GF100’s Gaming Architecture
Although it feels like ages ago, NVIDIA announced the Fermi architecture back in September of 2009, focusing on the compute abilities of the GPU that would be GF100. Today’s announcement is about filling in the blanks – where does the graphics hardware fit in to the design that NVIDIA revealed earlier.
As a quick refresher, the GF100 is composed of 512 SPs, which NVIDIA now calls CUDA cores. Each CUDA core is organized in to a block of 32 cores which we call a Streaming Multiprocessor (SM), which in turn are laid out so that 4 of them are in a Graphics Processing Cluster (GPC). Finally, there are 4 GPCs in a single GF100 chip. 32x4x4 = 512 CUDA cores.
| GF100 | GT200x2 (GTX 295) | GT200 (GTX 285) | G92 (9800+ GTX) | |
| Stream Processors | 512 | 2 x 240 | 240 | 128 |
| Texture Address / Filtering | 64/256 | 2 x 80 / 80 | 80 / 80 | 64 / 64 |
| ROPs | 48 | 2x 28 | 32 | 16 |
| Core Clock | ? | 576MHz | 648MHz | 738MHz |
| Shader Clock | ? | 1242MHz | 1476MHz | 1836MHz |
| Memory Clock | ? GDDR5 | 999MHz (1998MHz data rate) GDDR3 | 1242MHz (2484MHz data rate) GDDR3 | 1100MHz (2200MHz data rate) GDDR3 |
| Memory Bus Width | 384-bit | 2 x 448-bit | 512-bit | 256-bit |
| Frame Buffer | ? | 2 x 896MB | 1GB | 512MB |
| Transistor Count | 3B | 2 x 1.4B | 1.4B | 754M |
| Manufacturing Process | TSMC 40nm | TSMC 55nm | TSMC 55nm | TSMC 55nm |
| Price Point | $? | $500 | $400 | $150 - 200 |
When NVIDIA first unveiled GF100, we did not know anything about the ROPs, texture units, or any of the fixed-function graphics units that are customary in a GPU. Today we now have that information, and can discuss where it goes.
While GF100 resembles GT200 in a number of ways as a compute GPU, as a gaming GPU it’s very close to being a complete departure from GT200. The big change here is that the single block of fixed-function hardware as we know it is gone. Virtually every piece of hardware has been split up and moved down a level, and can now be found as part of a GPC or as a SM. NVIDIA’s GF100 block diagram does a good job of showing this.
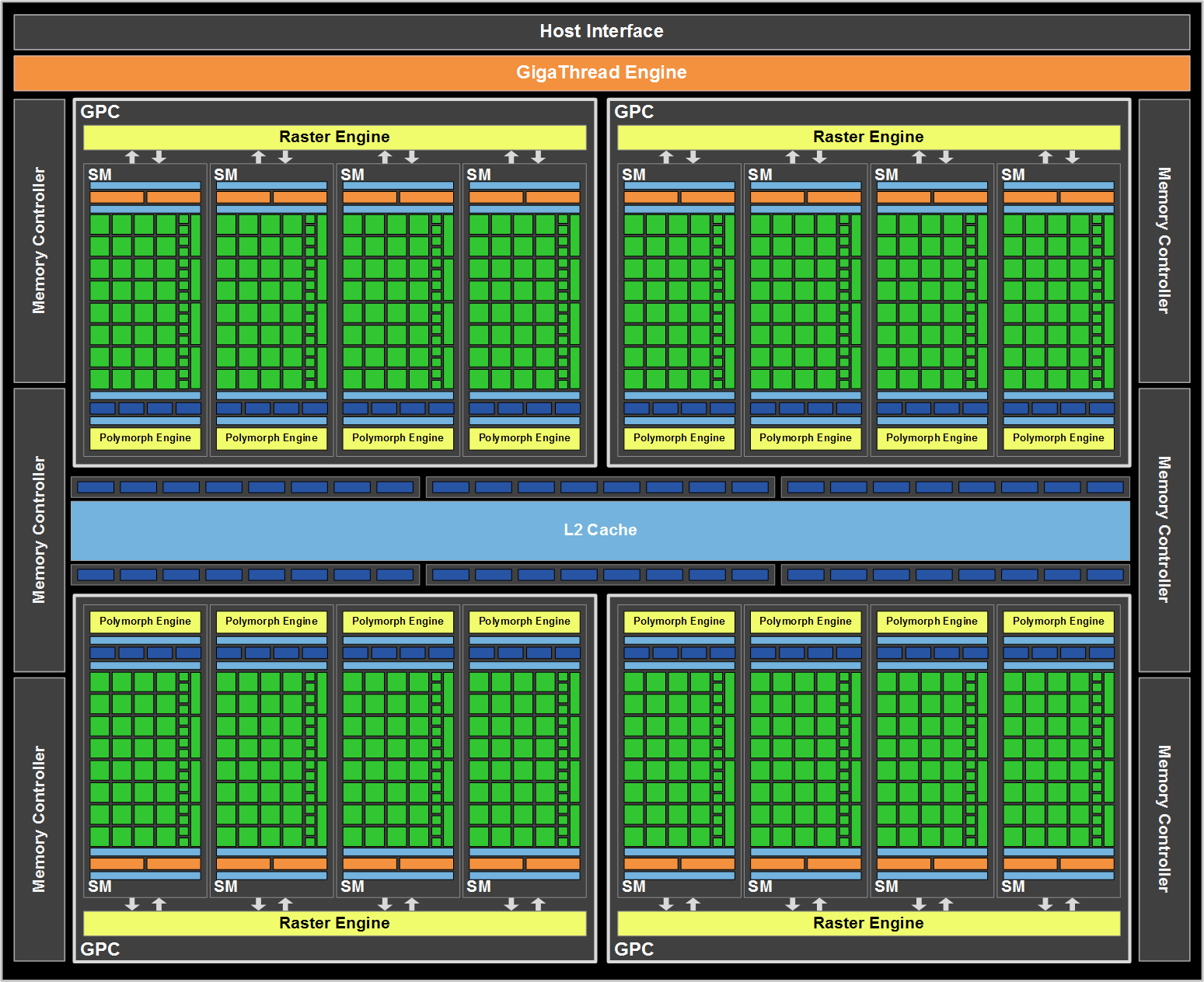
What’s left of the fixed function hardware is the GigaThread Engine, which is what NVIDIA is calling their scheduler. To understand where our fixed function hardware went, we must meet the newest execution units: The PolyMorph Engine and the Raster Engine.

We’ll start with the Raster Engine. The Raster Engine is the combination of all the raster related hardware that we would have found previously in the fixed function pipeline. It does edge/triangle setup, rasterization, and z-culling in a pipelined manner. Each GPC has its own Raster Engine. NVIDIA has very little to say about the Raster Engine, but very little has changed from GT200 besides the fact that there are now 4 of them (one for each GPC) as opposed to 1 larger block. Each rasterizer can do 8 pixels per clock, for a total of 32 pixels per clock over the entirety of GF100.
