The last time we discussed CUDA and Tesla in depth was in September of 2010. At the time NVIDIA had just recently launched their lineup of Fermi-powered Tesla products, and was using the occasion to announce the 3.2 version of their CUDA GPGPU toolchain. And though when we’re discussing the fast pace of the GPU industry we’re normally referring to NVIDIA’s massive consumer GPU products arm, the Tesla and Quadro businesses are not to be underestimated. An aggressive 6 month refresh schedule is not just good for consumer products it seems, but it’s good for the professional side too.
Even against the backdrop of a 6 month refresh schedule, quite a bit has changed in the intervening period. NVIDIA’s Parallel Nsight – which we only first discussed in depth back in September – has gone free, with NVIDIA realizing that charging for the software wasn’t going to sell as many GPUs and that no one likes doing software licensing. Meanwhile the first (and thusfar only) Mac Fermi card was launched in the form of a Quadro card, helping NVIDIA go after the all-important niche of Mac desktop *nix programmers. Even the financial side of things is showing some change, with NVIDIA having just closed out Fiscal Year 2011 with nearly $100mil in Tesla sales, which at around 2.8% of NVIDIA’s revenue is the highest Tesla revenue has ever been. In fact the only thing we haven’t seen surprisingly enough is a Tesla refresh – we had GF110 pegged as an obvious upgrade for the Tesla line, which under GF100 continues to ship with only 448 SPs enabled to help meet the necessary 225W power envelope.

