Micron's ClearNAND: 25nm + ECC, Combats Increasing Error Rates
by Anand Lal Shimpi on December 2, 2010 12:01 AM ESTEleven months ago Intel and Micron, jointly as IMFT, announced intentions to move to 25nm NAND by the end of 2010. For the past few months, IMFT has been shipping 25nm NAND although none of it has ended up in the high performance SSDs we love to cover just yet.
The problem, as with a jump to any new manufacturing node, has to do with yields. In the microprocessor space, new processes generally mean you can’t reach your clock targets and you may use more power than you’d like. The more experience you have in working with the process the more you can get these two variables under control and eventually you have a technology you can ship to the market.

The same is true with NAND, although the vectors of improvement are a bit different. Rather than clock speed and power (although both are affected) the main focus these past few months has been increasing endurance and reducing uncorrectable bit error rate.
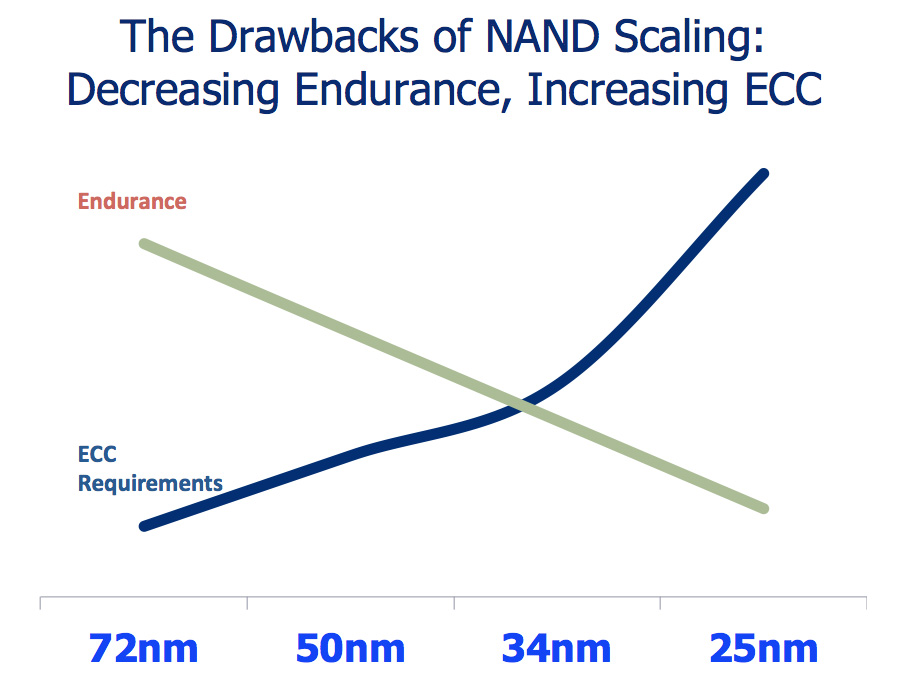
When I first started reviewing SSDs IMFT was shipping 50nm MLC NAND rated at 10,000 program/erase cycles per cell. As I mentioned in a recent SSD article, the move to 3xnm cut that endurance rating in half. Current NAND shipping in SSDs can only last half as long, or approximately 5,000 program/erase cycles per cell. Things aren’t looking any better for 25nm. Although the first 25nm MLC test parts could only manage 1,000 P/E cycles, today 25nm MLC NAND is good for around 3,000 program/erase cycles per cell.
The reduction in P/E cycles is directly related to the physics of shrinking these NAND cells; the smaller they get, the faster they deteriorate with each write. Remember this diagram?
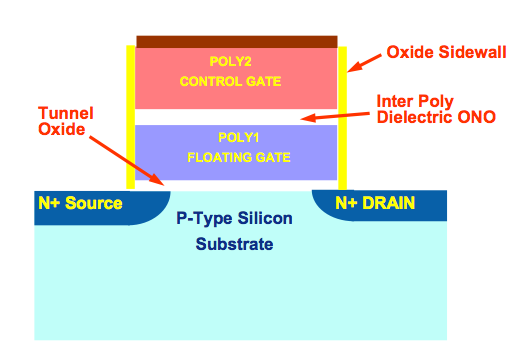
That’s an N-channel MOSFET, the building block of a NAND memory cell. Electrons travel through the tunnel oxide and make their way to the floating gate when a NAND cell is written to. The electrons are removed when a cell is erased. Each round trip is a single program/erase cycle. The process actually weakens the tunnel oxide. The smaller the tunnel oxide, the weaker it becomes, hence the decreasing p/e cycles I mentioned above.