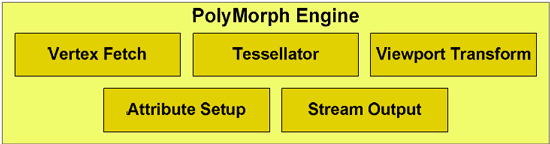
The much more important of the two new execution units is the PolyMorph Engine, which is what NVIDIA is calling the execution unit that handles geometry for GF100. The PolyMorph Engine is responsible for handling Vertex Fetch, Tessellation, Viewport Transform, Attribute Setup, and Stream Output. It’s here where the Tessellator is located, one of the biggest changes that DX11 is bringing to GPU design. Unlike the Raster Engine, each SM has a PolyMorph Engine, giving the GF100 16 PolyMorph Engines altogether.
While the PolyMoprh Engine may sound simple in its description, don’t let it fool you. NVIDIA didn’t just move their geometry hardware to a different place, clone it 15 times, and call it a day. This was previously fixed-function hardware where a single unit sat in a pipeline and did its share of the work. By splitting up the fixed-function pipeline like this, NVIDIA in actuality created a lot of work for themselves. Why? Out of order execution.
OoO is something we usually reserve for CPUs, where high-end CPUs are built to execute instructions out of order in order to extract more performance out of them through instruction level parallelism. OoO is very hard to accomplish, because you can only execute certain instructions ahead of other ones while maintaining the correct result for your data. Execute an add instruction that relies on a previous operation before that’s done, and you have problems. GF100 isn’t a full OoO design, so we’re not going to cover OoO in-depth here, but if you’d like to know more please see this article.
At any rate, internally each PolyMorph Engine is still a simple in-order design. NVIDIA hasn’t gone so far as to make a PolyMorph Engine an OoO design – but because there are 16 of them when there used to be just 1, OoO hazards can occur just as they would in an OoO executing CPU. NVIDIA now has to keep track of what each PolyMorph Engine is doing in respect to the other 15, and put the brakes on any of them that get too far ahead in order to maintain the integrity of results.
To resolve the hazards of OoO, GF100 has a private communication channel just for the PolyMorph Engines that allows them to stay together on a task in spite of being spread apart. The fact of the matter is that all of the work that goes in to making a design like this work correctly is an immense amount of effort, and NVIDIA’s engineers are quite proud of this effort. They have taken the monolithic design of prior GPUs’ geometry units, and made it parallel. We can’t overstate how much of an engineering challenge this is.