Meanwhile the CUDA team has been hard at work developing the next version of CUDA after CUDA 3.2, which brings us to today’s announcement. Today NVIDIA is announcing CUDA 4.0, the next full version of the toolchain. As is customary for CUDA development given its long QA cycle, NVIDIA is making their formal announcement well before the final version will be shipping. The first release candidate will be available to registered developers March 4th, and we’d expect the final version to be available a couple of months later based on NVIDIA’s previous CUDA releases.
CUDA 4.0 ends up being an interesting release as it breaks with NVIDIA’s previous release schedules somewhat. Previous CUDA releases were timed with the launch of hardware: CUDA 1.0 was released to go with G80/G9x (albeit nearly a year after they launched), CUDA 2.0 was released for GT200 in 2008, and CUDA 3.0 was released for Fermi in 2010. In the case of CUDA 4.0 there’s no new hardware to talk about at the moment, so it’s the first independent software-only major CUDA release. I’d expect that NVIDIA will still be on CUDA 4.x by the time Kepler launches, but that’s still several months out.
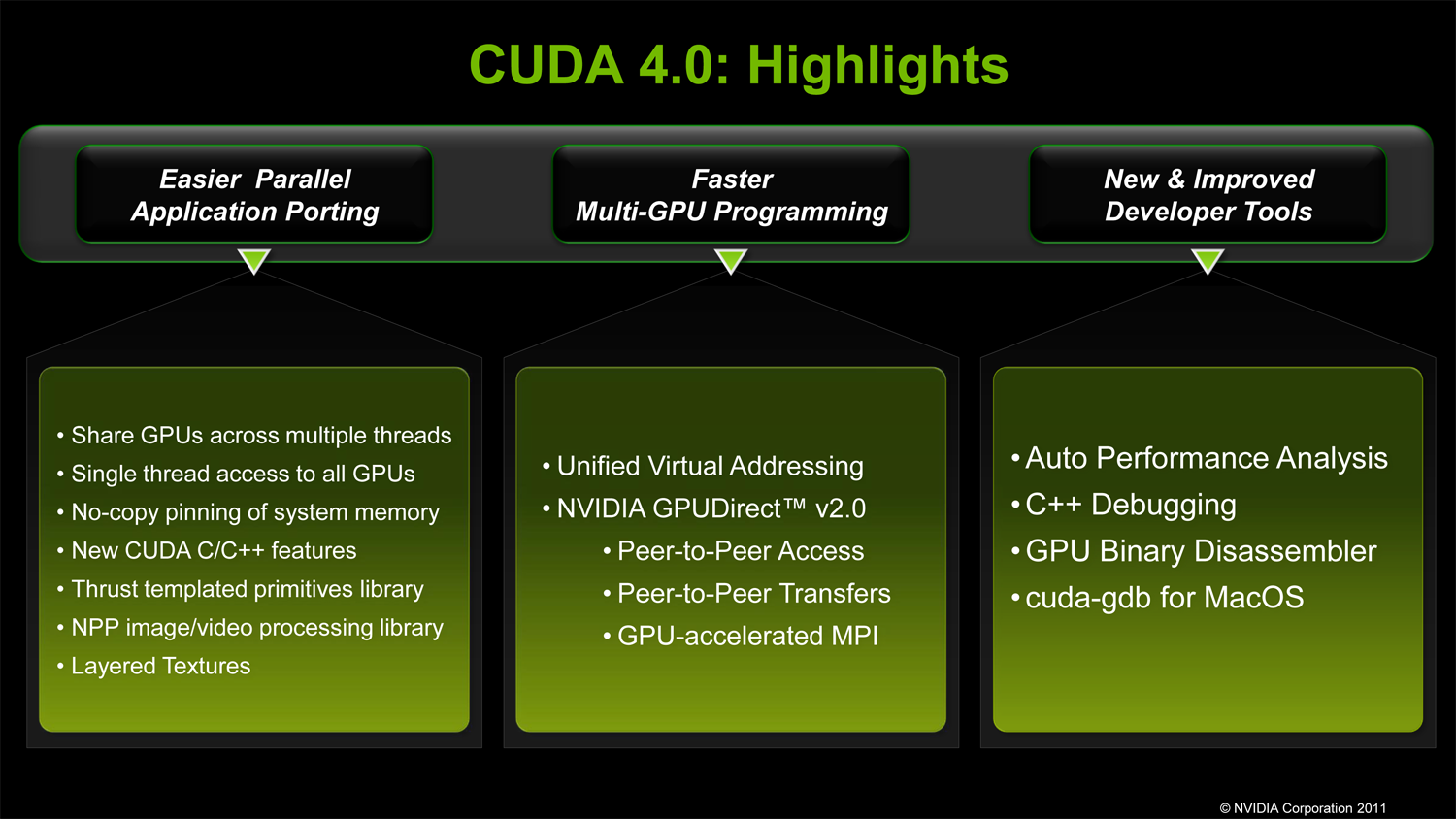
So what’s new in CUDA 4.0? As an independent software release NVIDIA’s biggest focus is on multi-GPU GPGPU performance of existing Fermi products. This is the next logical step for the company, as previous CUDA releases have continuously drilled down, starting with the basic CUDA framework which was suitable for embarrassingly parallel tasks that didn’t require intra-GPU communication, to CUDA 3.x which introduced GPUDirect thereby giving 3rd party devices direct access to CUDA memory. CUDA 4.0 in turn is the next step on that long path, and will be enabling multiple GPUs within the same system/node to more closely work together by making it easier for GPUs to access each other’s memory.
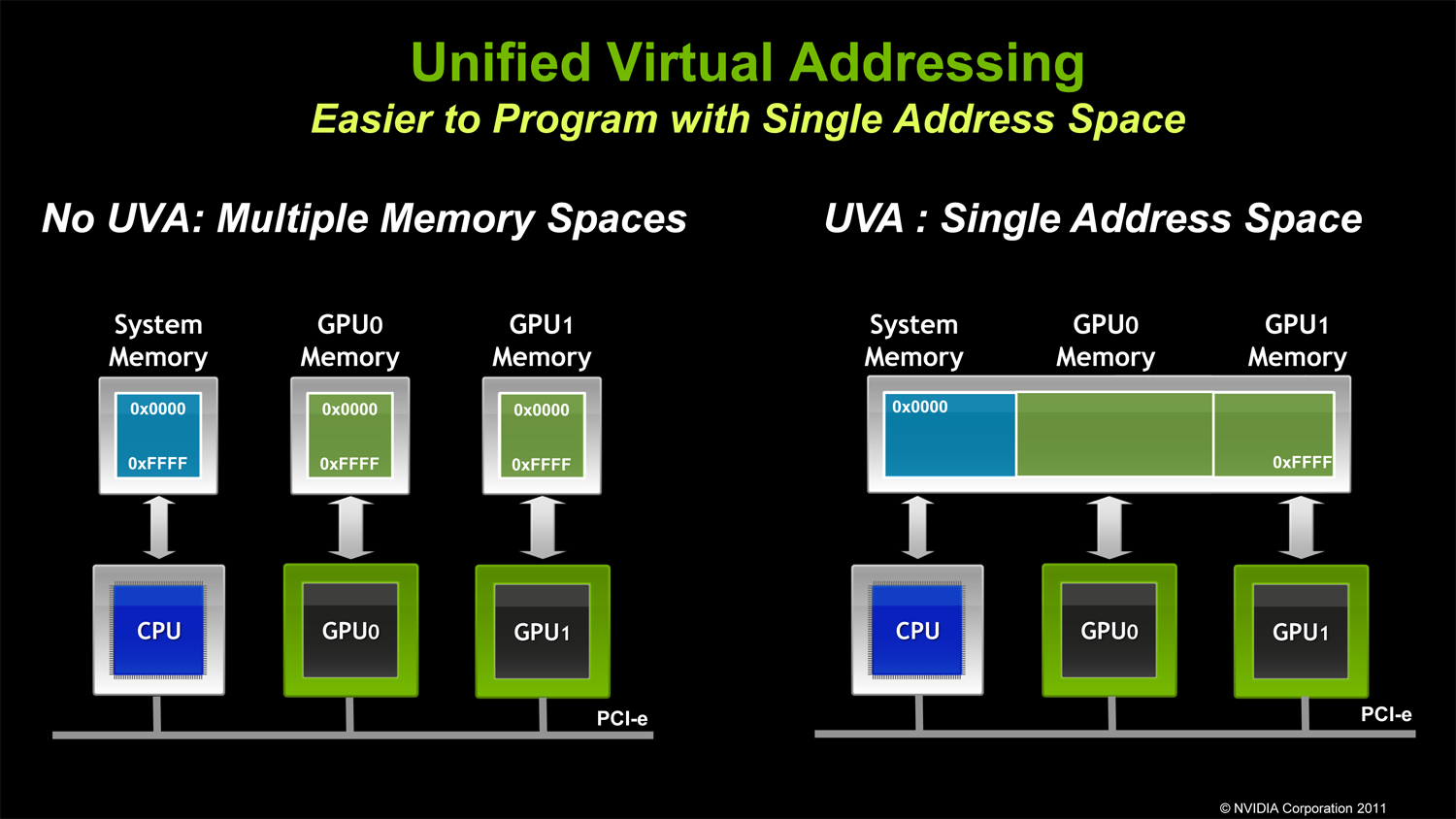