Thankfully this doesn’t have to mean that a 3xnm SSD will die quicker than a 50nm SSD. Moore’s Law guarantees that our SSD controllers can grow in complexity and performance alongside each NAND generation. In theory, a better controller could drive write amplification lower and thus use those program/erase cycles more efficiently. This is exactly what we have seen thus far. SandForce’s SF-1200 is the perfect example of a controller-based solution to the problem of decreasing endurance with smaller geometry NAND. Even new controllers from Indilinx, Toshiba and Samsung have managed to reduce write amplification and increase performance to combat decreasing endurance.
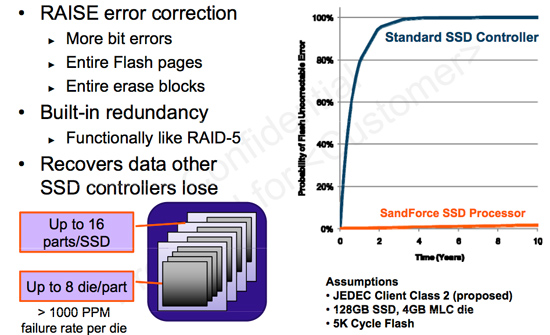
How SandForce deals with the problem of reduced endurance and increased error rates
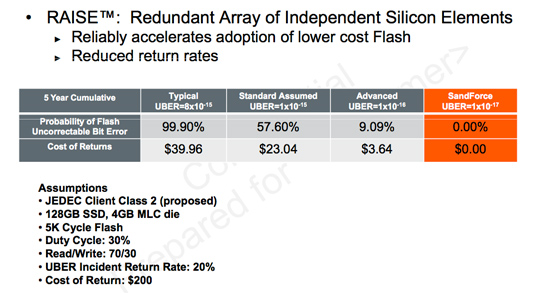
Error rates also skyrocket as a function of process geometry. The supply-demand-like curve above shows just that. SandForce integrates ECC/CRC into its controller as well as enables data redundancy across all NAND in its drives in order to combat increasing error rates with smaller geometry flash. The end result is a very forward looking, sophisticated and expensive SSD controller. What Micron plans to offer however is an alternative. It’s called ClearNAND:

The idea is simple. Instead of placing the burden of dealing with increasing error rates on the controller, Micron will internalize the problem and equip each NAND device with an ECC controller.
The NAND will still appear to be an ONFI complaint device with the same number of pins as a regular 25nm ONFI NAND device (a single unused pin, VDDI, is now put to use in ClearNAND). The bus interface remains the same and NAND controller manufacturers don’t have to do anything differently.
On each ClearNAND device you get a 24-bit BCH ECC engine, although Micron says that in another generation or two we’ll start seeing more exotic ECC algorithms.
![]()
ClearNAND will be available starting at the 25nm node in two versions: standard and enhanced. Standard ClearNAND devices are low performance, you only get up to 50MB/s per device and up to 4 simultaneous read/write ops to the device at the same time. Enhanced ClearNAND doubles maximum capacity from 32GB to 64GB per device, quadruples interface bandwidth (200MB/s) and supports up to 16 simultaneous read/write ops. Enhanced ClearNAND would be the NAND of choice for an SSD, while Standard ClearNAND would be better suited for an iPod or smartphone for example.
Raw 25nm NAND will still be available, Micron is simply offering ClearNAND as a solution to those customers who don’t want to integrate ECC engines into their controllers.
Today the need for something like ClearNAND isn’t huge, however in the next few years Micron expects ECC equipped NAND to be the most prevalent form of NAND in the market. This would make sense as error rate goes up as process size decreases, however it does assume that the ECC requirements can’t or aren’t handled at the controller level in the future.
There’s obviously a price premium associated with ClearNAND. However since we aren’t a customer of Micron, we aren’t exactly privy to specific pricing information.
