AMD's Radeon HD 5870: Bringing About the Next Generation Of GPUs
by Ryan Smith on September 23, 2009 9:00 AM EST- Posted in
- GPUs
DirectCompute, OpenCL, and the Future of CAL
As a journalist, GPGPU stuff is one of the more frustrating things to cover. The concept is great, but the execution makes it difficult to accurately cover, exacerbated by the fact that until now AMD and NVIDIA each had separate APIs. OpenCL and DirectCompute will unify things, but software will be slow to arrive.
As it stands, neither AMD nor NVIDIA have a complete OpenCL implementation that's shipping to end-users for Windows or Linux. NVIDIA has OpenCL working on the 8-series and later on Mac OS X Snow Leopard, and AMD has it working under the same OS for the 4800 series, but for obvious reasons we can’t test a 5870 in a Mac. As such it won’t be until later this year that we see either side get OpenCL up and running under Windows. Both NVIDIA and AMD have development versions that they're letting developers play with, and both have submitted implementations to Khronos, so hopefully we’ll have something soon.
It’s also worth noting that OpenCL is based around DirectX 10 hardware, so even after someone finally ships an implementation we’re likely to see a new version in short order. AMD is already talking about OpenCL 1.1, which would add support for the hardware features that they have from DirectX 11, such as append/consume buffers and atomic operations.
DirectCompute is in comparatively better shape. NVIDIA already supports it on their DX10 hardware, and the beta drivers we’re using for the 5870 support it on the 5000 series. The missing link at this point is AMD’s DX10 hardware; even the beta drivers we’re using don’t support it on the 2000, 3000, or 4000 series. From what we hear the final Catalyst 9.10 drivers will deliver this feature.
Going forward, one specific issue for DirectCompute development will be that there are three levels of DirectCompute, derived from DX10 (4.0), DX10.1 (4.1), and DX11 (5.0) hardware. The higher the version the more advanced the features, with DirectCompute 5.0 in particular being a big jump as it’s the first hardware generation designed with DirectCompute in mind. Among other notable differences, it’s the first version to offer double precision floating point support and atomic operations.
AMD is convinced that developers should and will target DirectCompute 5.0 due to its feature set, but we’re not sold on the idea. To say that there’s a “lot” of DX10 hardware out there is a gross understatement, and all of that hardware is capable of supporting at a minimum DirectCompute 4.0. Certainly DirectCompute 5.0 is the better API to use, but the first developers testing the waters may end up starting with DirectCompute 4.0. Releasing something written in DirectCompute 5.0 right now won’t do developers much good at the moment due to the low quantity of hardware out there that can support it.
With that in mind, there’s not much of a software situation to speak about when it comes to DirectCompute right now. Cyberlink demoed a version of PowerDirector using DirectCompute for rendering effects, but it’s the same story as most DX11 games: later this year. For AMD there isn’t as much of an incentive to push non-game software as fast or as hard as DX11 games, so we’re expecting any non-game software utilizing DirectCompute to be slow to materialize.
Given that DirectCompute is the only common GPGPU API that is currently working on both vendors’ cards, we wanted to try to use it as the basis of a proper GPGPU comparison. We did get something that would accomplish the task, unfortunately it was an NVIDIA tech demo. We have decided to run it anyhow as it’s quite literally the only thing we have right now that uses DirectCompute, but please take an appropriately sized quantity of salt – it’s not really a fair test.
NVIDIA’s ocean demo is a fairly simple proof of concept program that uses DirectCompute to run Fast Fourier transforms directly on the GPU for better performance. The FFTs in turn are used to generate the wave data, forming the wave action seen on screen as part of the ocean. This is a DirectCompute 4.0 program, as it’s intended to run on NVIDIA’s DX10 hardware.
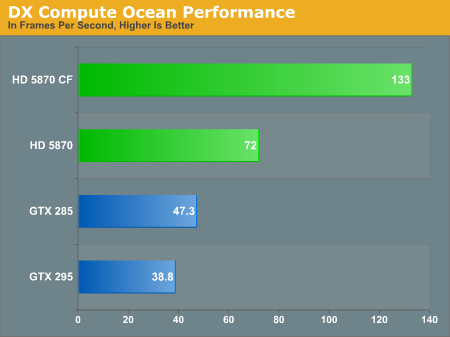
The 5870 has no problem running the program, and in spite of whatever home field advantage that may exist for NVIDIA it easily outperforms the GTX 285. Things get a little more crazy once we start using SLI/Crossfire; the 5870 picks up speed, but the GTX 295 ends up being slower than the GTX 285. As it’s only a tech demo this shouldn’t be dwelt on too much beyond the fact that it’s proof that DirectCompute is indeed working on the 5800 series.