Specifically NVIDIA is doing a few things here. On the software side NVIDIA is introducing a new unified virtual address space mode (aptly named Unified Virtual Addressing), which puts all CUDA execution – CPU and GPU – in the same address space. Prior to this each GPU and the CPU used their own virtual address space, which required a number of additional steps and careful tracking on behalf of CUDA software to copy data structures between address spaces. This would seem to be riskier on the driver side in order to keep GPUs and CPUs from stomping on each other(and hence the long QA cycle), but for CUDA developers the benefit is going to be very straightforward due to the easier memory management.
Meanwhile on the hardware side NVIDIA is introducing GPUDirect 2.0. While GPUDirect 1.0 gave 3rd party devices direct memory access, it was primarily for network/infiniband communication purposes; GPUs within a node were still isolated in most cases, requiring data structures to be copied to system RAM first before any additional GPUs could access the data. GPUDirect 2.0 resolves this issue, introducing the ability for GPUs within a node to directly access each other’s memory without requiring a system memory copy first. And while system memory is by no means slow this is still much faster; for fully fed PCIe x16 slots this gives each GPU 8GB/sec of low latency full duplex bandwidth to use between the CPU and other GPUs. From our impressions we’d categorize GPUDirect 2.0 as being very NUMA-like (Non-Uniform Memory Access), however there’s still an important distinction between local and remote memory as PCIe bandwidth is still a fraction the speed of local memory – 8GB/sec versus 148GB/sec for a Tesla card, for example.
