NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Architecting Fermi: More Than 2x GT200
NVIDIA keeps referring to Fermi as a brand new architecture, while calling GT200 (and RV870) bigger versions of their predecessors with a few added features. Marginalizing the efforts required to build any multi-billion transistor chip is just silly, to an extent all of these GPUs have been significantly redesigned.
At a high level, Fermi doesn't look much different than a bigger GT200. NVIDIA is committed to its scalar architecture for the foreseeable future. In fact, its one op per clock per core philosophy comes from a basic desire to execute single threaded programs as quickly as possible. Remember, these are compute and graphics chips. NVIDIA sees no benefit in building a 16-wide or 5-wide core as the basis of its architectures, although we may see a bit more flexibility at the core level in the future.
Despite the similarities, large parts of the architecture have evolved. The redesign happened at low as the core level. NVIDIA used to call these SPs (Streaming Processors), now they call them CUDA Cores, I’m going to call them cores.
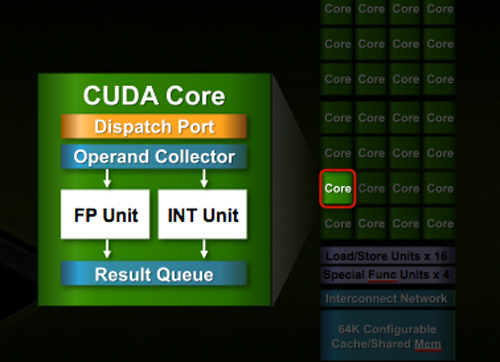
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect.
Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5). Wow.
NVIDIA isn’t disclosing clock speeds yet, so we don’t know exactly what that rate is yet.
In G80 and GT200 NVIDIA grouped eight cores into what it called an SM. With Fermi, you get 32 cores per SM.
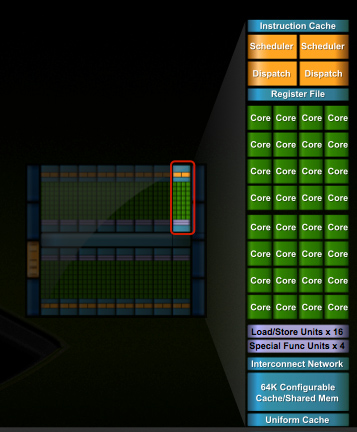
The high end single-GPU Fermi configuration will have 16 SMs. That’s fewer SMs than GT200, but more cores. 512 to be exact. Fermi has more than twice the core count of the GeForce GTX 285.
| Fermi | GT200 | G80 | |
| Cores | 512 | 240 | 128 |
| Memory Interface | 384-bit GDDR5 | 512-bit GDDR3 | 384-bit GDDR3 |
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in Fermi it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled.
The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.
NVIDIA organizes these SMs into TPCs, but the exact hierarchy isn’t being disclosed today. With the launch's Tesla focus we also don't know specific on ROPs, texture filtering or anything else related to 3D graphics. Boo.
A Real Cache Hierarchy
Each SM in GT200 had 16KB of shared memory that could be used by all of the cores. This wasn’t a cache, but rather software managed memory. The application would have to knowingly move data in and out of it. The benefit here is predictability, you always know if something is in shared memory because you put it there. The downside is it doesn’t work so well if the application isn’t very predictable.
Branch heavy applications and many of the general purpose compute applications that NVIDIA is going after need a real cache. So with Fermi at 40nm, NVIDIA gave them a real cache.
Attached to each SM is 64KB of configurable memory. It can be partitioned as 16KB/48KB or 48KB/16KB; one partition is shared memory, the other partition is an L1 cache. The 16KB minimum partition means that applications written for GT200 that require 16KB of shared memory will still work just fine on Fermi. If your app prefers shared memory, it gets 3x the space in Fermi. If your application could really benefit from a cache, Fermi now delivers that as well. GT200 did have an L1 texture cache (one per TPC), but the cache was mostly useless when the GPU ran in compute mode.