However all of this work came at a cost, and not just the significant engineering resources NVIDIA threw at GF100. The other cost was time – we believe that the PolyMorph Engine is the single biggest reason that GF100 didn’t make it out last year. It’s the single biggest redesign of any component in GF100, and is something that NVIDIA had to start virtually from scratch on. When NVIDIA told us that designing a big GPU is hard, this is what they had in mind.
Now why did NVIDIA put themselves through all of this? Because in their eyes, they had to. The use of a fixed-function pipeline in their eyes was a poor choice given the geometric complexity that a tessellator would create, and hence the entire pipeline needed to be rebalanced. By moving to the parallel design of the PolyMorph Engine, NVIDIA’s geometry hardware is no longer bound by any limits of the pipelined fixed-function design (such as bottlenecks in one stage of the pipeline), and for better or for worse, they can scale their geometry and raster abilities with the size of the chip. A smaller GF100 derivative will not have as many PolyMorph or Raster units as GF100, and as a result won’t have the same level of performance; G92 derivatives and AMD’s designs both maintain the same fixed function pipeline through all chips, always offering the same level of performance.

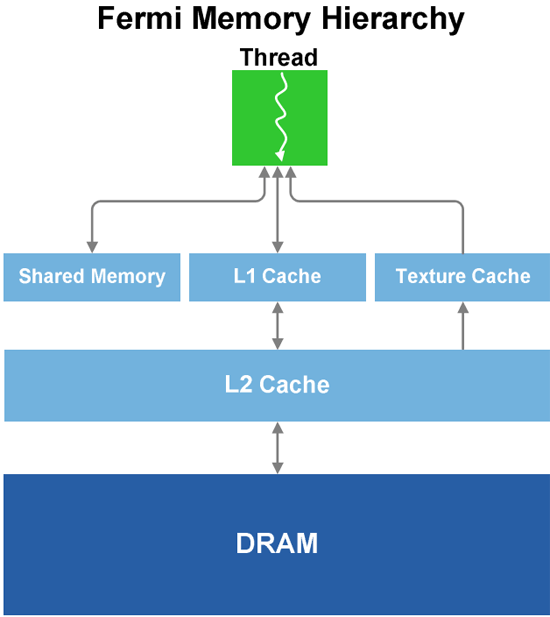
Speaking of performance, we’ll get to that in a bit, but for now we’ll finish our discussion of GF100’s graphics units. Each SM has 4 texture units, which have changes somewhat from the GT200. In GT200, the texture units were at the TPC level; here they are per SM. The texture units are also affected by the cache reorganization of GF100; for L1 cache they still have the same 12KB of texture cache per set of 4 texture units, while they all share GF100’s 768KB L2 cache, which is now used by all execution units and not just textures. Each unit can compute 1 texture address and fetch 4 texture samples per clock, a significantly higher texture fetch rate than on the GT200. Furthermore in conjunction with DX11, NVIDIA’s texture units now support DX11’s new compressed texture formats. Finally, texture units are now tied to the shader clock and not the core clock. They run at 1/2 the shader clock speed of GF100.
Last but not least, this brings us to the ROPs. The ROPs have been reorganized, there are now 48 of them in 6 parttions of 8, and a 64bit memory channel serving each partition. The ROPs now share the L2 cache with the rest of GF100, while under GT200 they had their own L2 cache. Each ROP can do 1 regular 32bit pixel per clock, 1 FP16 pixel over 2 clocks, or 1 FP32 pixel over 4 clocks, giving the GF100 the ability to retire 48 regular pixels per clock. The ROPs are clocked together with the L2 cache.
That leaves us on a final note: clocks. The core clock has been virtually done away with on GF100, as almost every unit now operates at or on a fraction of the shader clock. Only the ROPs and L2 cache operate on a different clock, which is best described as what’s left of the core clock. The shader clock now drives the majority of the chip, including the shaders, the texture units, and the new PolyMorph and Raster Engines. Specifically, the texture units, PolyMorph Engine, and Raster Engine all run at 1/2 shader clock (which NVIDIA is tentatively calling the "GPC Clock"), while the L1 cache and the shaders themselves run at the full shader clock. Don’t be surprised if GF100 overclocking is different from GT200 overclocking as a result.








115 Comments
View All Comments
Ryan Smith - Wednesday, January 20, 2010 - link
From my perspective, unless they can deliver better than 5870 performance at a reasonable price, then their image quality improvements aren't going to be enough to seal the deal. If they can meet those two factors however, then yes, image quality needs to be factored in to some degree.At this point I'm not sure where that would be, and part of that is diminishing returns. Tessellation will return better models, but adding polygons will result in diminishing returns. We're going to have to see what games do in order to see if the extra geometry that GF100 is supposed to be able to generate can really result in a noticeable difference.
