NVIDIA’s GeForce GTX 460: The $200 King
by Ryan Smith on July 11, 2010 11:54 PM EST- Posted in
- GPUs
- GeForce GTX 400
- GeForce GTX 460
- NVIDIA
The Rest of GF104
Besides adding superscalar dispatch abilities to GF104, NVIDIA has also made a number of other tweaks to the Fermi architecture for this GPU.
As a mid-range product, GF104 does not need to do 2 jobs at once. GF100 had to be usable as a desktop/professional graphics GPU, but also as a compute GPU for NVIDIA’s Tesla line of cards. GF104 will not be a Tesla product, so those compute abilities are not as critical. Specifically, NVIDIA has taken a chisel to Tesla’s flagship compute abilities of FP64 and ECC, which in GF100 desktop GPUs were artificially throttled and disabled respectively.
For GF104, ECC is completely gone. Barring the errant burst of solar radiation, the odds of a flipped bit or other error in the operation of a GPU is extremely slim. NVIDIA only added the feature for Tesla customers who demanded increased reliability as they could not accept a silent error in their work. For graphics however this is unnecessary, so the feature has been dropped.
Double-precision floating-point (FP64) on the other hand hasn’t been entirely dropped. Like ECC, FP64 is primarily a Tesla feature, but at the same time NVIDIA believes it to not be in their best interests to remove the feature. From NVIDIA’s perspective without FP64 on their consumer cards developers could not test and debug FP64 code on their desktops and laptops, which in turn would impede development for Tesla and hurt their efforts to expand in to the professional compute space. As a result GF104 has an interesting compromise on FP64.
For GF104, NVIDIA removed FP64 from only 2 of the 3 blocks of CUDA cores. As a result 1 block of 16 CUDA cores is FP64 capable, while the other 2 are not. This gives NVIDIA the advantage of being able to employ smaller CUDA cores for 32 of the 48 CUDA cores in each SM while not removing FP64 entirely. Because only 1 block of CUDA cores has FP64 capabilities and in turn executes FP64 instructions at 1/4 FP32 performance (handicapped from a native 1/2), GF104 will not be a FP64 monster. But the effective execution rate of 1/12th FP32 performance will be enough to effectively program in FP64 and debug as necessary.
Moving on, we have GF104’s texture units. GF100 was an interesting beast when it came to texturing, as it had texture units more efficient than GT200, but fewer of them overall. We don’t have any data that points to GF100 being absolutely deficient on texturing speeds, but at the same time it’s hard to imagine that GF100 was overbuilt to the point that losing 32 texture units wouldn’t hurt.
So for GF104, NVIDIA has doubled up on the number of texture units. A “full” GF104 has the same number of texture units at GF100 (64) in half as many SMs. NVIDIA tells us that this change is largely because texture units are small enough that they can be added without consuming too much additional die space, as opposed to requiring additional texture units such as a specific case of lacking texture performance or having too little texture performance relative to shading performance. But this isn’t something we can prove or disprove. High-detail settings optimized for high-end cards often go heavy on anti-aliasing or shading as opposed to textures, so ultimately we’re not surprised that NVIDIA kept the texture unit count constant while reducing the shader count in moving from GF100 to GF104. The shaders will be missed much less than the texture units would have been.
