ZFS - Building, Testing, and Benchmarking
by Matt Breitbach on October 5, 2010 4:33 PM EST- Posted in
- IT Computing
- Linux
- NAS
- Nexenta
- ZFS
ZFS Features
ZFS includes two exciting features that dramatically improve the performance of read operations. I’m talking about ARC and L2ARC. ARC stands for adaptive replacement cache. ARC is a very fast block level cache located in the server’s memory (RAM). The amount of ARC available in a server is usually all of the memory except for 1GB.
For example, our ZFS server with 12GB of RAM has 11GB dedicated to ARC, which means our ZFS server will be able to cache 11GB of the most accessed data. Any read requests for data in the cache can be served directly from the ARC memory cache instead of hitting the much slower hard drives. This creates a noticeable performance boost for data that is accessed frequently.
As a general rule, you want to install as much RAM into the server as you can to make the ARC as big as possible. At some point adding more memory becomes cost prohibitive, which is where the L2ARC becomes important. The L2ARC is the second level adaptive replacement cache. The L2ARC is often called “cache drives” in the ZFS systems.
These cache drives are physically MLC style SSD drives. These SSD drives are slower than system memory, but still much faster than hard drives. More importantly, the SSD drives are much cheaper than system memory. Most people compare the price of SSD drives with the price of hard drives, and this makes SSD drives seem expensive. Compared to system memory, MLC SSD drives are actually very inexpensive.
When cache drives are present in the ZFS pool, the cache drives will cache frequently accessed data that did not fit in ARC. When read requests come into the system, ZFS will attempt to serve those requests from the ARC. If the data is not in the ARC, ZFS will attempt to serve the requests from the L2ARC. Hard drives are only accessed when data does not exist in either the ARC or L2ARC. This means the hard drives receive far fewer requests, which is awesome given the fact that the hard drives are easily the slowest devices in the overall storage solution.
In our ZFS project, we added a pair of 160GB Intel X25-M MLC SSD drives for a total of 320GB of L2ARC. Between our ARC of 11GB and our L2ARC of 320GB, our ZFS solution can cache over 300GB of the most frequently accessed data! This hybrid solution offers considerably better performance for read requests because it reduces the number of accesses to the large, slow hard drives.
Things to Keep in Mind
There are a few things to remember. The cache drives don’t get mirrored. When you add cache drives, you cannot set them up as mirrored, but there is no need to since the content is already mirrored on the hard drives. The cache drives are just a cheap alternative to RAM for caching frequently access content.
Another thing to remember is you still need to use SLC SSD drives for the ZIL drives. ZIL stands for "ZFS Intent Log", and acts as an intermediary for write caching. Not having ZIL drives severely slows down write access. By adding the ZIL drives you significantly increase write speeds. This is still not as fast as a RAM based write cache on a RAID card, but it is much better than not having anything. Solaris ZFS Best Practices For Log Devices The SLC SSD drives used for ZIL drives dramatically improve the performance of write actions. The MLC SSD drives used as cache drives are used to improve read performance.
It is also important to remember that the L2ARC will require some memory to operate. A portion of the ARC will be used to index and manage the content located in the L2ARC. A general rule of thumb is that 1-2GB of ARC will be used for every 100GB of L2ARC. With a 300GB L2ARC, we will give up 3-6GB of ARC. This will leave us with 5-8GB of ARC memory to use to cache the most frequently accessed files.
Effective Caching to Virtualized Environments
At this point, you are probably wondering how effectively the two levels of caching will be able to cache the most frequently used data, especially when we are talking about 9TB of formatted RAID10 capacity. Will 11GB of ARC and 320GB L2ARC make a significant difference for overall performance? It will depend on what type of data is located on the storage array and how it is being accessed. If it contained 9TB of files that were all accessed in a completely random way, the caching would likely not be effective. However, we are planning to use the storage for virtual machine file systems and this will cache very effectively for our intended purpose.
When you plan to deploy hundreds of virtual machines, the first step is to build a base template that all of the virtual machines will start from. If you were planning to host a lot of Linux virtual machines, you would build the base template by installing Linux. When you get to the step where you would normally configure the server, you would shut off the virtual machine. At that point, you would have the base template ready. Each additional virtual machine would simply be chained off the base template. The virtualization technology will keep the changes specific to each virtual machine in its own child or differencing file.
When the virtualization solution is configured this way, the base template will be cached quite effectively in the ARC (main system memory). This means the main operating system files and cPanel files should deliver near RAM-disk performance levels. The L2ARC will be able to effectively cache the most frequently used content that is not shared by all of the virtual machines, such as the content of the files and folders in the most popular websites or MySQL databases. The least frequently accessed content will be pulled from the hard drives, but even that should show solid performance since it will be RAID10 across 18 drives and none of the frequently accessed read requests will need to burden the RAID10 volume since they are already served from ARC or L2ARC.
Testing the L2ARC
We thought it would be fun to actually test the L2ARC and build a chart of the performance as a function of time. To test and graph usefulness of L2ARC, we set up an iSCSI share on the ZFS server and then ran Iometer from our test blade in our blade center. We ran these tests over gigabit Ethernet.