Wrapping things up, one of the last GPGPU projects AMD presented at their press event was a GPU implementation of Bullet Physics, an open source physics simulation library. Although they’ll never admit it, AMD is probably getting tired of being beaten over the head by NVIDIA and PhysX; Bullet Physics is AMD’s proof that they can do physics too. However we don’t expect it to go anywhere given its very low penetration in existing games and the amount of trouble NVIDIA has had in getting developers to use anything besides Havok. Our expectations for GPGPU physics remains the same: the unification will come from a middleware vendor selling a commercial physics package. If it’s not Havok, then it will be someone else.
Finally, while AMD is hitting the ground running for OpenCL and DirectCompute, their older APIs are being left behind as AMD has chosen to focus all future efforts on OpenCL and DirectCompute. Brook+, AMD’s high level language, has been put out to pasture as a Sourceforge project. Compute Abstract Layer (CAL) lives on since it’s what AMD’s OpenCL support is built upon, however it’s not going to see any further public development with the interface frozen at the current 1.4 standard. AMD is discouraging any CAL development in favor of OpenCL, although it’s likely the High Performance Computing (HPC) crowd will continue to use it in conjunction with AMD’s FireStream cards to squeeze every bit of performance out of AMD’s hardware.








327 Comments
View All Comments
mapesdhs - Saturday, September 26, 2009 - link
MODel3 writes:
> 1.Geometry/vertex performance issues ...
> 2.Geometry/vertex shading performance issues ...
Would perhaps some of the subtests in 3DMark06 be able to test this?
(not sure about Vantage, never used that yet) Though given what Jarred
said about the bandwidth and other differences, I suppose it's possible
to observe large differences in synthetic tests which are not the real
cause of a performance disparity.
The trouble with heavy GE tests is, they often end up loading the fill
rates anyway. I've run into this problem with the SGI tests I've done
over the years:
http://www.sgidepot.co.uk/sgi.html">http://www.sgidepot.co.uk/sgi.html
The larger landscape models used in the Inventor tests are a good
example. The points models worked better in this regard for testing
GE speed (stars3/star4), but I don't know to what extent modern PC
gfx is designed to handle points modelling - probably works better
on pro cards. Actually, Inventor wasn't a good choice anyway as it's
badly CPU-bound and API-heavy (I should have used Performer, gives
results 5 to 10X faster).
Anyway, point is, synthetic tests might allow one to infer that one
aspect of the gfx pipeline is a bottleneck when infact it isn't.
Ages ago I emailed NVIDIA (Ujesh, who I used to know many moons ago,
but alas he didn't reply) asking when, if ever, they would add
performance counters and other feedback monitors to their gfx
products so that applications could tell what was going on in the
gfx pipeline. SGI did this ages years ago, which allowed systems like
IR to support impressive functions such as Dynamic Video Resizing by
being able to monitor frame by frame what was going on within the gfx
engine at each stage. Try loading any 3D model into perfly, press F1
and click on 'Gfx' in the panel (Linux systems can run Performer), eg.:
http://www.sgidepot.co.uk/misc/perfly.gif">http://www.sgidepot.co.uk/misc/perfly.gif
Given how complex modern PC gfx has become, it's always been a
mystery to me why such functions haven't been included long ago.
Indeed, for all that Crysis looks amazing, I was never that keen on
it being used as a benchmark since there was no way of knowing
whether the performance hammering it created was due to a genuinely
complex environment or just an inefficient gfx engine. There's still
no way to be sure.
If we knew what was happening inside the gfx system, we could easily
work out why performance differences for different apps/games crop
up the way they do. And I would have thought that feedback monitors
within the gfx pipe would be even more useful to those using
professional applications, just as it was for coders working on SGI
hardware in years past.
Come to think of it, how do NVIDIA/ATI even design these things
without being able to monitor what's going on? Jarred, have you ever
asked either company about this?
Ian.
JarredWalton - Saturday, September 26, 2009 - link
I haven't personally, since I'm not really the GPU reviewer here. I'd assume most of their design comes from modeling what's happening, and with knowledge of their architecture they probably have utilities that help them debug stuff and figure out where stalls and bottlenecks are occurring. Or maybe they don't? I figure we don't really have this sort of detail for CPUs either, because we have tools that know the pipeline and architecture and they can model how the software performs without any hardware feedback.MODEL3 - Thursday, October 1, 2009 - link
I checked the web for synthetic geometry tests.Sadly i only found 3dMark Vantage tests.