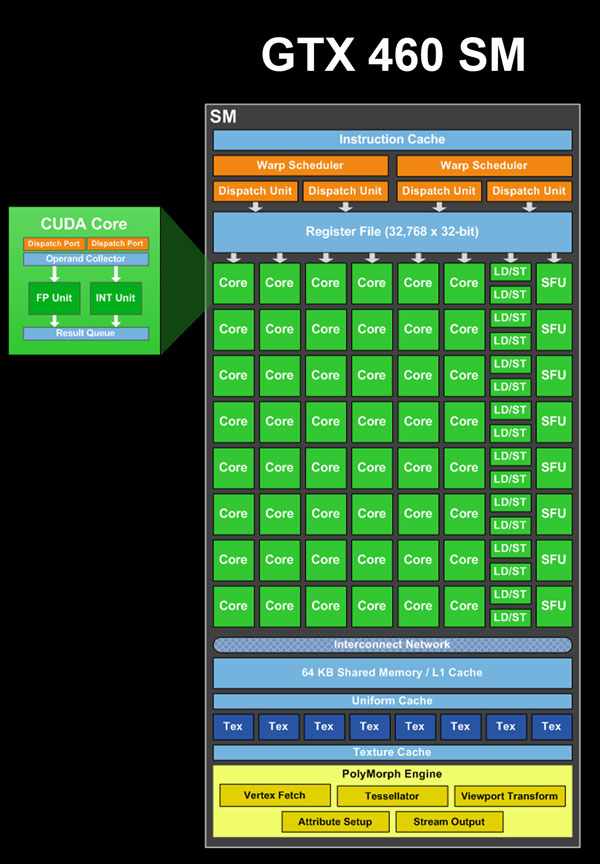
Finally, we have the ROPs. There haven’t been any significant changes here, but the ROP count does affect compute performance by impacting memory bandwidth and L2 cache. Even though NVIDIA keeps the same number of SMs on both the 1GB and 768MB of the GTX 460, the latter will have less L2 cache which may impact compute performance. Compute performance on the GTX 460 may also be impacted by pressure on the registers and L1 cache: NVIDIA increased the number of CUDA cores per SM, but not the size of the Register File or the amount of L1 cache/shared memory, so there are now additional CUDA cores fighting for the same resources. In the worst case scenarios, this can hurt the efficiency of GF104 compared to GF100.
For those of you who are curious, with all of these SM changes between GF100 and GF104 the size of a SM did increase, but by nearly as much as one would think: after adding the additional functional units, infusing the warp schedulers with superscalar dispatch capabilities, and removing unnecessary ECC and FP64 hardware, the size of an SM only increased by 25%. This is a tradeoff NVIDIA could not afford on the already massive GF100, but made sense on GF104 where the performance increase could justify the extra die space.








93 Comments
View All Comments
Howard - Monday, July 12, 2010 - link
What?Zok - Monday, July 12, 2010 - link
Excellent writeup! I really enjoyed you going into depth on the architectural changes. I couldn't agree more that it's superb to see NVIDIA get back into the efficiency game - whether it be performance/price or performance/watt (and, by extension, temperature). Here's to hoping that AMD was sitting on something to combat this!P.S. Small typo: For everything but the high-end, this year is a feature yet and not a performance year.
thekimbobjones - Monday, July 12, 2010 - link
Let the price war begin.homerdog - Monday, July 12, 2010 - link
"Here we use the DX11 renderer and turn on self shadowing ambient occlusion (SSAO) to its highest setting, which uses a DX11 ComputeShader."I don't think that's what SSAO stands for. Sorry for the nitpick.
chizow - Monday, July 12, 2010 - link
Yeah I believe the proper term is Screen Space Ambient Occlusion but self shadowing is how its often explained to give an idea of what it is.gentlearc - Monday, July 12, 2010 - link
The graphs shown are leaving out too many new derivatives of cards, making is good for contrasting results, but poor for consistent data comparison. Conveniently left out are many cards in one graph that are in another. I'm disappointed in your presentation and find you've concentrated too much on the presentation of your article.Ryan Smith - Monday, July 12, 2010 - link
Out of curiosity, what's not in our graphs that you'd like to see? At 2560 we run a limited number of cards because most cards are too slow to post a passable framerate, otherwise at 1920 and 1680 we have the complete 5700/5800/5900 series, GTX 400 series, GTX 200 series, and Radeon 4800 series, along with a 3870 and 8800GT. Is there something else you would like?SpaceRanger - Monday, July 12, 2010 - link
What I'd like to see is the ATI card that is in direct competition with this highlighted as well. Having to search for the 5830 or 5850 out of all those bars turned me off.estaffer - Monday, July 12, 2010 - link
need some cheese with your whine?SpaceRanger - Monday, July 12, 2010 - link
Sure.. a good Gruyère please...