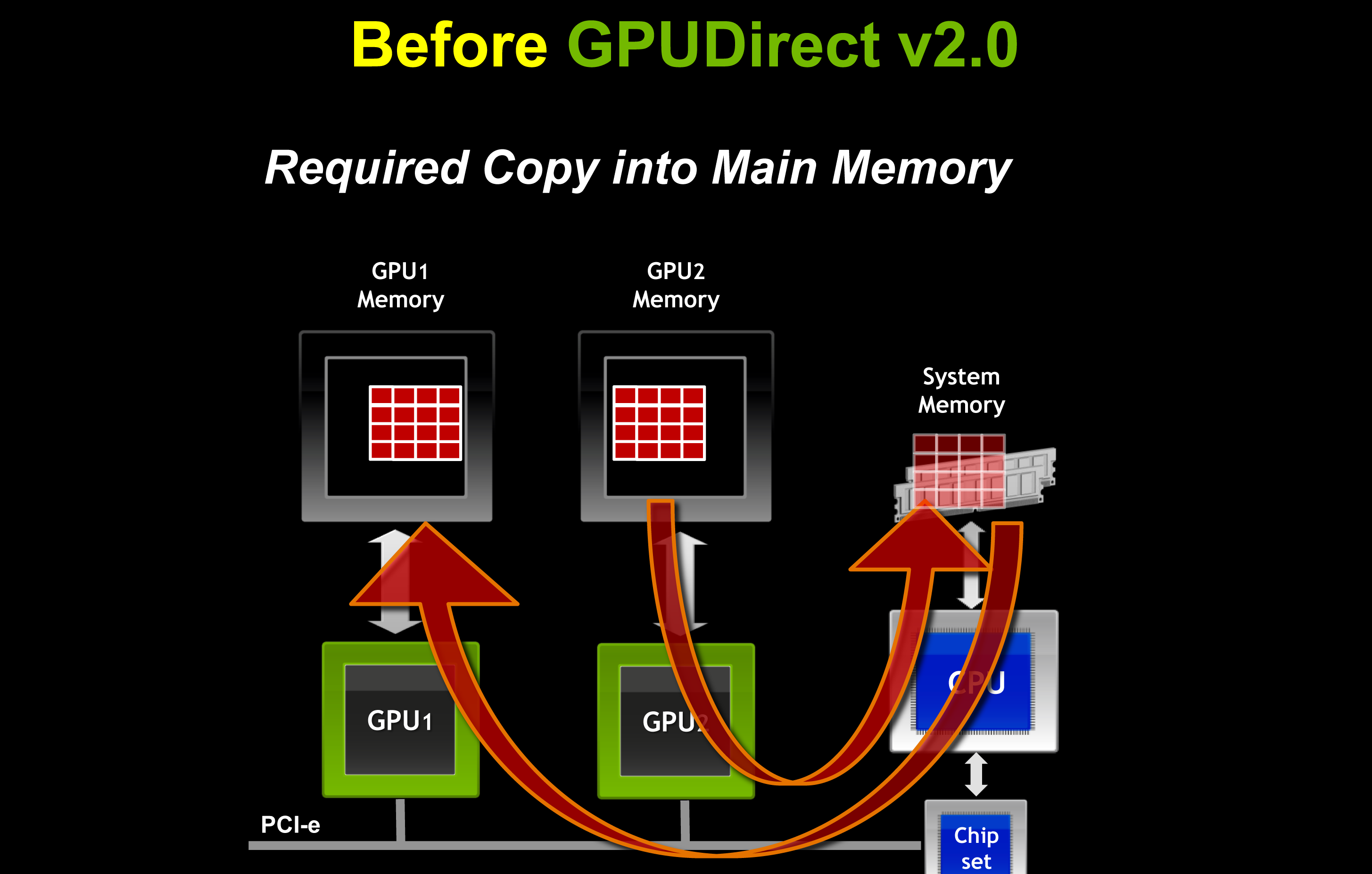
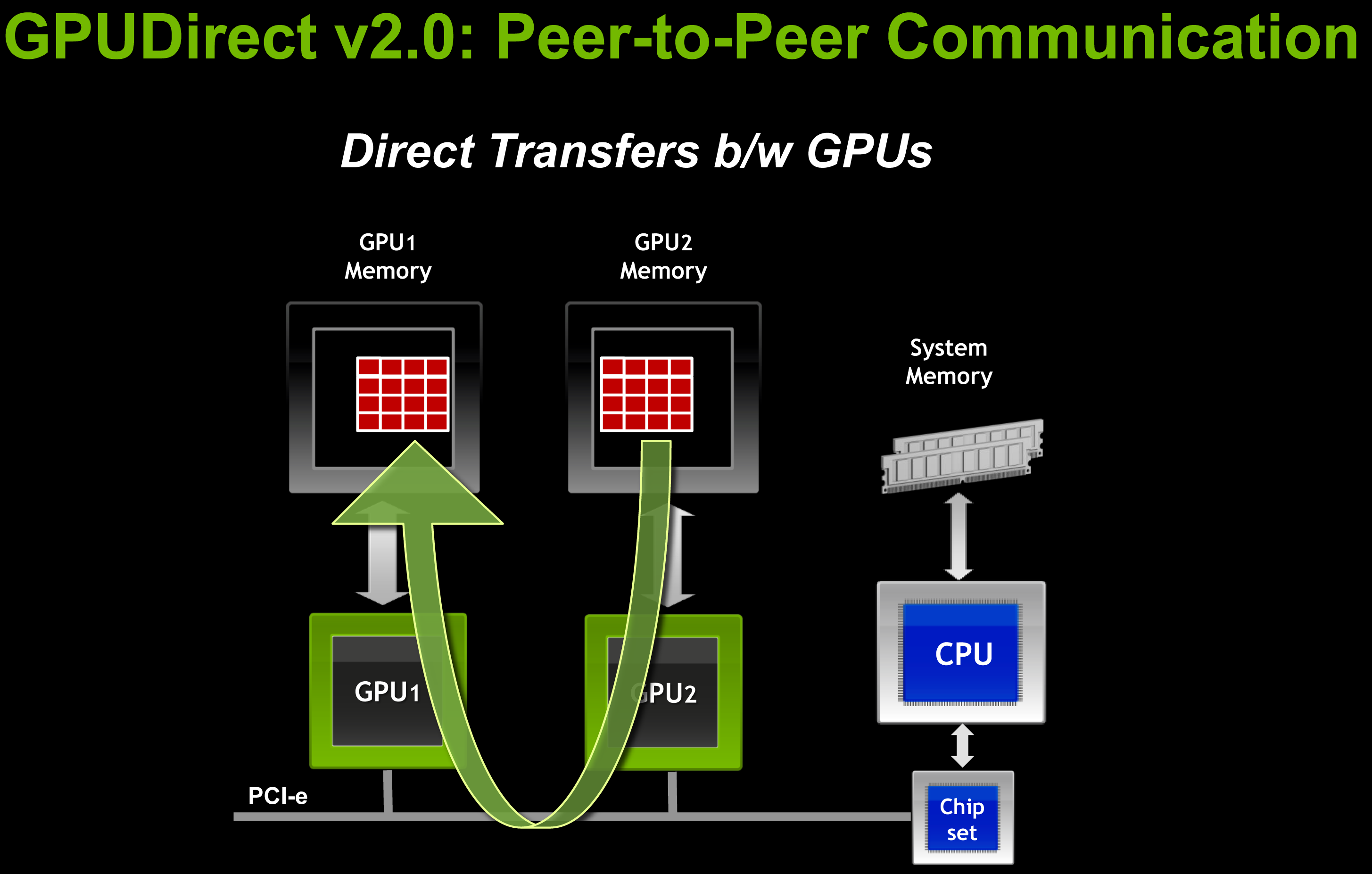
The addition of UVA on the software side and GPUDirect 2.0 on the hardware side are NVIDIA’s primary tactics to improving intra-GPU performance. PCIe’s limited bandwidth means that intra-GPU communication speeds will not be approaching intra-CPU communication speeds in the near future, so SMP-like operation is still some time off, but it should be fast enough to allow developers to work on new classes of problems that were too slow without UVA/GPUDirect.
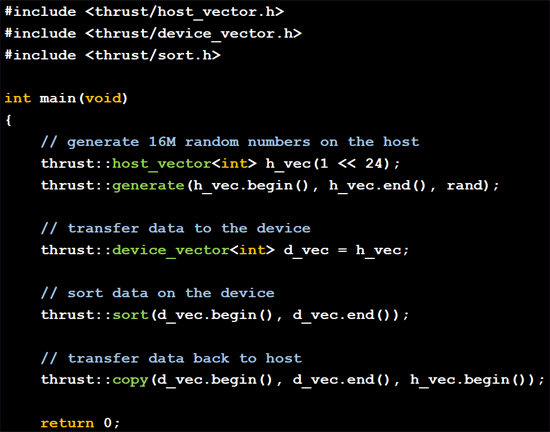
Along with multi-GPU performance, NVIDIA is of course giving considerable focus to single/overall GPU performance. CUDA 4.0 follows up on CUDA 3.2’s additional libraries with yet another set of performance-optimized libraries. Thrust – an open source CUDA template library that mimics the C++ Standard Template Library (STL) – is being integrated into CUDA proper. Thrust has been available for a couple of years now as an external library that NVIDIA developed as a research project, and is now being promoted to a member of the CUDA family. C++ programmers used to the STL stand the most to gain, as Thrust is nearly identical and can automatically handle assigning work to GPUs or CPUs as necessary.
CUDA C++ is also getting some further improvements by introducing some C++ features that were absent under CUDA 3.x. Virtual functions are now supported, along with the New and Delete functions for dynamic memory. NVIDIA noted that with CUDA 4.0 they’re shifting to working on developer requests, with both of these features being highly requested. We had also asked NVIDIA about what C++ adoption by developers had been like – C++ being an important part of the Fermi hardware – but unfortunately NVIDIA doesn’t have the means to precisely track which languages developers are actually using. However it sounds like adding C++ was an appropriate choice for the company.