You can't tell much from them, but they are indicative.
Check:
http://www.pcper.com/article.php?aid=783&type=...">http://www.pcper.com/article.php?aid=783&type=...
GPU Cloth: 5870 is only 1,2X faster than 4890. (vertex/geometry shading test)
GPU Particles: 5870 is only 1,2X faster than 4890. (vertex/geometry shading test)
Perlin Noise: 5870 is 2,5X faster than 4890. (Math-heavy Pixel Shader test)
Parallax Occlusion Mapping: 5870 is 2,1X faster than 4890. (Complex Pixel Shader test)
All the above 4 tests are not bandwidth limited at all.
Just for example, if you check:
http://www.pcper.com/article.php?aid=674&type=...">http://www.pcper.com/article.php?aid=674&type=...
You will see that a 750MHz 4870 512MB is 20-23% faster than a 625MHz 4850 in all the above 4 tests, so the extra bandwidth (115,2GB/s vs 64GB/s) it doesn't help at all.
But 4850 is extremely bandwidth limited in the color fillrate test (4870 is 60% faster than 4850)
Also it shouldn't be a problem of the dual rasterizer/dual SIMDs engine efficiency since synthetic Pixel Shader tests is fine (more than 2X) while the synthetic geometry shading tests is only 1,2X.
My guess is ATI didn't improve the classic geometry set-up engine and the GS because they want to promote vertex/geometry techniques based on the DX11 tesselator from now on.
Zool - Friday, September 25, 2009 - link
In Dx11 the fixed tesselation units will do much finer geometry details for much less memmory space and on chip so i think there isnt a single problem with that. Also the compute shader need minimal memory bandwith and can utilize plenty of idle shaders. The card is designed with dx11 in mind and it isnt using the wholle pipeline after all. I wouldnt make too early conclusions.(I think the perfomance will be much better after few drivers)MODEL3 - Saturday, September 26, 2009 - link
The DX11 tesselator in order to be utilized must the game engine to take advantage of it.I am not talking about the tesselator.
I am talking about the classic Geometry unit (DX9/DX10 engines) and the Geometry Shader [GS] (DX10 engines only).
I'll check to see if i can find a tech site that has synthetic bench for Geometry related perf. and i will post again tomorrow, if i can find anything.
JarredWalton - Friday, September 25, 2009 - link
It's worth noting that when you factor in clock speeds, compared to the 5870 the 4870X2 offers 88% of the core performance and 50% more bandwidth. Some algorithms/games require more bandwidth and others need more core performance, but it's usually a combination of the two. The X2 also has CrossFire inefficiencies to deal with.More interesting perhaps is that the GTX 295 offers (by my estimates, which admittedly are off in some areas) roughly 10% more GPU shader performance, about 18.5% more fill rate, and 46% more bandwidth than the HD 5870. The fact that the HD 4870 is still competitive is a good sign that ATI is getting good use of their 5 SPs per Stream Processor design, and that they are not memory bandwidth limited -- at least not entirely.
SiliconDoc - Wednesday, September 30, 2009 - link
The 4870x2 has somewhere around "double the data paths" in and out of it's 2 cpu's. So what you have with the 5870 putting as some have characterized " 2x 770 cores melded into one " is DOUBLE THE BOTTLENECK in and out of the core.They tried to compensate with ddr5 1200/4800 - but the fact remains, they only get so much with that "NOT ENOUGH DATA PATHS/PINS in and out of that gpu core."
cactusdog - Friday, September 25, 2009 - link
Omg these cards look great. Lol Silicon Doc is so gutted and furious he is making hmself look like a dam fool again only this time he should be on suicide watch...Nvidia cards are now obsolete..LOL.mapesdhs - Friday, September 25, 2009 - link
Hehe, indeed. Have you ever seen a scifi series called, "They Came
From Somewhere Else?" S.D.'s getting so worked up, reminds me of
the scene where the guy's head explodes. :D
Hmm, that's an alternative approach I suppose in place of post
moderation. Just get someone so worked up about something they'll
have an aneurism and pop their clogs... in which case, I'll hand
it back to Jarred. *grin*
Ian.
SiliconDoc - Friday, September 25, 2009 - link
That is quite all right, you fellas make sure to read it all, I am more than happy that the truth is sinking into your gourds, you won't be able to shake it.I am very happy about it.