Corsair's Force SSD Reviewed: SF-1200 is Very Good
by Anand Lal Shimpi on April 14, 2010 2:27 AM ESTSequential Read/Write Speed
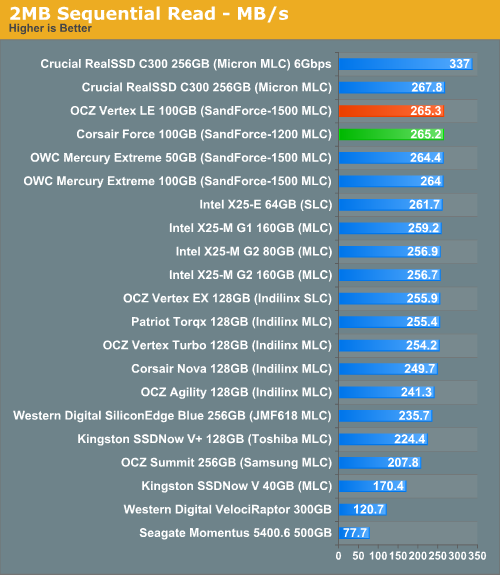
Using the 6-22-2008 build of Iometer I ran a 3 minute long 2MB sequential test over the entire span of the drive. The results reported are in average MB/s over the entire test length:
I'll go ahead and ruin the surprise right now - in the synthetic tests, you can't tell the difference between the Vertex LE and Corsair's Force drive. The two are identical performers. And it's not a bad thing, because they're both among the best.









63 Comments
View All Comments
JohnQ118 - Thursday, April 15, 2010 - link
Just in case if you are using IE8 - open the Print view; then simply from the View menu select Style - No Style.You will get some small margins. Then adjust the window size as comfortable for reading.
remosito - Wednesday, April 14, 2010 - link
Hi there,thanks for the great review. I couldn't find from the article what kind of data you are writing
for the random 4k read/write tests. Those random write numbers look stellar.
Which might have to do with the data being written being not very random at all and allowing for big gain coming from the sandforce voodoo/magicsauce/compression???
Mr Alpha - Wednesday, April 14, 2010 - link
I believe the build of IOMeter he uses writes randomized data.shawkie - Wednesday, April 14, 2010 - link
This is a very important question - nobody is interested in how quickly they can write zeroes to their drive. If these benchmarks are really writing completely random data (which by definition cannot be compressed at all) then where does all this performance come from? It seems to me that we have a serious problem benchmarking this drive. If the bandwidth of the NAND were the only limiting factor (rather than the SATA interface or the processing power of the controller) then the speed of this drive should be anything from roughly the same as a similar competitor (for completely random data) to maybe 100x faster (for zeroes). So to get any kind of useful number you have to decide exactly what type of data you are going to use (which makes it all a bit subjective). In fact, there's another consideration. Note that the spare NAND capacity made available by the compression is not available to the user. That means the controller is probably using it to augment the reserved NAND. This means that a drive that has been "dirtied" with lots of nice compressable data will perform as though it has a massive amount of reserved NAND whereas a drive that has been "dirtied" with lots of random data will perform much worse.nafhan - Wednesday, April 14, 2010 - link
My understanding is that completely random and uncompressible are not the same thing. An uncompressible data set would need to be small and carefully constructed to avoid repetition. A random data set by definition is random, and therefore almost certain to contain repetitions over a large enough data set.jagerman42 - Wednesday, April 14, 2010 - link
No; given a random sequence of 0/1 bits with equal probability of each, the expected number of bits to encode the stream (i.e. on average--you could, through extremely unlikely outcome, have a compressible random sequence: e.g. a stream of 1 million 0's is highly compressible, but also extremely unlikely, at 2^(-1,000,000) probability of occurrence).So onwards to the entropy bits required calculation: H = -0.5*log2(0.5) -0.5*log2(0.5) = -0.5*(-1) -0.5*(-1) = 1.
In other words, a random, equal-probability stream of bits can't be compressed at a rate better than 1 bit per bit.
Of course, this only holds for an infinite, continuous stream; as you shorten the length of the data, the probability of the data being compressible increases, at least slightly--but even 1KB is 8192 bits, so compressibility is *hard*.
Just for example's sake, I generated a few (10 bytes to 10MB) random data files, and compressed using gzip and bzip2: in every case (I repeated several times) the compressed version ended up larger than the original.
For more info on this (it's called the Shannon theory, I believe, or also "Shannon entropy" according to the following), see: http://en.wikipedia.org/wiki/Entropy_(information_...
shawkie - Wednesday, April 14, 2010 - link
I'm also not convinced by the way Anand has arrived at a compression factor of 2:1 based on the power consumption. The specification for the controller and Anand's own measurements show that about 0.57W of power is being used just by the controller. That only leaves 0.68W for writing data to NAND. Compare that with 2.49W for the Intel drive and you end up with a compression factor of more like 4:1. But actually this calculation is still a long way out because 2MB/s sequential writes are 250MB/s on the SandForce and only 100MB/s on the Intel. So we've written 2.5x as much (uncompressed) data using 1/4 as much NAND power consumption. So the compression factor is actually more like 10:1. I think that pretty much proves we're dealing with very highly compressable data.HammerDB - Wednesday, April 14, 2010 - link
That should definitely be checked, as this is the first drive where different kinds of data will perform differently. Due to the extremely high aligned random write performance, I suspect that the data written is either compressible or repeated, so the drive manages to either compress or deduplicate to a large degree.One other point regarding the IOMeter tests: the random reads perform almost identical to the unaligned random writes. Would it be possible to test both unaligned and aligned random reads, in order to find out if the drive is also capable of faster random reads under specific circumstances?
Anand Lal Shimpi - Wednesday, April 14, 2010 - link
Correct. The June 08 RC build of Iometer uses randomized data. Older versions used 0s.Take care,
Anand
shawkie - Wednesday, April 14, 2010 - link
Anand, do you therefore have any explanation for why the SandForce controller is apparently about 10x more efficient than the Intel one even on random (incompressible) data? Or can you see a mistake in my analysis?