Iometer Test Details:
25GB working set
4k blocks
100% random
100% read
load 32 (constant)
four hour test
Every ten minutes during the test, we grabbed the “Last performance” values (IOPS, MB/sec) from Iometer and wrote them down to build a performance chart. Our goal was to be able to graph the performance as a function of time so we could illustrate the usefulness of the L2ARC.
We ran the same test using the Promise M610i (16 1TB WD RE3 drives in RAID10) box to get a comparison graph. The Promise box is not a ZFS style solution and does not have any L2ARC style caching feature. We expected the ZFS box to outperform the Promise box, and we expected the ZFS box to increase performance as a function of time because the L2ARC would become more populated the longer the test ran.
The Promise box consistently delivered 2200 to 2300 IOPS every time we checked performance during the entire 4 hour test. The ZFS box started by delivering 2532 IOPS at 10 minutes into the test and delivered 20873 IOPS by the end of the test.
Here is the chart of the ZFS box performance results:
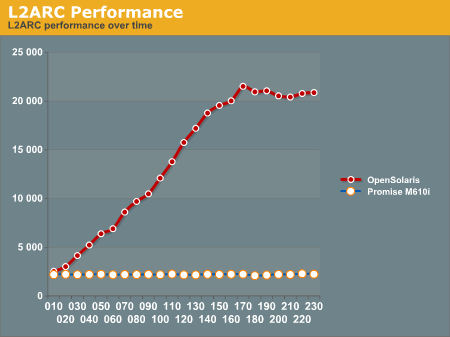
Initially, the two SAN boxes deliver similar performance, with the Promise box at 2200 IOPS and the ZFS box at 2500 IOPS. The ZFS box with a L2ARC is able to magnify its performance by a factor of ten once the L2ARC is completely populated!
Notice that ZFS limits how quickly the L2ARC is populated to reduce wear on the cache drives. It takes a few hours to populate the L2ARC and achieve maximum performance. That seems like a long time when running benchmarks, but it is actually a very short period of time in the life cycle of a typical SAN box.








102 Comments
View All Comments
cdillon - Tuesday, October 5, 2010 - link
I've been working on getting the additional parts necessary to build a similar system out of a slightly used HP DL380 G5 with a bunch of 15K SAS drives and an MSA20 shelf full of 750GB SATA drives. Here's what I'm going to be doing a little differently from what you've done:1) More CPU (already there, it has dual Xeon X5355 if I recall correctly)
2) Two mirrored OCZ Vertex2 EX 50GB drives for the SLOG device (the ZIL write cache). Even though the Vertex2 claims a highly impressive 50,000 random-write IOPS, the ZIL is written sequentially, and the Vertex2 EX claims to sustain 250MB/sec writes, so it should make a very good SLOG device.
3) Two OCZ Vertex2 100G (the cheaper MLC models) for L2ARC.
4) The SSDs will be put on a separate SAS HBA card from the HDDs to prevent I/O starvation due to the HBA I/O queue filling up because of the relatively slow I/O service-times of the HDDs.
5) Quad Gigabit Ethernet or 10G Ethernet link. The latter will require an upgrade to our datacenter switches, which is probably going to happen soon anyway.
mbreitba - Tuesday, October 5, 2010 - link
I would love to see performance results for your setup. The IOMeter ICF file that we have linked to in the article would help you run the exact same tests as we ran if you would be interested in running them.cdillon - Tuesday, October 5, 2010 - link
I forgot to mention it might also be running FreeBSD (which I'm very familiar with) rather than Nexenta or OpenSolaris, but I'm just kind of playing it by ear. I may try all three. The goal is for it to eventually become a production storage server, but I'm going to do a bit of experimentation first. I still haven't gotten around to ordering the SSDs and the extra SAS HBAs, so it'll be a while before I have any benchmarks for you.Maveric007 - Tuesday, October 5, 2010 - link
You should throw Linux into the mix. You find your performance will increase over the other selections ;)MGSsancho - Tuesday, October 5, 2010 - link
ZFS on linux is terrible. also ZFS on FreeBSD is decent. recent ZFS features such as deduplication and iSCSI are not available on FreeBSD. just grab a copy of the latest build of opensolaris (134), compile it from build 157. use solaris 10 (got to pay now), or use one of the mentioned Nexenta distros.From personal experience, use fast SSD drives. I made the mistake of using a pair of the Intel 40GB Value drives for a home box with 8 x 1.5 TB drives. terrible performance. Yes it is cool for latency but I cant get more than 40MBs from it. I have tried using them just for ZIL or just for L2ARC and performance is abyssal. Get the fastest possible drives you can afford.
Matt, have you tested with using for example realtek nics (dont, pain in the ass), intel desktop nics (stable) or the more fancy server grade nics that have reported iSCSI offload? also have you tried using dedup/compresion for increased performance/space savings? this will use up lots of memory for indexies but if your cpus are fast enough along with network, less IO hits the discs. I hear it has worked assuming you have the memory, CPU, network. One last bit, try using the Sun 40GBs infiniband cards? I know they will work with solaris 10 and opensolaris and thus I would assume nexenta. might want to check the hardware compatibility list for your IB card.
