A Look At Triple-GPU Performance And Multi-GPU Scaling, Part 1
by Ryan Smith on April 3, 2011 7:00 AM ESTIt’s been quite a while since we’ve looked at triple-GPU CrossFire and SLI performance – or for that matter looking at GPU scaling in-depth. While NVIDIA in particular likes to promote multi-GPU configurations as a price-practical upgrade path, such configurations are still almost always the domain of the high-end gamer. At $700 we have the recently launched GeForce GTX 590 and Radeon HD 6990, dual-GPU cards whose existence is hedged on how well games will scale across multiple GPUs. Beyond that we move into the truly exotic: triple-GPU configurations using three single-GPU cards, and quad-GPU configurations using a pair of the aforementioned dual-GPU cards. If you have the money, NVIDIA and AMD will gladly sell you upwards of $1500 in video cards to maximize your gaming performance.
These days multi-GPU scaling is a given – at least to some extent. Below the price of a single high-end card our recommendation is always going to be to get a bigger card before you get more cards, as multi-GPU scaling is rarely perfect and with equally cutting-edge games there’s often a lag between a game’s release and when a driver profile is released to enable multi-GPU scaling. Once we’re looking at the Radeon HD 6900 series or GF110-based GeForce GTX 500 series though, going faster is no longer an option, and thus we have to look at going wider.
Today we’re going to be looking at the state of GPU scaling for dual-GPU and triple-GPU configurations. While we accept that multi-GPU scaling will rarely (if ever) hit 100%, just how much performance are you getting out of that 2nd or 3rd GPU versus how much money you’ve put into it? That’s the question we’re going to try to answer today.

From the perspective of a GPU review, we find ourselves in an interesting situation in the high-end market right now. AMD and NVIDIA just finished their major pushes for this high-end generation, but the CPU market is not in sync. In January Intel launched their next-generation Sandy Bridge architecture, but unlike the past launches of Nehalem and Conroe, the high-end market has been initially passed over. For $330 we can get a Core i7 2600K and crank it up to 4GHz or more, but what we get to pair it with is lacking.
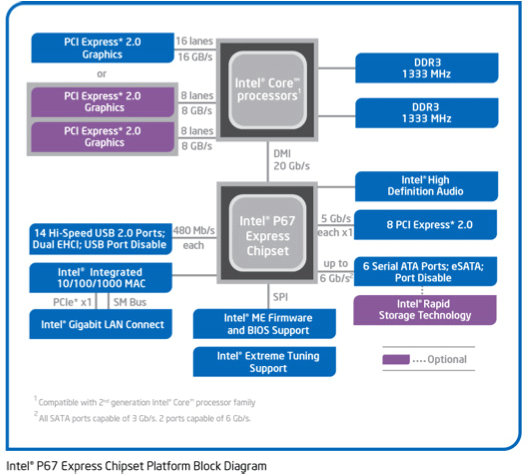
Sandy Bridge only supports a single PCIe x16 link coming from the CPU – an awesome CPU is being held back by a limited amount of off-chip connectivity; DMI and a single PCIe x16 link. For two GPUs we can split that out to x8 and x8 which shouldn’t be too bad. But what about three GPUs? With PCIe bridges we can mitigate the issue some by allowing the GPUs to talk to each other at x16 speeds and dynamically allocate CPU-to-GPU bandwidth based on need, but at the end of the day we’re splitting a single x16 lane across three GPUs.
The alternative is to take a step back and work with Nehalem and the x58 chipset. Here we have 32 PCIe lanes to work with, doubling the amount of CPU-to-GPU bandwidth, but the tradeoff is the CPU. Gulftown and Nehalm are capable chips on its own, but per-clock the Nehalem architecture is normally slower than Sandy Bridge, and neither chip can clock quite as high on average. Gulftown does offer more cores – 6 versus 4 – but very few games are held back by the number of cores. Instead the ideal configuration is to maximize performance of a few cores.
Later this year Sandy Bridge E will correct this by offering a Sandy Bridge platform with more memory channels, more PCIe lanes, and more cores; the best of both worlds. Until then it comes down to choosing from one of two platforms: a faster CPU or more PCIe bandwidth. For dual-GPU configurations this should be an easy choice, but for triple-GPU configurations it’s not quite as clear cut. For now we’re going to be looking at the latter by testing on our trusty Nehalem + x58 testbed, which largely eliminates a bandwidth bottleneck in a tradeoff for a CPU bottleneck.
