NVIDIA’s GeForce GTX 480 and GTX 470: 6 Months Late, Was It Worth the Wait?
by Ryan Smith on March 26, 2010 7:00 PM EST- Posted in
- GPUs
Compute
Update 3/30/2010: After hearing word after the launch that NVIDIA has artificially capped the GTX 400 series' double precision (FP64) performance, we asked NVIDIA for confirmation. NVIDIA has confirmed it - the GTX 400 series' FP64 performance is capped at 1/8th (12.5%) of its FP32 performance, as opposed to what the hardware natively can do of 1/2 (50%) FP32. This is a market segmentation choice - Tesla of course will not be handicapped in this manner. All of our compute benchmarks are FP32 based, so they remain unaffected by this cap.
Continuing at our look at compute performance, we’re moving on to more generalized compute tasks. GPGPU has long been heralded as the next big thing for GPUs, as in the right hands at the right task they will be much faster than a CPU would be. Fermi in turn is a serious bet on GPGPU/HPC use of the GPU, as a number of architectural tweaks went in to Fermi to get the most out of it as a compute platform. The GTX 480 in turn may be targeted as a gaming product, but it has the capability to be a GPGPU powerhouse when given the right task.
The downside to GPGPU use however is that a great deal of GPGPU applications are specialized number-crunching programs for business use. The consumer side of GPGPU continues to be underrepresented, both due to a lack of obvious, high-profile tasks that would be well-suited for GPGPU use, and due to fragmentation in the marketplace due to competing APIs. OpenCL and DirectCompute will slowly solve the API issue, but there is still the matter of getting consumer orientated GPGPU applications out in the first place.
With the introduction of OpenCL last year, we were hoping by the time Fermi was launched that we would see some suitable consumer applications that would help us evaluate the compute capabilities of both AMD and NVIDIA’s cards. That has yet to come to pass, so at this point we’re basically left with synthetic benchmarks for doing cross-GPU comparisons. With that in mind we’ve run a couple of different things, but the results should be taken with a grain of salt as they don’t represent any single truth about compute performance on NVIDIA or AMD’s cards.
Out of our two OpenCL benchmarks, we’ll start with an OpenCL implementation of an N-Queens solver from PCChen of Beyond3D. This benchmark uses OpenCL to find the number of solutions for the N-Queens problem for a board of a given size, with a time measured in seconds. For this test we use a 17x17 board, and measure the time it takes to generate all of the solutions.
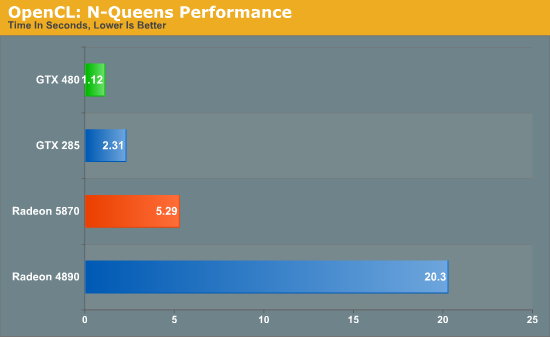
This benchmark offers a distinct advantage to NVIDIA GPUs, with the GTX cards not only beating their AMD counterparts, but the GTX 285 also beating the Radeon 5870. Due to the significant underlying differences of AMD and NVIDIA’s shaders, even with a common API like OpenCL the nature of the algorithm still plays a big part in the performance of the resulting code, so that may be what we’re seeing here. In any case, the GTX 480 is the fastest of the GPUs by far, beating out the GTX 285 by over half the time, and coming in nearly 5 times faster than the Radeon 5870.
Our second OpenCL benchmark is a post-processing benchmark from the GPU Caps Viewer utility. Here a torus is drawn using OpenGL, and then an OpenCL shader is used to apply post-processing to the image. Here we measure the framerate of the process.

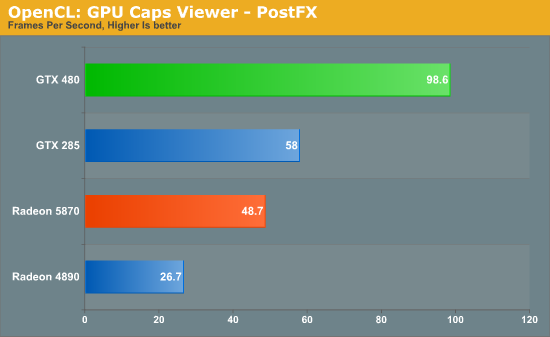
Once again the NVIDIA cards do exceptionally well here. The GTX 480 is the clear winner, while even the GTX 285 beats out both Radeon cards. This could once again be the nature of the algorithm, or it could be that the GeForce cards really are that much better at OpenCL processing. These results are going to be worth keeping in mind as real OpenCL applications eventually start arriving.