Will game makers take advantage of it? That's the million-dollar question right now. NVIDIA is counting on them doing so, but it remains to be seen just how many devs are going to make meaningful use of tessellation (beyond just n-patching things for better curves), since DX11 game development is so young.
Consoles certainly have a lot to do with it. One very real possibility is that the bulk of games continue to be at the DX9 level until the next generation of consoles hits with DX11-like GPUs. I'll answer the rest of this in your next question.
The good news is that it takes very little work. Game assets are almost always designed at a much greater level of detail than what they ship at. The textbook example is Doom3, where the models were designed on the order of 1mil polygons; they needed to be designed that detailed in order to compute proper bump maps and parallax maps. Tessellation and the displacement map is just one more derived map in that regard - for the most part you only need to export an appropriate displacement map from your original assets, and NV is counting on this.
The only downsides to NV's plan are that: 1) Not everything is done at this high of a detail level (models are usually highly detailed, the world geometry not so much), and 2) Higher quality displacement maps aren't "free". Since a game will have multiple displacement maps (you have to MIP-chain them just like you do any other kind of map), a dev is basically looking at needing to include at least 1 more level that's even bigger than the others. Conceivably, not everyone is going to have extra disc space to spend on such assets. Although most games currently still have space to spare on a DVD-9, so I can't quantify how much of a problem that might be.
FITCamaro - Monday, January 18, 2010 - link
It will be fast. But from the size of it, its going to be expensive as hell.I question how much success nvidia will have with yet another fast but hot and expensive card. Especially with the entire world in recession.
beginner99 - Monday, January 18, 2010 - link
Sounds nice but I doubt it's useful yet. DX11, probably takes at least 1-2 year till it takes off and the geometry power could be useful. Meaning could have easly waited a generation longer.Power consumption will probably be deciding. The new Radeons do rather well in that area.
But anyway, i'm gonna wait. unless it is complete crap, it will at least help for Radeon prices going south, even if you don't buy one.
just4U - Monday, January 18, 2010 - link
On Amd pricing. It seems pretty fair for the 57XX line. Cheaper overall then the 4850 and 4870 on their launches with similiar performance and added DX11 features.It would be nice to see the 5850 and 5870 priced about one third cheaper.. but here in Canada the cards are always sold out or of very limited stock so... I guess there is some justification for the higher pricing.
I still can't get a 275 cheap either. It's priced 30-40% higher then the 4870.
The only card(s) I've purchased so far are the 5750s as I feel the last gen products are still viable at their current pricing ... and I buy a fair amount of video cards (20-100 per year)
solgae1784 - Monday, January 18, 2010 - link
Let's just hope this GF100 doesn't become another disaster that was "Geforce FX".setzer - Monday, January 18, 2010 - link
While on paper these specs look great for the High-End market (>500€ cards) how much will the mainstream market lose, as in the cards that sell around the 150~300€ bracket, which coincidently are the cards the most people tend to buy. Nvidia tends to scale down the specifications but how much will it be scaled down, what is the interest of the new IQ improvements if you can only use them on high-end cards because the mainstream cards can't handle it.The 5 series radeons are similar, the new generation only has appeal if you go for the 58xx++ cards, which are overpriced, if you already have a 4850 you can hold out from buying a new card for at least one extra year, take the 5670, it has dx11 support but hasn't the horse power to use it effectively neutering the card from start as far as dx11 goes.
So even if Nvidia goes with a March launch of GF100, I'm guessing it will not be until June or July that we see the GeForce 10600GT (like or GX600GT, phun on ATI 10000 series :P), which will just have the effect of Radeon prices to stay where they are (high) and not where they should be in terms of performance (slightly on par with the HD 4000 series).
Beno - Monday, January 18, 2010 - link
page 2 isnt workingZool - Monday, January 18, 2010 - link
It will be interesting how much of the geometry performance will be true in the end from all these hype. I wouldnt put my hand into fire on nvidias pr slides and in house demos. Like the pr graph with 600% teselation performance increase over ati card. It will surely have some dark sides too like everything around. Nothing is free. Until real benchmarks u cant trust too much to pr graphs these days.haplo602 - Monday, January 18, 2010 - link
This looks similar to what Riva TNT used to be. Nvidia was promising everything including a cure for cancer. It turned out to be barely better than 3Dfx at that time because of clock/power/heat problems.Seems Fermi will be a big bang in workstation/HPC markets. Gaming not so much.
DominionSeraph - Monday, January 18, 2010 - link
Anyone with at least half a brain had a TNT. Tech noobs saw "Voodoo" and went with the gimped Banshee, and those with money to burn threw in dual Voodoo 2's.How does this at all compare to Fermi, whose performance will almost certainly not justify its price. The 5870's doesn't, not with the 5850 in town. Such is the nature of the bleeding edge.
Do you just type things out at random?