Cheers
Mattbreitbach - Tuesday, October 5, 2010 - link
We have not tested with any other NIC's other than the Intel GB nics onboard the blade. We considered using an iSCSI offload NIC for the ZFS system, but given the cost of such cards we could not justify using them.As for Deduplication - we have recently tested using deduplication on Nexenta and the results were abysmal. Most tests were reading above 90% CPU utilization while delivering far lower IOPS. I believe that deduplication could help performance, but only if you have an insane amount of CPU available. With the checksumming and deduplication running our 5504 was simply not able to keep up. By increasing the core count, adding a second processor, and increasing the clock speed, it may be able to keep up, but after you spend that much additional capital on CPU's and better motherboards, you could increase your spindle count, switch to SAS drives, or simply add another storage unit for marginally more money.
MGSsancho - Tuesday, October 5, 2010 - link
from my personal experience i could not agree more for the deduplication. 33% on each core on my phenom 2 for a home setup is insane. Some things like exchange server, it is best to let the application decide what is should be cached but duplication realy make sense for a tier three storage or nightly backup or maybe for a small dev box. Also the drives them selves mater, you want to use the ones that are geared for raid setups. it allows the system to better communicate with it. I wont name a particular vendor but the current 'green' 5400 rpm 2TB drives are terrible for zfs http://pastebin.com/aS9Zbfeg (not my setup) that is a nightly backup array used at a webhosting facility. sure they have great throughput but all those errors after a few hours.andersenep - Tuesday, October 5, 2010 - link
I use WD green drives in my home OpenSolaris NAS. I have 2 raidz vdevs of 4 drives each (initially I used mirrors, but wanted more space). I can serve 720p content to two laptops and my Xstreamer simultaneously without a hiccup...I guess it depends on your needs, but for a home media server, I have absolutely no complaints with the 'green' drives. Weekly scrubs for 1 yr plus with no issues. I did have to replace a scorpio on my mirrored rpool after 6 months. I am quite happy with my setup.solori - Wednesday, October 20, 2010 - link
As a Nexenta partner, we see these issues all the time. Deduplication is not an apples-apples feature. The system build-out and deduplication set (affecting DDT size) are both unique factors.With ZFS' deduplication, RAM/ARC and L2ARC become critical components for performance. Deduplication tables that spill to disk (will not fit into memory) will cause serious performance issues. Likewise, the deduplication hash function and verify options will impact perfomance.
For each application, doing the math on spindle count (power, cost, space, etc.) versus effective deduplication is always best. Note that deduplication does not need to be enabled pool-wide, and that - like in compression where it is wasteful to compress pre-compressed data - data with low deduplication rates should not be allowed to dominate a deduplication-enabled pool/folder.
Deduplication of 15K, primary storage seems contradictory, but that type of storage has the highest $/TB factor and spindle count for any given capacity target. By allocating deduplication to targets folders/zvol, performance and capacity can be optimized for most use cases. Obviously, data sets that are write-heavy and sensitive to storage latency are not good candidates for deduplication or inline compression.
If you do the math, the cost of SSD augmentation of 7200 RPM SAS pools is very competitive against similar capacity 15K pools. The benefits to SSD augmentation (i.e. L2ARC and ZIL->SLOG where synchronous writes dominate performance profiles) is in higher IOP potential for random IO workloads (where the 7200 disks suffer most). In fact, contrasting 600GB SAS 15K to 2TB SAS 7200, you approach an economic factor where 7200 RPM disks favor mirror groups over 15K raidz groups - again, given the same capacity goals.
The real beauty of ZFS storage - whether it be Opensolaris/Illumos or Nexenta/Stor/Core - is that mixing 15K and 7200 RPM pools within the same system is very easy/effective to do. With the proper SAS controllers and JBOD/RBOD combinations, you can limit 15K applications to a small working set and commit bulk resources to augmented 7200 RPM spindles in robust raidz2 groups (i.e. watch your MTTDL versus raidz).
It is important to note that ZFS was not designed with the "home user" in mind. It can be very memory and CPU/thread hungry and easily out-strip a typical hobbyist's setup. A proper enterprise setup will include 2P quad core and RAM stores suited to the target workload. Since ZFS was designed for robust threading, the more "hardware" threads it has at its disposal, the more efficient it is. While snapshots are "free" in ZFS (i.e. copy-on-write nature of ZFS means writes are the same with or without snapshots) but data integrity (checksums) and compression/deduplication are not.
Mattbreitbach - Wednesday, October 20, 2010 - link
Excellent comments! Thank you for your input.As you noted, we found deduplication to be beyond the reaches of our system. With proper tuning and component selection, I think it could be used very well (and have talked to several people who have had very good experiences with it). For the average home user it's probably beyond the scope of what they would want to use for their storage.