The entire chip shares a 768KB L2 cache. The result is a reduced penalty for doing an atomic memory op, Fermi is 5 - 20x faster here than GT200.








415 Comments
View All Comments
AlexWade - Wednesday, September 30, 2009 - link
How long have you been working for NVidia?taltamir - Thursday, October 1, 2009 - link
don't insult nvidia by insinuating that this zealot is their employeedzoni2k2 - Wednesday, September 30, 2009 - link
What the heck is wrong with you SiliconDoc?Since when is memory bandwidth main indicator of performance?!
For all I care Fermis memory bandwidth can be 999GB/s but what good is that if it's not used?
SiliconDoc - Friday, October 2, 2009 - link
I'm sure "it won't be used" because for the very first time "nvidia will make sure it "won't be used" becuase "they designed it that way ! " LOL--
You people are absolutely PATHETIC.
Now the greater Nvidia bandwith doesn't matter, because you don't care if it's 999, because... nvidia failed on design, and "it won't be used!"
ROFLMAO
Honestly, if you people heard yourselves...
I am really disappointed that the bias here is so much worse than even I had known, not to mention the utter lack of intellect so often displayed.
What a shame.
PorscheRacer - Wednesday, September 30, 2009 - link
Exactly! R600 had huge bandwidth but couldn't effectively use it; for the msot part. Is this huge bandwdth the GF300 has only able to be used in cGPU, or is it able to be used in games, too? We won't know till the card is actually reviewed a long while from now.SiliconDoc - Wednesday, September 30, 2009 - link
What a joke. The current GT200 responds in all flavors quite well to memory clock / hence bandwith increases.You know that, you have been around long enough.
It's great seeing the reds scream it doesn't matter when ati loses a category. (no actually it isn't great, it's quite sickening)
SiliconDoc - Wednesday, September 30, 2009 - link
Yes of course bandwith does not really matter when ati loses, got it red rooster. When nvidia is SO FAR AHEAD in it, it's better to say "it's not double"...LOL---
WHAT IS WRONG WITH YOU PEOPLE AND THE AUTHOR IS THE REAL QUESTION!
--
What is wrong with you ? Why don't you want to know when it's nvidia, when it's nvidia a direct comparison to ati's card is FORBIDDEN !
That's what the author did !
It was " a very adept DECEPTION" !
---
Just pointing out how you get snowballed and haven't a clue.
Rumors also speculated 4,000 data rate ddr5
4000x384/8 - 192 bandwith, still planty more than 153 ati.
CLEARLY though "not double 141" (nvidia's former number also conveniently NOT MEWNTIONED being so close to 153/5870 is EMBARRASSING) - is 282...
--
So anand knows it's 240, not quite double 141, short of 282.
DigitalFreak - Wednesday, September 30, 2009 - link
Looks like SnakeOil has another alias!therealnickdanger - Wednesday, September 30, 2009 - link
Agreed. That was refreshing!mapesdhs - Wednesday, September 30, 2009 - link
Blimey, I didn't know Ujesh could utter such things. :D When I knew
him in 1998 he was much more offical/polite-sounding (he was Product
Manager for the O2 workstation at SGI; I was using a loaner O2 from
SGI to hunt for OS/app bugs - Ujesh was my main contact for feedback).
The poster who talked about availability has a strong point. My brother
has asked me to build him a new system next week. Looks like it'll be
an Athlon II X4 620, 4GB RAM, 5850, better CPU cooler, with either an
AM3 mbd and DDR3 RAM or AM2+ mbd and DDR2 RAM (not sure yet). By heck
he's going to see one hell of a speed boost; his current system is a
single-core Athlon64 2.64GHz, 2GB DDR400, X1950Pro AGP 8X. :D My own
6000+ 8800GT will seem slow by comparison... :|
Ian.