NVIDIA’s GeForce GTX 460: The $200 King
by Ryan Smith on July 11, 2010 11:54 PM EST- Posted in
- GPUs
- GeForce GTX 400
- GeForce GTX 460
- NVIDIA
Compute & Tessellation Performance
With our earlier discussion on the GF104’s revised architecture in mind, along with our gaming benchmarks we have also run a selection of compute and tessellation benchmarks specifically to look at the architecture. Due to the fact that NVIDIA added an additional block of CUDA cores to an SM without adding another warp scheduler, the resulting superscalar design requires that the card extract ILP from the warps in order to simultaneously utilize all 3 blocks of CUDA cores.
As a result the range of best case to worst case scenarios is wider on GF104 than it is GF100: while GF100 could virtually always keep 2 warps going and reach peak utilization, GF104 can only reach peak utilization when at least 1 of the warps has an ILP-safe instruction waiting to go, otherwise the 3rd block of CUDA cores is effectively stalled and a GTX 460 performs more like a 224 CUDA core part. Conversely with a total of 4 dispatch units GF104 is capable of exceeding GF100’s efficiency by utilizing 4 of 7 execution blocks in an SM instead of 2 of 6.
Or in other words, GF104 has the possibility of being more or less efficient than GF100.
For our testing we’re utilizing a GTX 480, a GTX 465, and both versions of the GTX 460, the latter in particular to see if the lack of L2 cache or memory bandwidth will have a significant impact on compute performance. Something to keep in mind is that with its higher clockspeed, the GTX 460 has more compute performance on paper than the GTX 465 – 907GFLOPs for the GTX 460, versus 855GFLOPs for the GTX 465. As such the GTX 460 has the potential to win, but only when it can extract enough ILP to keep the 3rd block of CUDA cores working. Otherwise the worst case scenario – every math instruction is dependent – is 605GFLOPs for the GTX 460. Meanwhile the GTX 480 is capable of 1344GFLOPs, which means the GTX 465 and GTX 460 are 63% and 45%-67% as fast as it on paper respectively.
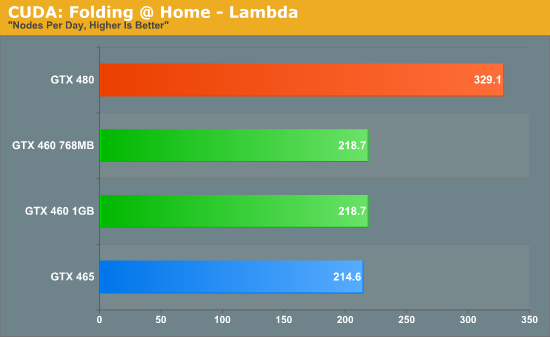
We’ll start with Stanford’s Folding@Home client. Here we’re using the same benchmark version of the client as from our GTX 480 article, running the Lambda work-unit. In this case we almost have a tie between the GTX 460 and the GTX 465, with the two differing by only a few nodes per day. The GTX 465 reaches 65% of the performance of the GTX 480 here, which is actually beyond the theoretical performance difference. In this case it’s likely that the GTX 480 may be held back elsewhere, allowing slower cards to shorten the gap by some degree.
With that in mind the GTX 460 cards achieve 66% of the performance of the GTX 480 here, giving them a slight edge over the GTX 465. Because we’ve seen the GTX 465 pull off better than perfect scaling here it’s very unlikely that the GTX 460 is actually achieving a perfect ILP scenario here, but clearly it must be close. Folding@Home is clearly not L2 cache or memory bandwidth dependent either, as the 768MB version of the GTX 460 does no worse than its 1GB counterpart.
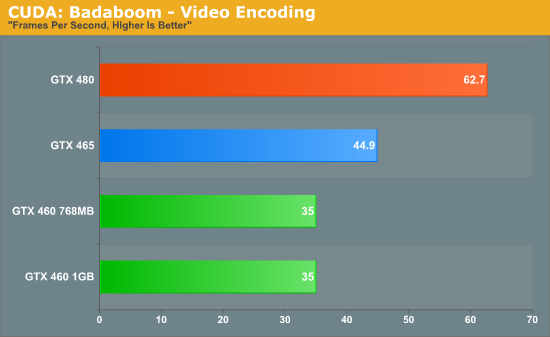
Next up on our list of compute benchmarks is Badaboom, the CUDA-based video encoder. Here we’re measuring the average framerate for the encode of a 2 minute 1080i video cap. Right off the bat we’re seeing dramatically different results than we saw with Folding@Home, with the GTX 460 cards falling well behind the GTX 465. It’s immediately clear here that Badaboom is presenting a sub-optimal scenario for the GTX 460 where the GPU cannot effectively extract much ILP from the program’s warps. At 56% the speed of a GTX 480, this is worse off than what we saw with Folding@Home but is also right in the middle of our best/worst case scenarios – if anything Badaboom is probably very close to average.
Meanwhile this is another program with the lack of memory bandwidth and L2 cache is not affecting the 768MB card in the slightest, as it returns the same 35fps rate as the 1GB card.

