Westmere-EX: Intel's Flagship Benchmarked
by Johan De Gelas on May 19, 2011 1:30 PM EST- Posted in
- IT Computing
- Intel
- Xeon
- Cloud Computing
- Westmere-EX
Power Extremes: Idle and Full Load
Idle and full load power measurements are hardly relevant for virtualized environments but they offer some interesting datapoints. In the first test we report the power consumption running vApus Mark II, which means that the servers are working at 85-98% CPU load. We measured with four tiles, but we also tested the Xeon with five tiles (E7-4870 5T).
We test with redundant power supplies working, so the Dell R815 uses 1+1 1100W PSUs and the QSSC-4R uses 2+2 850W PSU. Remember that the QSSC server has cold redundant PSUs, so the redundant PSUs consume almost nothing. There's more to the story than just the PSU and performance, of course: the difference in RAS features, chassis options, PSU, and other aspects of the overall platform can definitely impact power use, and that's unfortunately something that we can't easily eliminate from the equation.
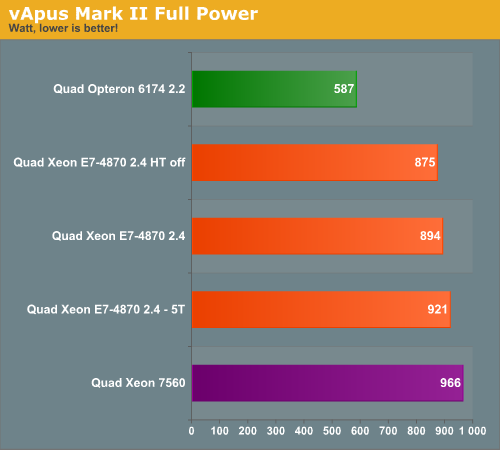
The Quad E7-4870 Xeons save about 7.5% power (894 vs 966) compared to their older brothers. The power consumption numbers look very bad compared to the AMD system in absolute terms. However, with five tiles the Quad Xeon E7 delivers 63% higher performance while consuming 57% more power. We can conclude that at very high loads, the Xeon E7 performance/watt ratio is quite competitive.
When we started testing at idle, we test with both the Samsung 1333MHz 4GB 1.35V (low power) DDR3 registered (M393B5273DH0) and 1.5V DIMMs (M393B5170FH0-H9).
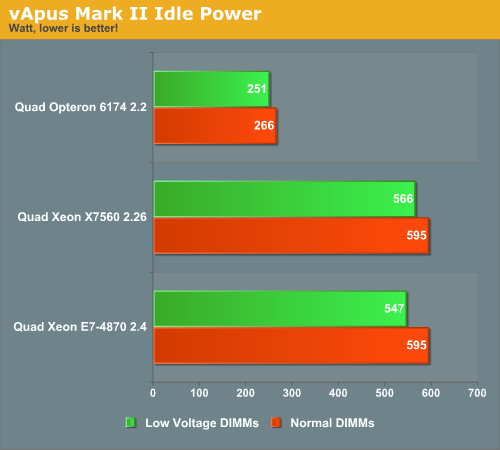
Despite the fact that the Xeon X7560 does not support low power DIMMs officially, it was able to save about 5% of the total power use. The Xeon E7's more advanced memory controller was able to reduce power by 8%. But the picture is clear: if your servers runs idle for large periods of time, the quad Opteron server is able to run on a very low amount of power, while the quad Xeon server needs at least 600W if you do not outfit it with low power 1.35V DIMMs. How much of the power difference comes from the platform in general and how much is specific to the servers being tested is unfortunately impossible to say without testing additional servers.
As we have stated before, maximum power and minimum power are not very realistic, so let us check out our real world scenario.








62 Comments
View All Comments
extide - Monday, June 6, 2011 - link
When you spend $100,000 + on the S/W running on it, the HW costs don't matter. Recently I was in a board meeting for launching a new website that the company I work for is going to be running. These guys don't know/care about these detailed specs/etc. They simply said, "Cost doesn't matter just get whatever is the fastest."alpha754293 - Thursday, May 19, 2011 - link
Can you run the Fluent and LS-DYNA benchmarks on the system please? Thanks.mosu - Thursday, May 19, 2011 - link
A good presentation with onest conclusions, I like this one.ProDigit - Thursday, May 19, 2011 - link
What if you would compare it to 2x corei7 desktops, running Linux and free server software, what keeps companies from doing that?Orwell - Thursday, May 19, 2011 - link
Most probably the lack of support for more than about 48GiB of RAM, the lack of ECC in the case of Intel and the lack of multisocket-support, just to name a few.ganjha - Thursday, May 19, 2011 - link
There is always the option of clusters...L. - Friday, May 20, 2011 - link
Err... like you're going to go cheap for the CPU and then put everything on infiniband --DanNeely - Thursday, May 19, 2011 - link
Many of the uses for this class of server involve software that won't scale across multiple boxes due to network latency, or monolithic design. The VM farm test was one example that would; but the lack of features like ECC support would preclude it from consideration by 99% of the buyers of godbox servers.erple2 - Thursday, May 19, 2011 - link
I think that more and more people are realizing that the issue is more about lack of scaling linearly than anything like ECC. Buying a bullet proof server is turning out to cost way too much money (I mean ACTUALLY bullet proof, not "so far, this server has been rock solid for me").I read an interesting article about "design for failure" (note, NOT the same thing as "design to fail") by Jeff Atwood the other day, and it really opened my eyes. Each extra 9 in 99.99% uptime starts costing exponentially more money. That kind of begs the question, should you be investing more money into a server that shouldn't fail, or should you be investigating why your software is so fragile as to not be able to accommodate a hardware failure?
I dunno. Designing and developing software that can work around hardware failures is a very difficult thing to do.
L. - Thursday, May 19, 2011 - link
Well ./ obvious.Who has a fton of servers ? Google
How do they manage availability ?
So much redundancy that resilience is implicit and "reduced service" isn't even all that reduced.
And no designing / dev s/w that works around h/w failures is not that hard at all, and it is in fact quite common (load balancing, active/passive stuff, virtualization helps too etc.).