Intel's Sandy Bridge Architecture Exposed
by Anand Lal Shimpi on September 14, 2010 4:10 AM EST- Posted in
- CPUs
- Intel
- Sandy Bridge
A Physical Register File
Just like AMD announced in its Bobcat and Bulldozer architectures, in Sandy Bridge Intel moves to a physical register file. In Core 2 and Nehalem, every micro-op had a copy of every operand that it needed. This meant the out-of-order execution hardware (scheduler/reorder buffer/associated queues) had to be much larger as it needed to accommodate the micro-ops as well as their associated data. Back in the Core Duo days that was 80-bits of data. When Intel implemented SSE, the burden grew to 128-bits. With AVX however we now have potentially 256-bit operands associated with each instruction, and the amount that the scheduling/reordering hardware would have to grow to support the AVX execution hardware Intel wanted to enable was too much.

A physical register file stores micro-op operands in the register file; as the micro-op travels down the OoO engine it only carries pointers to its operands and not the data itself. This significantly reduces the power of the out of order execution hardware (moving large amounts of data around a chip eats tons of power), it also reduces die area further down the pipe. The die savings are translated into a larger out of order window.
The die area savings are key as they enable one of Sandy Bridge’s major innovations: AVX performance.
The AVX instructions support 256-bit operands, which as you can guess can eat up quite a bit of die area. The move to a physical register file enabled Intel to increase OoO buffers to properly feed a higher throughput floating point engine. Intel clearly believes in AVX as it extended all of its SIMD units to 256-bit wide. The extension is done at minimal die expense. Nehalem has three execution ports and three stacks of execution units:
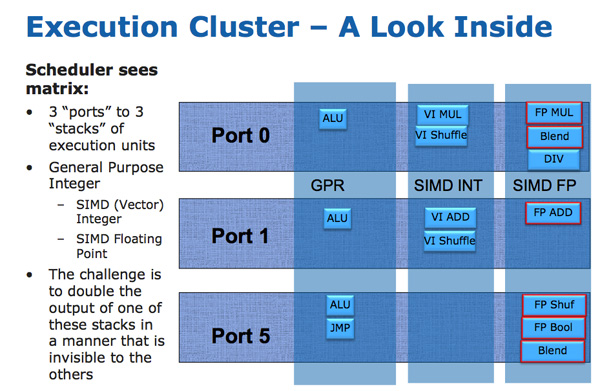
Sandy Bridge allows 256-bit AVX instructions to borrow 128-bits of the integer SIMD datapath. This minimizes the impact of AVX on the execution die area while enabling twice the FP throughput, you get two 256-bit AVX operations per clock (+ one 256-bit AVX load).
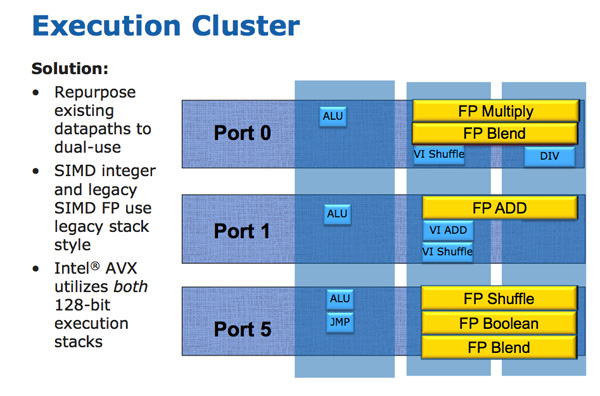
Granted you can’t mix 256-bit AVX and 128-bit integer SSE ops, however remember SNB now has larger buffers to help extract more ILP.
The upper 128-bits of the execution hardware and paths are power gated. Standard 128-bit SSE operations will not incur an additional power penalty as a result of Intel’s 256-bit expansion.
AMD sees AVX support in a different light than Intel. Bulldozer features two 128-bit SSE paths that can be combined for 256-bit AVX operations. Compared to an 8-core Bulldozer a 4-core Sandy Bridge has twice the 256-bit AVX throughput. Whether or not this is an issue going forward really depends on how well AVX is used in applications.
The improvements to Sandy Bridge’s FP performance increase the demands on the load/store units. In Nehalem/Westmere you had three LS ports: load, store address and store data.
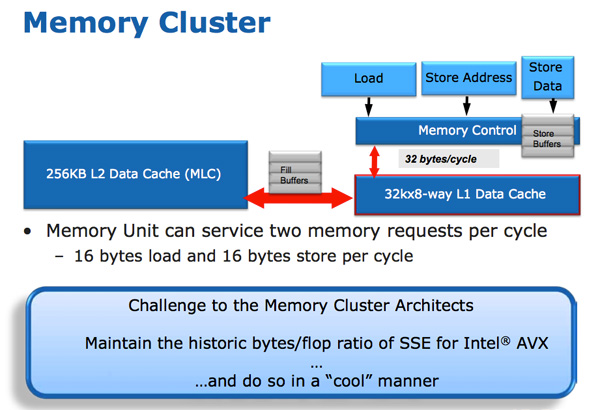
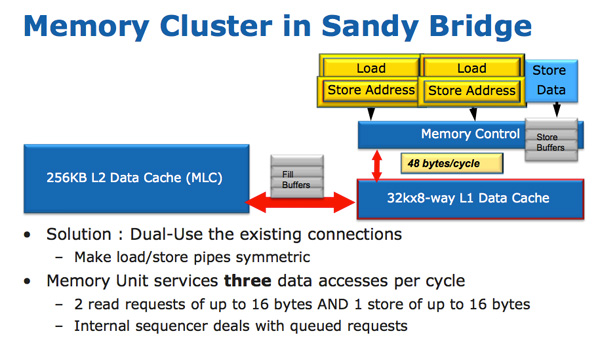
In SNB, the load and store address ports are now symmetric so each port can service a load or store address. This doubles the load bandwidth which is important as Intel doubled the peak floating point performance in Sandy Bridge.
There are some integer execution improvements in Sandy Bridge, although they are more limited. Add with carry (ADC) instruction throughput is doubled, while large scale multiplies (64 * 64) see a ~25% speedup.









62 Comments
View All Comments
markhennry - Monday, November 29, 2010 - link
wow awesome site about the computer parts i thinking buy a cpu and now i got a good help from this sites..katleo123 - Tuesday, February 1, 2011 - link
It is not expected to compete Core i7 processors to take its place
visit http://www.techreign.com/2010/12/intels-sandy-brid...