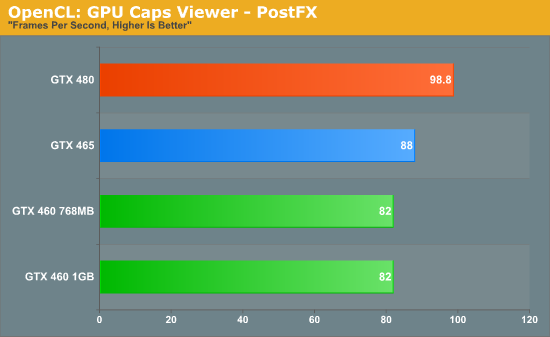
Our third and final compute benchmark is the PostFX OpenCL benchmark from GPU Caps Viewer. The PostFX benchmark clearly isn’t solely compute limited on the GTX 400 series, giving us a fairly narrow range of results that are otherwise consistent with the Badaboom. At 82fps, this puts the GTX 460 below the GTX 465 by around 7%, once again showcasing that the superscalar GTX 460 has more trouble achieving its peak efficiency than the more straightforward GTX 465.

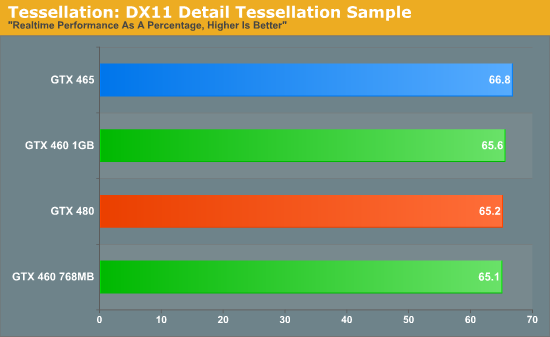
Our final benchmark is a quick look at tessellation. As GF104 packed more CUDA cores in to a SM, the GPU has more than half the compute capabilities of GF100 but only a straight 50% the geometry capabilities. Specifically, the GTX 460 has 45% of the geometry capabilities of the GTX 480 after taking in to account the number of active SMs and the clockspeed difference.
With the DirectX 11 Detail Tessellation sample program, we’re primarily looking at whether we can throw a high enough tessellation load at the GPU to overwhelm its tessellation abilities and bring it to its knees. In this case we cannot, as the GTX 460 scales from tessellation factor 7 to tessellation factor 11 by basically the same rate as the GTX 480 and GTX 465. This means that the GTX 460 still has plenty of tessellation power for even this demanding sample, but by the same measure it showcases than the GTX 480 is overbuilt if future games target GTX 460 for tessellation.
All things considered our compute and tessellation results are where we expected them to be. That is to say that the GTX 460’s wider range of best and worst case scenarios will show up in real-world programs, making its performance relative to a GTX 465 strongly application dependent. While the GF104 GPU’s architectural changes seem to be well tuned for gaming needs and leading to the GTX 460 meeting or beating the GTX 465, the same can’t be said for compute. At this point it would be a reasonable assumption that the GTX 465 is going to outperform the GTX 460 in most compute workloads, so the relevance of this for buyers is going to be how often they’re doing compute workloads and whether they can deal with the GTX 465’s lower power efficiency.








93 Comments
View All Comments
Howard - Monday, July 12, 2010 - link
What?Zok - Monday, July 12, 2010 - link
Excellent writeup! I really enjoyed you going into depth on the architectural changes. I couldn't agree more that it's superb to see NVIDIA get back into the efficiency game - whether it be performance/price or performance/watt (and, by extension, temperature). Here's to hoping that AMD was sitting on something to combat this!P.S. Small typo: For everything but the high-end, this year is a feature yet and not a performance year.
thekimbobjones - Monday, July 12, 2010 - link
Let the price war begin.homerdog - Monday, July 12, 2010 - link
"Here we use the DX11 renderer and turn on self shadowing ambient occlusion (SSAO) to its highest setting, which uses a DX11 ComputeShader."I don't think that's what SSAO stands for. Sorry for the nitpick.
chizow - Monday, July 12, 2010 - link
Yeah I believe the proper term is Screen Space Ambient Occlusion but self shadowing is how its often explained to give an idea of what it is.gentlearc - Monday, July 12, 2010 - link
The graphs shown are leaving out too many new derivatives of cards, making is good for contrasting results, but poor for consistent data comparison. Conveniently left out are many cards in one graph that are in another. I'm disappointed in your presentation and find you've concentrated too much on the presentation of your article.Ryan Smith - Monday, July 12, 2010 - link
Out of curiosity, what's not in our graphs that you'd like to see? At 2560 we run a limited number of cards because most cards are too slow to post a passable framerate, otherwise at 1920 and 1680 we have the complete 5700/5800/5900 series, GTX 400 series, GTX 200 series, and Radeon 4800 series, along with a 3870 and 8800GT. Is there something else you would like?SpaceRanger - Monday, July 12, 2010 - link
What I'd like to see is the ATI card that is in direct competition with this highlighted as well. Having to search for the 5830 or 5850 out of all those bars turned me off.estaffer - Monday, July 12, 2010 - link
need some cheese with your whine?SpaceRanger - Monday, July 12, 2010 - link
Sure.. a good Gruyère please...