Moving on from cross-GPU benchmarks, we turn our attention to CUDA benchmarks. Better established than OpenCL, CUDA has several real GPGPU applications, with the limit being that we can’t bring the Radeons in to the fold here. So we can see how much faster the GTX 480 is over the GTX 285, but not how this compares to AMD’s cards.
We’ll start with Badaboom, Elemental Technologies’ GPU-accelerated video encoder for CUDA. Here we are encoding a 2 minute 1080i clip and measuring the framerate of the encoding process.
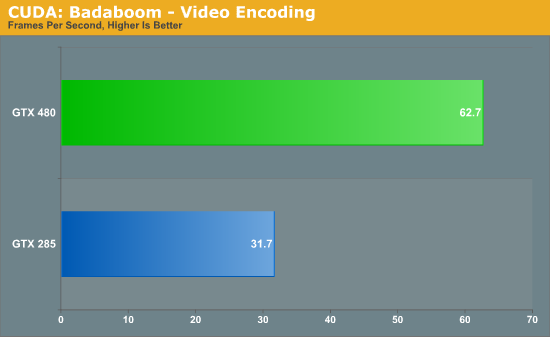
The performance difference with Badaboom is rather straightforward. We have twice the shaders running at similar clockspeeds, and as a result we get twice the performance. The GTX 480 encodes our test clip in a little over half the time it took the GTX 280.
Up next is a special benchmark version of Folding@Home that has added Fermi compatibility. Folding@Home is a Standford research project that simulates protein folding in order to better understand how misfolded proteins lead to diseases. It has been a poster child of GPGPU use, having been made available on GPUs as early as 2006 as a Close-To-Metal application for AMD’s X1K series of GPUs. Here we’re measuring the time it takes to fully process a sample work unit so that we can project how many nodes (units of work) a GPU could complete per day when running Folding@Home.
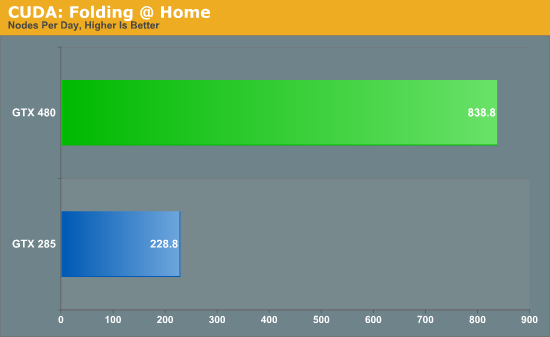
Folding@Home is the first benchmark we’ve seen that really showcases the compute potential for Fermi. Unlike everything else which has the GTX 480 running twice as fast as the GTX 285, the GTX 480 is a fewtimes faster than the GTX 285 when it comes to folding. Here a GTX 480 would get roughly 3.5x as much work done per day as a GTX 285. And while this is admittedly more of a business/science application than it is a home user application (even if it’s home users running it), it gives us a glance at what Fermi is capable when it comes to compuete.
Last, but not least for our look at compute, we have another tech demo from NVIDIA. This one is called Design Garage, and it’s a ray tracing tech demo that we first saw at CES. Ray tracing has come in to popularity as of late thanks in large part to Intel, who has been pushing the concept both as part of their CPU showcases and as part of their Larrabee project.
In turn, Design Garage is a GPU-powered ray tracing demo, which uses ray tracing to draw and illuminate a variety of cars. If you’ve never seen ray tracing before it looks quite good, but it’s also quite resource intensive. Even with a GTX 480, with the high quality rendering mode we only get a couple of frames per second.
On a competitive note, it’s interesting to see NVIDIA try to go after ray tracing since that has been Intel’s thing. Certainly they don’t want to let Intel run around unchecked in case ray tracing and Larrabee do take off, but at the same time it’s rasterization and not ray tracing that is Intel’s weak spot. At this point in time it wouldn’t necessarily be a good thing for NVIDIA if ray tracing suddenly took off.
