin working on programs utilizing it; the alternative is that it may take years after the launch of a new architecture before programs come along that can fully exploit the new architecture. One only needs to take a look at the gaming market to see how that plays out.
Because of this need to inform developers of the hardware well in advance, while we’ve had a chance to see the fundamentals of GCN products using it are still some time off. At no point has AMD specified when a GPU will appear using GCN will appear, so it’s very much a guessing game. What we know for a fact is that Trinity – the 2012 Bulldozer APU – will not use GCN, it will be based on Cayman’s VLIW4 architecture. Because Trinity will be VLIW4, it’s likely-to-certain that AMD will have midrange and low-end video cards using VLIW4 because of the importance they place on being able to Crossfire with the APU. Does this mean AMD will do another split launch, with high-end parts using one architecture while everything else is a generation behind? It’s possible, but we wouldn’t make at bets at this point in time. Certainly it looks like it will be 2013 before GCN has a chance to become a top-to-bottom architecture, so the question is what the top discrete GPU will be for AMD by the start of 2012.
Moving on, it’s interesting that GCN effectively affirms most of NVIDIA’s architectural changes with Fermi. GCN is all about creating a GPU good for graphics and good for computing purposes; Unified addressing, C++ capabilities, ECC, etc were all features NVIDIA introduced with Fermi more than a year ago to bring about their own compute architecture. I don’t believe there’s ever been a question whether NVIDIA was “right”, but the question has been whether it’s time to devote so much engineering effort and die space on technologies that benefit compute as opposed to putting in more graphics units. With NVIDIA and now AMD doing compute-optimized GPUs, clearly the time is quickly approaching if it’s not already here.
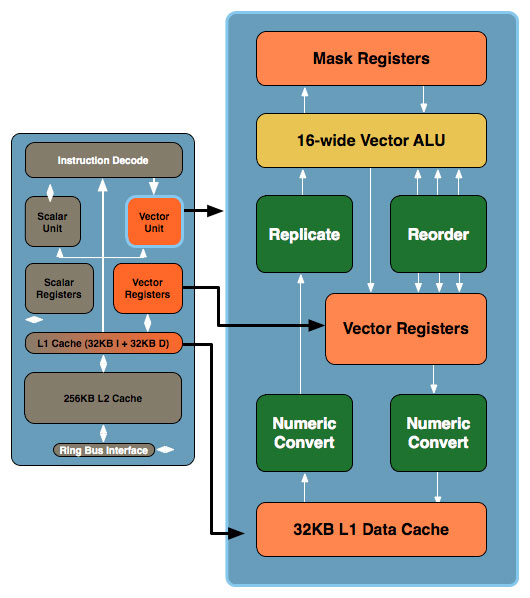
Larrabee As It Was: Scalar + 16-Wide Vector
I can’t help but to also make a comparison to Intel’s aborted Larrabee Prime architecture here. There are some very interesting similarities between Larrabee and GCN, primarily in the dual vector/scalar design and in the use of a 16-wide vector ALU. Processing 16 elements at once is an incredibly common occurrence in GPUs – it even shows up in Fermi which processes half a warp (16 threads) a clock. There are still a million differences between all of these architectures, but there’s definitely a degree of convergence occurring. Previously NVIDIA and AMD converged around VLIW in the days of the graphical GPU, and now we’re converging at a new point for the compute GPU.
Finally, while we’ve talked about the GCN architecture in great detail we haven’t talked about how to program it. Of course there’s OpenCL, but with GCN there’s going to be so much more. Next week we will be taking a look at AMD’s Fusion System Architecture, a high-level abstraction layer that will make GPU programming even more CPU-like, an advancement necessary to bring forth the kind of heterogeneous computing AMD is shooting for. We will also be taking a look at Microsoft’s C++ Accelerated Massive Parallelism (AMP), a C++ extension to bridge the gap between current and future architectures by allowing developers to program for GPUs in C++ even if the GPU doesn’t fully support the C++ feature set.
It’s clear that 2011 is shaping up to be a big year for GPUs, and we’re not even half-way through. So stay tuned, there’s much more to come.








83 Comments
View All Comments
EJ257 - Saturday, June 18, 2011 - link
I can't believe it's been 6 years since the X360 and PS3 release. It seems like this latest generation of consoles stuck around a lot longer than previous versions did. Any speculations on what kind of hardware MS and Sony will throw into the next gen?DanNeely - Sunday, June 19, 2011 - link
They have. The big console makers, at the gave devs requests, were trying to make the current generation last a decade to allow more time to recover the work expended figuring out how to best program them. The motion capture cameras were supposed to be the thing that kept the platforms from getting too stale. I suspect however, that by planning to launch its new console early Nintendo may have blown those plans out of the water.jabber - Sunday, June 19, 2011 - link
I'm pretty sure the hardware specs for both the next Xbox and Playstation have been set in stone already.I'm still betting on a 2013 release too.
So right now GPU wise I reckon we're looking at GPUs currently sitting in the $100 range for both boxes. By 2013, the cost of these chips (suitably modified) will be down to $15 -$10 a box.
I wouldnt have thought anything higher than a 5770 or 450 would be suitable/required.
Targon - Monday, June 20, 2011 - link
It all depends on what you expect. Things feel a bit stagnant on the PC game front because consoles are not evolving, and too many companies want almost exactly the same experience on the PC version as what you have on the console.Stargrazer - Saturday, June 18, 2011 - link
Something doesn't feel right here. In itself, SIMD is about *Data* Level Parallelism, not Thread Level Parallelism. Sure, you could use SIMD units as part of some larger scheme that exploits TLP, but that's not what *SIMD* is about.
Loki726 - Saturday, June 18, 2011 - link
If you use a strict definition of a SIMD programming model, then yes, you are probably right: SIMD is a single sequence of operations executed over multiple data elements.However, over time SIMD has been used to refer to both the aforementioned programming model and the hardware used to implement it. The hardware typically consists of a single control unit that broadcasts instructions to multiple functional units. When people say "a SIMD", they typically mean that hardware implementation rather than the computing model.
If that wasn't confusing enough, in the 1980s GPUs started using that SIMD hardware to execute multiple threads as long as the threads were all executing the same instruction at the same time.
So the statement about using "a SIMD" to exploit TLP is accurate, if you take "a SIMD" to mean a processor pipeline with a single control unit that broadcasts to multiple functional units, and have some scheme for scheduling threads onto functional units.
RedemptionAD - Saturday, June 18, 2011 - link
It seems like a good thing potentially. I hope that their good intentions are followed with good execution, at least better than Fermi.Targon - Sunday, June 19, 2011 - link
It should be interesting going forward. Now that AMD is finally into the 32nm process node, standalone GPUs also stand to gain quite a bit. As long as graphics don't become an afterthought to GPGPU, AMD should be in good shape. Radeon 7970(if that is the next generation GPU) may really be a game changer.Navier - Saturday, June 18, 2011 - link
Will the GCN architecture be able to be virtualized? Can a VMWare/XEN/KVM/HyperV hypervisor create vGPUs accessible by VMs in much the same way as vCPUs are today? With GPUs being integrated within the CPU package it would be a waste of resources if it could not be virtualized.This will become a critical feature for enterprise computing beyond HPC applications. One example would be gaming in a cloud computing environment, where a company provides a service that runs a game on their compute and graphics hardware for a game and streams the output to your mobile device for you to enjoy.
hechacker1 - Saturday, June 18, 2011 - link
Yeah I'm also curious about this. Perhaps with the IOMMU and other CPU like features that the GPU now has, it would be much easier to timeshare the GPU.