NVIDIA's Fermi: Architected for Tesla, 3 Billion Transistors in 2010
by Anand Lal Shimpi on September 30, 2009 12:00 AM EST- Posted in
- GPUs
Architecting Fermi: More Than 2x GT200
NVIDIA keeps referring to Fermi as a brand new architecture, while calling GT200 (and RV870) bigger versions of their predecessors with a few added features. Marginalizing the efforts required to build any multi-billion transistor chip is just silly, to an extent all of these GPUs have been significantly redesigned.
At a high level, Fermi doesn't look much different than a bigger GT200. NVIDIA is committed to its scalar architecture for the foreseeable future. In fact, its one op per clock per core philosophy comes from a basic desire to execute single threaded programs as quickly as possible. Remember, these are compute and graphics chips. NVIDIA sees no benefit in building a 16-wide or 5-wide core as the basis of its architectures, although we may see a bit more flexibility at the core level in the future.
Despite the similarities, large parts of the architecture have evolved. The redesign happened at low as the core level. NVIDIA used to call these SPs (Streaming Processors), now they call them CUDA Cores, I’m going to call them cores.
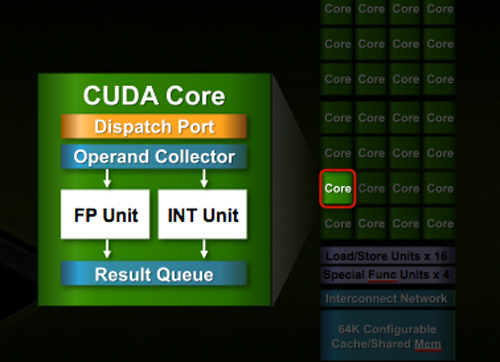
All of the processing done at the core level is now to IEEE spec. That’s IEEE-754 2008 for floating point math (same as RV870/5870) and full 32-bit for integers. In the past 32-bit integer multiplies had to be emulated, the hardware could only do 24-bit integer muls. That silliness is now gone. Fused Multiply Add is also included. The goal was to avoid doing any cheesy tricks to implement math. Everything should be industry standards compliant and give you the results that you’d expect.
Double precision floating point (FP64) performance is improved tremendously. Peak 64-bit FP execution rate is now 1/2 of 32-bit FP, it used to be 1/8 (AMD's is 1/5). Wow.
NVIDIA isn’t disclosing clock speeds yet, so we don’t know exactly what that rate is yet.
In G80 and GT200 NVIDIA grouped eight cores into what it called an SM. With Fermi, you get 32 cores per SM.
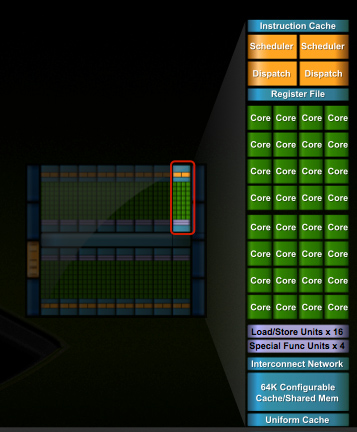
The high end single-GPU Fermi configuration will have 16 SMs. That’s fewer SMs than GT200, but more cores. 512 to be exact. Fermi has more than twice the core count of the GeForce GTX 285.
| Fermi | GT200 | G80 | |
| Cores | 512 | 240 | 128 |
| Memory Interface | 384-bit GDDR5 | 512-bit GDDR3 | 384-bit GDDR3 |
In addition to the cores, each SM has a Special Function Unit (SFU) used for transcendental math and interpolation. In GT200 this SFU had two pipelines, in Fermi it has four. While NVIDIA increased general math horsepower by 4x per SM, SFU resources only doubled.
The infamous missing MUL has been pulled out of the SFU, we shouldn’t have to quote peak single and dual-issue arithmetic rates any longer for NVIDIA GPUs.
NVIDIA organizes these SMs into TPCs, but the exact hierarchy isn’t being disclosed today. With the launch's Tesla focus we also don't know specific on ROPs, texture filtering or anything else related to 3D graphics. Boo.
A Real Cache Hierarchy
Each SM in GT200 had 16KB of shared memory that could be used by all of the cores. This wasn’t a cache, but rather software managed memory. The application would have to knowingly move data in and out of it. The benefit here is predictability, you always know if something is in shared memory because you put it there. The downside is it doesn’t work so well if the application isn’t very predictable.
Branch heavy applications and many of the general purpose compute applications that NVIDIA is going after need a real cache. So with Fermi at 40nm, NVIDIA gave them a real cache.
Attached to each SM is 64KB of configurable memory. It can be partitioned as 16KB/48KB or 48KB/16KB; one partition is shared memory, the other partition is an L1 cache. The 16KB minimum partition means that applications written for GT200 that require 16KB of shared memory will still work just fine on Fermi. If your app prefers shared memory, it gets 3x the space in Fermi. If your application could really benefit from a cache, Fermi now delivers that as well. GT200 did have an L1 texture cache (one per TPC), but the cache was mostly useless when the GPU ran in compute mode.

