The OCZ Vertex 3 Review (120GB)
by Anand Lal Shimpi on April 6, 2011 6:32 PM ESTAnandTech Storage Bench 2010
To keep things consistent we've also included our older Storage Bench. Note that the old storage test system doesn't have a SATA 6Gbps controller, so we only have one result for the 6Gbps drives.
The first in our benchmark suite is a light/typical usage case. The Windows 7 system is loaded with Firefox, Office 2007 and Adobe Reader among other applications. With Firefox we browse web pages like Facebook, AnandTech, Digg and other sites. Outlook is also running and we use it to check emails, create and send a message with a PDF attachment. Adobe Reader is used to view some PDFs. Excel 2007 is used to create a spreadsheet, graphs and save the document. The same goes for Word 2007. We open and step through a presentation in PowerPoint 2007 received as an email attachment before saving it to the desktop. Finally we watch a bit of a Firefly episode in Windows Media Player 11.
There’s some level of multitasking going on here but it’s not unreasonable by any means. Generally the application tasks proceed linearly, with the exception of things like web browsing which may happen in between one of the other tasks.
The recording is played back on all of our drives here today. Remember that we’re isolating disk performance, all we’re doing is playing back every single disk access that happened in that ~5 minute period of usage. The light workload is composed of 37,501 reads and 20,268 writes. Over 30% of the IOs are 4KB, 11% are 16KB, 22% are 32KB and approximately 13% are 64KB in size. Less than 30% of the operations are absolutely sequential in nature. Average queue depth is 6.09 IOs.
The performance results are reported in average I/O Operations per Second (IOPS):

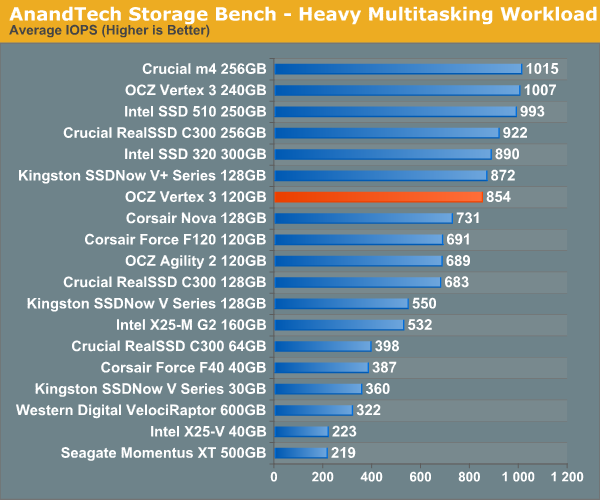
If there’s a light usage case there’s bound to be a heavy one. In this test we have Microsoft Security Essentials running in the background with real time virus scanning enabled. We also perform a quick scan in the middle of the test. Firefox, Outlook, Excel, Word and Powerpoint are all used the same as they were in the light test. We add Photoshop CS4 to the mix, opening a bunch of 12MP images, editing them, then saving them as highly compressed JPGs for web publishing. Windows 7’s picture viewer is used to view a bunch of pictures on the hard drive. We use 7-zip to create and extract .7z archives. Downloading is also prominently featured in our heavy test; we download large files from the Internet during portions of the benchmark, as well as use uTorrent to grab a couple of torrents. Some of the applications in use are installed during the benchmark, Windows updates are also installed. Towards the end of the test we launch World of Warcraft, play for a few minutes, then delete the folder. This test also takes into account all of the disk accesses that happen while the OS is booting.
The benchmark is 22 minutes long and it consists of 128,895 read operations and 72,411 write operations. Roughly 44% of all IOs were sequential. Approximately 30% of all accesses were 4KB in size, 12% were 16KB in size, 14% were 32KB and 20% were 64KB. Average queue depth was 3.59.