Moving on, today we’ll be looking at multi-GPU performance under dual-GPU and triple-GPU configurations; quad-GPU will have to wait. Normally we only have two reference-style cards of any product on hand, so we’d like to thank Zotac and PowerColor for providing a reference-style GTX 580 and Radeon HD 6970 respectively.










97 Comments
View All Comments
DanNeely - Sunday, April 3, 2011 - link
Does DNetc not have 4xx/5xx nVidia applications yet?Pirks - Sunday, April 3, 2011 - link
They have CUDA 3.1 clients that work pretty nice with Fermi cards. Except that AMD cards pwn them violently, we're talking about an order of magnitude difference between 'em. Somehow RC5-72 code executes 10x faster on AMD than on nVidia GPUs, I could never find precise explanation why, must be related to poor match between RC5 algorithm and nVidia GPU architecture or something.I crack RC5-72 keys on my AMD 5850 and it's amost 2 BILLION keys per second. Out of 86,000+ participants my machine is ranked #43 from the top (in daily stats graph but still, man...#43! I gonna buy two 5870 sometime and my rig may just make it to top 10!!! out of 86,000!!! this is UNREAL man...)
On my nVidia 9800 GT I was cracking like 146 million keys per second, this very low rate is soo shameful compared to AMD :)))
DanNeely - Monday, April 4, 2011 - link
It's not just dnetc, ugly differences in performance also show up in the milkeyway@home and collatz conjecture projects on the boinc platform. They're much larger that the 1/8 vs 1/5(1/4 in 69xx?) differences in FP64/FP32 between would justify; IIRC both are about 5:1 in AMD's favor.Ryan Smith - Sunday, April 3, 2011 - link
I love what the Dnet guys do with their client, and in the past it's been a big help to us in our articles, especially on the AMD side.With that said, it's a highly hand optimized client that almost perfectly traces theoretical performance. It doesn't care about cache, it doesn't care about memory bandwidth; it only cares about how many arithmetic operations can be done in a second. That's not very useful to us; it doesn't tell us anything about the hardware.
We want to stick to distributed computing clients that have a single binary for both platforms, so that we're looking at the performance of a common OpenCL/DirectCompute codepath and how it performs on two different GPUs. The Dnet client just doesn't meet that qualification.
tviceman - Sunday, April 3, 2011 - link
Ryan are you going to be using the nvidia 270 drivers in future tests? I know they're beta, but it looks like you aren't using WHQL AMD drivers either (11.4 preview).Ryan Smith - Sunday, April 3, 2011 - link
Yes, we will. The benchmarking for this article was actually completed shortly after the GTX 590, so by the time NVIDIA released the 270 drivers it was already being written up.ajp_anton - Sunday, April 3, 2011 - link
When looking at the picture of those packed sardines, I had an idea.Why don't the manufacturers make the radial fan hole go all the way through the card? With three or four cards tightly packed, the middle card(s) will still have some air coming through the other cards, assuming the holes are aligned.
Even with only one or two cards, the (top) card will have access to more fresh air than before.
semo - Sunday, April 3, 2011 - link
Correct me if I'm wrong but the idea is to keep the air flowing through the shroud body and not through and through the fans. I think this is a moot point though as I can't see anyone using a 3x GPU config without water cooling or something even more exotic.casteve - Sunday, April 3, 2011 - link
"It turns out adding a 3rd card doesn’t make all that much more noise."Yeah, I guess if you enjoy 60-65dBA noise levels, the 3rd card won't bother you. Wouldn't it be cheaper to just toss a hairdryer inside your PC? You'd get the same level of noise and room heater effect. ;)
slickr - Sunday, April 3, 2011 - link
I mean mass effect 2 is a console port, Civilisation 5 is the worst game to choose to benchmark as its a turn based game and not real time and Hawx is 4 years outdated and basically game that Nvidia made, its not even funny anymore seeing how it gives the advantage to Nvidia cards every single time.Replace with:
Crysis warhead to Aliens vs predator
battleforge to shogun 2 total war
hawx to Shift 2
Civilization 5 to Starcraft 2
Mass Effect 2 with Dead Space 2
Wolfeinstein to Arma 2
+add Mafia 2