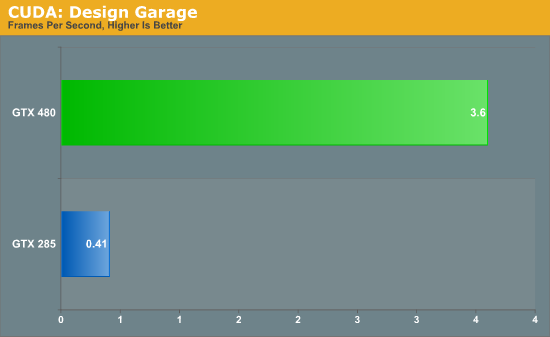
Much like the Folding@Home demo, this is one of the best compute demos for Fermi. Compared to our GTX 285, the GTX 480 is eight times faster at the task. A lot of this comes down to Fermi’s redesigned cache, as ray tracing as a high rate of cache hits which help to avoid hitting up the GPU’s main memory any more than necessary. Programs that benefit from Fermi’s optimizations to cache, concurrency, and fast task switching apparently stand to gain the most in the move from GT200 to Fermi.








196 Comments
View All Comments
palladium - Saturday, March 27, 2010 - link
clock for clock, the 920 is faster than the 860 thanks to its triple channel memory - the 860 is faster because of its aggressive turbo mode. X58 is definitely the route to go, espeacially if you're benchmarking SLI/CF setups (dual PCIe x16).randfee - Sunday, March 28, 2010 - link
go ahead and try Crysis with 3,33GHz and 4,x, minimum fps scale strangely with the CPU.palladium - Saturday, March 27, 2010 - link
shit double post, srypalladium - Saturday, March 27, 2010 - link
Clock for clock, the 920 is faster than the 860 (860 is faster because of its aggressive turbo mode). Using the P55/860 would limit cards to PCIe x8 bandwidth when benchmarking SLI/CF (unless of course you get a board with nF200 chip), which can be more significant (espeacially with high-end cards) than a OC-ing a CPU from 3.33GHz to 4GHz.Roland00 - Saturday, March 27, 2010 - link
It doesn't really add to the framerates, and having a 4ghz cpu could in theory bring stability issues.http://www.legionhardware.com/articles_pages/cpu_s...">http://www.legionhardware.com/articles_...scaling_...
B3an - Friday, March 26, 2010 - link
You're good at making yourself look stupid.A 920 will reach 4GHz easy. I've got one to 4.6GHz. And a 920 is for the superior X58 platform and will have Tri-Channel memory.
Makaveli - Friday, March 26, 2010 - link
I have to agree with that guy.Your post is silly everyone knows the X58 platform is the superior chipset in the intel line up. Secondly do you honestly think 3.33Ghz vs 4Ghz is going to make that much of a difference at those high resolutions?
randfee - Friday, March 26, 2010 - link
sorry guys but I know what I'm talking about, using Crysis for instance, I found that minimum fps scale quite nicely with CPU clock whereas the difference a quad core makes is not so big (only 2 threads in the game afaik). FarCry 2, huge improvements with higher end (=clocked) cpus. The Core i7 platform has a clear advantage, yes, but the clock counts quite a bit.As I said... no offense intended and no, not arguing against my favorite site anandtech ;). Just stating what I and others have observed. I'd just always try and minimize other possible bottlenecks.
randfee - Friday, March 26, 2010 - link
well.... why not test using the 920 @ 4.xGHz, why possibly bottleneck the System at the CPU by using "only" 3,3?No offense intended but I find it a valid question. Some games really are CPU bound, even at high settings.
Ph0b0s - Friday, March 26, 2010 - link
These new cards from ATI and Nvidia are very nice and for a new PC build it is a no brainer, to pick up one of these cards. But for those like me with decent cards from the last generation (GTX285 SLI) I don't really feel a lot of pressure to upgrade.Most current PC games are Directx 9 360 ports that last gen cards can handle quite well. Even Directx 10 games are not too slow. The real driver for these cards are Directx 11 games, the amount of which I can count on one hand and not very many upcomming.
Those that are out don't really bring much over DX10 so I don't really feel like I am missing anything yet. I think Crysis 2 may change this, but by it's release date there will probably be updated / shrunk versions of these new GPU's avaliable.
Hence why Nvidia and ATI need really ecstatic reviews to convince us to buy their new cards when there is not a lot of software that (in my opinion) really needs them.