Finally, the last set of improvements NVIDIA is focusing on is on the developer tools themselves. Coming back again to the Mac/*nix market, NVIDIA had added CUDA debugging support to Mac OS X; *nix CUDA developers doing their development on Macs will now be able to debug their code right on their machines. Meanwhile NVIDIA’s Visual Profiler performance profiling tool is getting an upgrade of its own: previously it could identify bottlenecks in code, now it can offer hints on how to improve performance at those bottlenecks. Finally, the CUDA toolkit will now include a binary disassembler, for use in analyzing the resulting output of the CUDA compiler.
Wrapping things up, as we mentioned before the first release candidate of CUDA 4.0 will be available to registered developers on March 4th. NVIDIA doesn’t have a commitment date for the release version, but expect it to be available a couple of months later based on NVIDIA’s previous CUDA releases.








44 Comments
View All Comments
DanNeely - Monday, February 28, 2011 - link
Dunno. NVidia's compatibility page hasn't been updated past v2.0.http://www.nvidia.com/object/cuda_gpus.html
mmrezaie - Monday, February 28, 2011 - link
I wished years for features just presented in cuda 4. It again went another step besting OpenCL simplicity of programming. The new memory model is just a great step, but I am not sure how they are doing it in driver. maybe by reading SDK manual and samples I will get it.StormyParis - Monday, February 28, 2011 - link
It's nice and all, and nVidia's PR people can certainly get sites to talk about it (ad budgets and linked review samples must help, too). BuT I've never seen CUDA actually used anywhere.Except for the 0.5-1% of us who use photo and video editing tools intensively, why should we care about it ?
Ryan Smith - Monday, February 28, 2011 - link
I'll be the first person to tell you that the consumer market so far has been close to a flop. Outside of Adobe and Cyberlink/Corel/Arcsoft (and anyone else using video encode APIs) almost nothing on the consumer side of things is GPGPU accelerated in a meaningful manner. So you're correct in that you've never seen CUDA used anywhere.But, and this is the key point, it's quite a different story in industry. Engineering firms, research labs, etc are all using GPGPU products from both sides of the isle. These are products developed in-house, or cost thousands of dollars a seats and are used by a small handful of people. So CUDA is being used in a number of places (quite how much, I can't say), but you and I just aren't in environments where we regularly see it.
haplo602 - Monday, February 28, 2011 - link
that's because consumer market is a production one. you have to create data out of data which is slow (video/photo processing) once the working set does not fit into the card onboard memory.scientific uses are different. you run compute intensive analysis/simulation on a small working set (or one that can be split to fit the memory constaints).
even the new NUMA like architecture still does not address the memory I/O problems, it just enables to split the workload a bit better.
I guess once the integrated arm cores start to be used, we'll get something like multi-cell computers with PCIe buses as a backplane. However Infiniband would be much better here. basicaly a new type of industrial/super computer will be born. again nothing consumer friendly.
formulav8 - Monday, February 28, 2011 - link
Well a average consumer wouldn't care about it. If you are a Cuda developer then you definitely would.InternetGeek - Monday, February 28, 2011 - link
In a way you are right, anything performing video encoding using VC-1 will use CUDA to accelerate encoding, otherwise it will take days to finish a half-assed encode. If you like to encode your movies while keeping the cool sound this is the way to go, because even cellphones can play the movie. Otherwise you have to use AAC-LC which is Apple's funky way of calling stereo sound.Genx87 - Monday, February 28, 2011 - link
If you havent seen it then clearly nobody has.habibo - Monday, February 28, 2011 - link
You're right that CUDA has not made much of a difference in consumer applications. This is fundamentally a problem of economics for software developers. It's a tough sell to cut out 50% of your potential customers by locking yourself into NVIDIA hardware!But it's made a huge difference in lots of industrial applications. NVIDIA claims to have sold around $100 million worth of Tesla computing GPUs last fiscal year. And if you look at last November's "Top 500" supercomputing list, 3 of the top 5 supercomputers in the world are built with NVIDIA GPUs.
So CUDA is definitely important, though as you mention, not in a lot of places your typical user will notice. :-)
MrSpadge - Monday, February 28, 2011 - link
Matlab supports CUDA.MrS