The entire chip shares a 768KB L2 cache. The result is a reduced penalty for doing an atomic memory op, Fermi is 5 - 20x faster here than GT200.








415 Comments
View All Comments
PorscheRacer - Thursday, October 1, 2009 - link
I have no clue what the red rooster thing implies, and I never understood why people called nVIDIA the green goblin. Until now. You, sir, have made it clear to me. They are called the green goblin, because that's where the trolls come from. Like wow. Your partisan and righteous thinking has no merit, no basis except conjecture and criticism. Save a keyboard, chill out and let's see if you can post anything in here without using the words, nVIDIA, ATI, red rooster, green goblin, and anything with ALL CAPS.It's fine to be passionate about something. But to exessive extents that push everyone else away and leave people ashamed, discouraged and embarrased; that's not how to win hearts and minds. I can already see you getting riled up over this post telling you to chill out....
SiliconDoc - Friday, October 2, 2009 - link
Hmmmm, that's very interesting. First you go into a pretend place where you assume green goblin is something "they call" nVIDIA, but just earlier, you'd never seen it in print before in your life.Along with that little fib problem, you make the rest of the paragraph a whining attack. One might think you need to settle down and take your own medicine.
And speaking of advice, your next paragraph talks about what you did in your first that you claim noone should, so I guess you're exempt in your own mind.
kirillian - Thursday, October 1, 2009 - link
Yall...seriously...leave the poor NVidia Fanboy alone. His head is probably throbbing with the fact that he found his first website (other than HardOCP) that isn't extremely NVidia biased.SiliconDoc - Friday, October 2, 2009 - link
Gee, I find that interesting that you know all about bias at other websites...So that says what again about here ?
silverblue - Thursday, October 1, 2009 - link
The 5870 is but one single GPU. The 295 is two and costs more. The 4870X2/CF is also a case of two GPUs. A 5870X2 would annihilate everything out there right now, and guess what? 5870 CF does just that. If money is no object, that would be the current option, or 5850s in CF to cut down on power usage and a fair amount of the cost without substantially decreasing performance.By stating "if someone wants to get their next-gen performance now", of course he's going to point in the direction of ATI as they are the only people with a DX11 part, and they currently hold the single GPU speed crown. This will not be the case in a few months, but for now, they do.
SiliconDoc - Friday, October 2, 2009 - link
I kinda doubt the 5870x2 blows away GTX295 quad, don't you ?--
Now you want to whine cost, too, but then excuse it for the 5870CF. LOL.
Another big fat riotous red rooster.
Really, you people love lies, and what's bad when it's nvidia, is good when it's ati, you just exactly said it !
ROFLMAO
--
Should I go get a 295 quad setup review and show you ?
--
How come you were wrong, whined I should settle down, then came back blowing lies again ?
There's no DX11 ready to speak of, so that's another pale and feckless attempt at the face save, after your excited, out of control, whipped up incorrect initial post, and this follow up fibber.
You need to settle down. "I want you banned"
Finally, you try to pretend you're not full of it, with your spewing caveat of prediction, "this will not be the case in a few months" - LOL
It's NOT the case NOW, but in a few months, it sure looks like it might BE THE CASE NO MATTER WHAT, unless of course ati launches the 5870x2 along with nvidia's SC GT300, which for all I know could happen.
So, even in that, you are NOT correct to any certainty, are you...
LOL
Calm down, and think FIRST, then start on your rampage without lying.
silverblue - Friday, October 2, 2009 - link
My GOD... you're a retard of the highest order.Why would I want to compare a dual GPU setup with an 8 GPU setup? What numpty would do that when it would logically be far faster? Even a quad 5870 setup wouldn't beat a quad 295 setup, and you know what? WE KNOW! 8 cores versus 4 is no contest. Core for core, RV870 is noticeably faster than the GT200 series, but you're the only person attempting to compare a single GPU card to a dual GPU card and saying the single GPU card sucks because it doesn't win.
And where did I say "I want you banned"? As someone once said, "lay off the crack".
SiliconDoc - Friday, October 2, 2009 - link
Aren't you the one who claimed only ati for the next gen performance ?Well, you really blew it, and no face save is possible. A single NVIDIA card beats the best single ati card. PERIOD.
It's true right now, and may or may not change within two months.
PERIOD.
silverblue - Friday, October 2, 2009 - link
No, I said that ATI currently has the single GPU crown. Not card - GPU. In a couple of months, ATI may have the 5870X2 out, and that WILL send the 295 the way of the dodo if it's priced correctly.No face saving necessary on my part.
Zaitsev - Wednesday, September 30, 2009 - link
^^LOL. I don't see what all the bickering is about. If you're willing to wait a few more months, then you can buy a faster card. If you want to buy now, there are also some nice options available. Currently there are 5 brands of 5870's and 1 5850 at the egg.