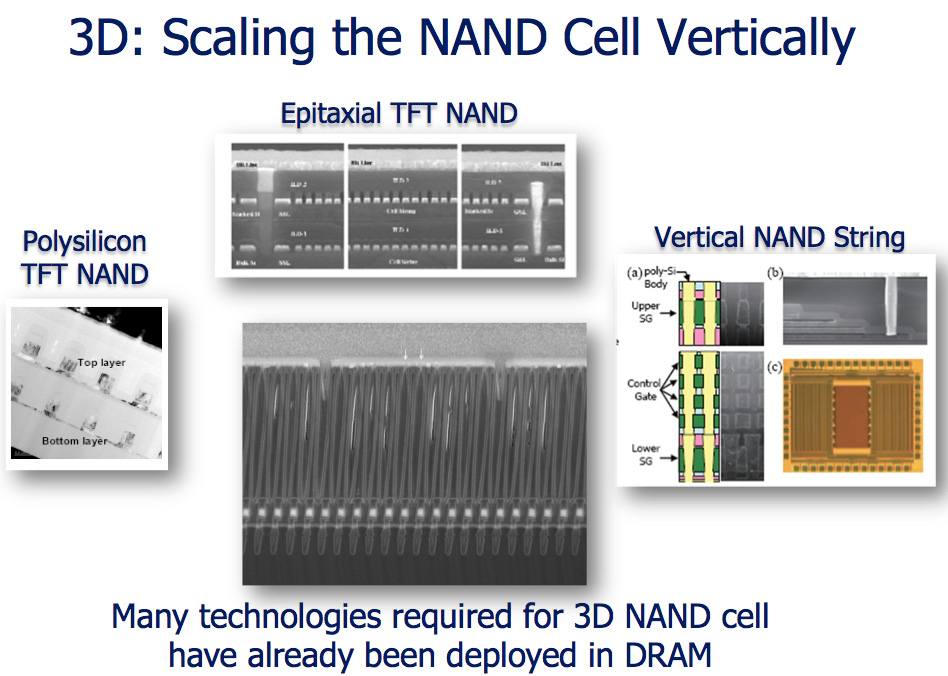
Eventually we will hit a physical wall with NAND scaling. Micron reaffirmed its commitment to research into technologies that would extend the lifespan of NAND (e.g. 3D die) or potentially augment its role in a system (e.g. phase-change memory). That’s still a few generations out though.

I don’t expect to see the first consumer SSDs to use 25nm NAND (ClearNAND or raw) until 2011. Intel’s 3rd generation X25-M will be one of the first (if not the first) and is currently scheduled to ship in Q1 2011.








24 Comments
View All Comments
michaelaj - Thursday, December 2, 2010 - link
Out of curiosity, the ECC is a 24-bit BCH code, so what's the rate of the code? It's a rate k/24 code presumably, so what is k? Are there any more details on this?What with the rated P/E cycles dropping so quickly with the size of the transistors, it may be interesting to see how complicated the ECC will need to become. But first we need a reference point on what they are doing now.
campbbri - Thursday, December 2, 2010 - link
Anand,Thanks for a great article as usual. I have a few questions that I hope you (or anyone else) enlighten me on.
1. Is a 3,000 P/E cycle rating an average per cell? Is there typically high variation, with some cells lasting 4,000 cycles and some lasting 2,000, for example, or do they all fail after roughly the same number of cycles?
2. When cells run out of cycles, what happens? Does the controller always recognize the bad cells and start reducing drive capacity or spare area, or is there a chance of losing data when it thinks it's written to an unwriteable cell?
3. On a "typical" 34 nm SSD (like Intel X-25M) what's the likelihood of a soft error changing a single bit in my data? Is it something like 1 error per X GB or is it practically zero until NAND degrades after enough use? If I understand correctly, the RAISE error correction graph implies it's a function of time, and the table below the graph shows the probability of uncorrectable errors hitting the end user is significant.
Finally, a suggestion. Data integrity is important to a lot of SSD users (even consumers), and I know you test reliability as much as possible and have shown older SSDs getting bricked or becoming unuseable. Many of us do nightly backups and aren't that scared of total failure. I'm more worried about data being slowly corrupted as a bit changes here or there. Would it be difficult to add to your testing suite the equivalent of memtest for SSDs? It could write and rewrite patterns to the drive constantly for a week or so and see if anything out of the ordinary comes up.