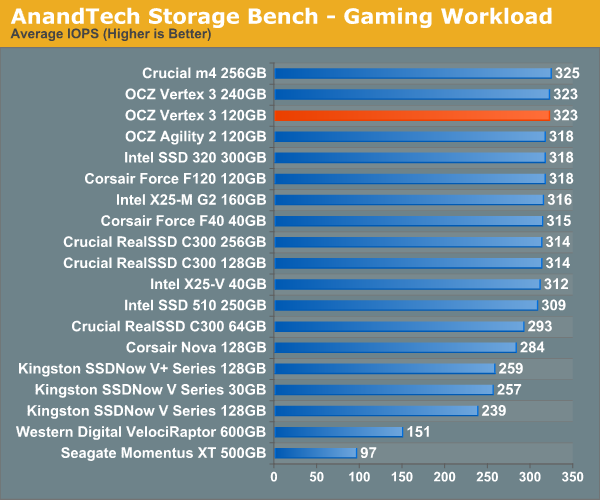
The gaming workload is made up of 75,206 read operations and only 4,592 write operations. Only 20% of the accesses are 4KB in size, nearly 40% are 64KB and 20% are 32KB. A whopping 69% of the IOs are sequential, meaning this is predominantly a sequential read benchmark. The average queue depth is 7.76 IOs.








153 Comments
View All Comments
dagamer34 - Wednesday, April 6, 2011 - link
Any idea when these are going to ship out into the wild? I've got a 120GB Vertex 2 in my 2011 MacBook Pro that I'd love to stick into my Windows 7 HTPC so it's more responsive.Ethaniel - Wednesday, April 6, 2011 - link
I just love how Anand puts OCZ on the grill here. It seems they'll just have to step it up. I was expecting some huge numbers coming from the Vertex 3. So far, meh.softdrinkviking - Wednesday, April 6, 2011 - link
"OCZ insists that there's no difference between the Spectek stuff and standard Micron 25nm NAND"Except for the fact that Spectek is 34nm I am assuming?
There surely must be some significant difference in performance between 25 and 34, right?
softdrinkviking - Wednesday, April 6, 2011 - link
sorry, i think that wasn't clear.what i mean is that it seems like you are saying the difference in process nodes is purely related to capacity, but isn't there some performance advantage to going lower as well?
softdrinkviking - Wednesday, April 6, 2011 - link
okay. forget it. i looked back through and found the part where you write about the 25nm being slower.that's weird and backwards. i wonder why it gets slower as it get smaller, when cpus are supposedly going to get faster as the process gets smaller?
are their any semiconductor engineers reading this article who know?
are the fabs making some obvious choice which trades in performance at a reduced node for cost benefits, in an attempt to increase die capacities and lower end-user costs?
lunan - Thursday, April 7, 2011 - link
i think because the chip get larger but IO interface to the controller remain the same (the inner raid). instead of addressing 4GB of NAND, now one block may consists of 8GB or 16GB NAND.in case of 8 interface,
4x8GB =32GB NAND but 8x8GB=64GB NAND, 8x16GB=128GB NAND
the smaller the shrink is, the bigger the nand, but i think they still have 8 IO interface to the controller, hence the time takes also increased with every shrinkage.
CPU or GPU is quite different because they implement different IO controller. the base architecture actually changes to accommodate process shrink.
they should change the base architecture with every NAND if they wish to archive the same speed throughput, or add a second controller....
I think....i may not be right >_<
lunan - Thursday, April 7, 2011 - link
for example the vertex 3 have 8GB NAND with 16(8 front and 8 back) connection to the controller. now imagine if the NAND is 16GB or 32 GB and the interface is only 16 with 1 controller?maybe the CPU approach can be done to this problem. if you wish to duplicate performace and storage, you do dual core (which is 1 cpu core beside the other)....
again...maybe....
softdrinkviking - Friday, April 8, 2011 - link
thanks for your reply. when i read it, i didn't realize that those figures were referring to the capacity of the die.as soon as i re-read it, i also had the same reaction about redesigning the controller, it seems the obvious thing to do,
so i can't believe that the controller manufacturer's haven't thought of it.
there must be something holding them back, probably $$.
the major SSD players all appear to be trying to pull down the costs of drives to encourage widespread adoption.
perhaps this is being done at the expense of obvious performance increases?
Ammaross - Thursday, April 7, 2011 - link
I think if you re-reread (yes, twice), you'll note that with the die shrink, the block size was upped from 4K to 8K. This is twice the space to be programmed or erased per write. This is where the speed performance disappears, regardless of the number of dies in the drive.Anand Lal Shimpi - Wednesday, April 6, 2011 - link
Sorry I meant Micron 34nm NAND. Corrected :)Take care,
Anand