With all the competition I think SSD makers have a incentives to sacrifice "soft error" reliability in favor of price and capacity, and that worries me.
mpx - Friday, December 3, 2010 - link
Variation is suppsed to be very high, with some producers selling "Select" SLC flash models, where 93% of cells can withstand 2 million cycles. It goes into enterprise drives like STEC, while the non-select, but still within spec one one goes to fast Compact Flash or SD cards.Endurance is not the only parameter affected by going analog in MLC. Also suceptibility to electric noise, that may cause misread of a charge level. This is also getting worse with higher densities. Three-bit cells are even worse here.
In enterprise systems when the cells of an SSD or a flash module are near the wear limit the system log of your array informs about this, or even e-mails message about this. Even if it's ignored then there's always redundancy of RAID - SSD will be simply swapped to another, new SSD, that begins wear-process from the start.
More theory on this site:
http://www.storagesearch.com/ssd-slc-mlc-notes.htm...
Mr Perfect - Thursday, December 2, 2010 - link
With the last generation of flash, manufacturers stopped talking about SLC and started pushing Enterprise MLC. Is there some reason SLC is loosing out? I would think that at smaller nodes, SLC would not only become affordable, but might actually start to make sense with it's significantly higher endurance.NandFlashGuy - Thursday, December 2, 2010 - link
Yes, SLC is losing out because of the cost. SLC drives are still available, but they are generally only for extreme usage cases where the usage justifies the cost.Link to Hitachi and Intel's jointly designed enterprise SSD:
http://www.hitachigst.com/solid-state-drives/ultra...
A hard drive in your laptop is written to far less than the capability of MLC flash -- so there's no reason to double the cost for endurance that will never required.
Enterprise MLC is a nice solution for those who demand beyond normal MLC capabilities but not full-fledged SLC pricing.
Longer term, I think you'll continue to see diversification in the market. Perhaps Three-level cell SSDs for consumers who are extremely price sensitive vs higher endurance solutions for those willing to pay more.
melgross - Thursday, December 2, 2010 - link
It seems to me that no matter how sophisticated controllers and memory becomes, the decreasing writability of the cells will overcome all of this. We're dependent on those numbers, and at some point the write cycle max will be reached. I don't quite understand how a controller can get around it. All they can do is to use the cells more efficiently. At some point, there will be no more gains possible, and going to smaller cells will result in decreased lifetime, requiring so much spare capacity on the drive that the point of using smaller process tech will have been negated. Sandforce already uses up to 28% spares on it's better drives. Where will that go at 25nm? What about the less expensive models such as the OWC with 7% I just bought?If they can't get 25nm much better than 3,000 writes, then the next smaller node may be no better than about 1,500. Can they really deal with that? I don't see how.
ABR - Friday, December 3, 2010 - link
Let's assume 100MB/sec is an attainable sustained rate, and generate/write randomized data repeatedly over the whole disk as a single 64GB file and then delete it, and do it again. 64000 / 100 = about 11 minutes for one cycle. It would take a little over 3 weeks to hit a 3,000 limit.Sounds bad. But, my laptop disk has written about 64GB in *2 weeks*: 1800 times slower usage. If it was an SSD it would last a hundred years at that rate.
mpx - Saturday, December 4, 2010 - link
There are some software problems involved. Windows frequently moves a lot of files through main disk drive even if it doesn't need it.. For example when using decompression using copy-and-paste in some decompression programs the files are first decompressed to %TEMP%, and only then moved to final location. This doesn't happen if you use "Extract" from program menu, it's the issue with Windows Explorer.flamethrower - Thursday, December 2, 2010 - link
Hey Anand,Are you able to test endurance? You are not, correct? Because the wear leveling algorithm is too good. You cannot R/W the same 1MB of data 10,000 times because the wear leveling algorithm will spread that wear across the entire drive. You could try randomizing the data as it is written (because the SandForce controller will cheat and say data has been written when it has not actually been if the data is the same or even similar). Even if you create a small partition and write to it over and over, that still will not work. Correct?
Is there a way you can write to the drive in raw mode, testing endurance that way?
Iketh - Thursday, December 2, 2010 - link
ie bypassing the controller?? lol doubt it