AMD's Radeon HD 5870: Bringing About the Next Generation Of GPUs
by Ryan Smith on September 23, 2009 9:00 AM EST- Posted in
- GPUs
More GDDR5 Technologies: Memory Error Detection & Temperature Compensation
As we previously mentioned, for Cypress AMD’s memory controllers have implemented a greater part of the GDDR5 specification. Beyond gaining the ability to use GDDR5’s power saving abilities, AMD has also been working on implementing features to allow their cards to reach higher memory clock speeds. Chief among these is support for GDDR5’s error detection capabilities.
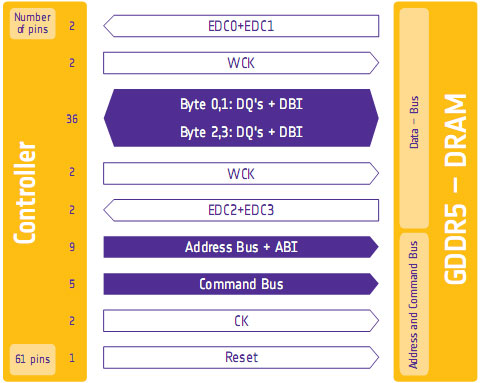
One of the biggest problems in using a high-speed memory device like GDDR5 is that it requires a bus that’s both fast and fairly wide - properties that generally run counter to each other in designing a device bus. A single GDDR5 memory chip on the 5870 needs to connect to a bus that’s 32 bits wide and runs at base speed of 1.2GHz, which requires a bus that can meeting exceedingly precise tolerances. Adding to the challenge is that for a card like the 5870 with a 256-bit total memory bus, eight of these buses will be required, leading to more noise from adjoining buses and less room to work in.
Because of the difficulty in building such a bus, the memory bus has become the weak point for video cards using GDDR5. The GPU’s memory controller can do more and the memory chips themselves can do more, but the bus can’t keep up.
To combat this, GDDR5 memory controllers can perform basic error detection on both reads and writes by implementing a CRC-8 hash function. With this feature enabled, for each 64-bit data burst an 8-bit cyclic redundancy check hash (CRC-8) is transmitted via a set of four dedicated EDC pins. This CRC is then used to check the contents of the data burst, to determine whether any errors were introduced into the data burst during transmission.
The specific CRC function used in GDDR5 can detect 1-bit and 2-bit errors with 100% accuracy, with that accuracy falling with additional erroneous bits. This is due to the fact that the CRC function used can generate collisions, which means that the CRC of an erroneous data burst could match the proper CRC in an unlikely situation. But as the odds decrease for additional errors, the vast majority of errors should be limited to 1-bit and 2-bit errors.
Should an error be found, the GDDR5 controller will request a retransmission of the faulty data burst, and it will keep doing this until the data burst finally goes through correctly. A retransmission request is also used to re-train the GDDR5 link (once again taking advantage of fast link re-training) to correct any potential link problems brought about by changing environmental conditions. Note that this does not involve changing the clock speed of the GDDR5 (i.e. it does not step down in speed); rather it’s merely reinitializing the link. If the errors are due the bus being outright unable to perfectly handle the requested clock speed, errors will continue to happen and be caught. Keep this in mind as it will be important when we get to overclocking.
Finally, we should also note that this error detection scheme is only for detecting bus errors. Errors in the GDDR5 memory modules or errors in the memory controller will not be detected, so it’s still possible to end up with bad data should either of those two devices malfunction. By the same token this is solely a detection scheme, so there are no error correction abilities. The only way to correct a transmission error is to keep trying until the bus gets it right.
Now in spite of the difficulties in building and operating such a high speed bus, error detection is not necessary for its operation. As AMD was quick to point out to us, cards still need to ship defect-free and not produce any errors. Or in other words, the error detection mechanism is a failsafe mechanism rather than a tool specifically to attain higher memory speeds. Memory supplier Qimonda’s own whitepaper on GDDR5 pitches error correction as a necessary precaution due to the increasing amount of code stored in graphics memory, where a failure can lead to a crash rather than just a bad pixel.
In any case, for normal use the ramifications of using GDDR5’s error detection capabilities should be non-existent. In practice, this is going to lead to more stable cards since memory bus errors have been eliminated, but we don’t know to what degree. The full use of the system to retransmit a data burst would itself be a catch-22 after all – it means an error has occurred when it shouldn’t have.
Like the changes to VRM monitoring, the significant ramifications of this will be felt with overclocking. Overclocking attempts that previously would push the bus too hard and lead to errors now will no longer do so, making higher overclocks possible. However this is a bit of an illusion as retransmissions reduce performance. The scenario laid out to us by AMD is that overclockers who have reached the limits of their card’s memory bus will now see the impact of this as a drop in performance due to retransmissions, rather than crashing or graphical corruption. This means assessing an overclock will require monitoring the performance of a card, along with continuing to look for traditional signs as those will still indicate problems in memory chips and the memory controller itself.
Ideally there would be a more absolute and expedient way to check for errors than looking at overall performance, but at this time AMD doesn’t have a way to deliver error notices. Maybe in the future they will?
Wrapping things up, we have previously discussed fast link re-training as a tool to allow AMD to clock down GDDR5 during idle periods, and as part of a failsafe method to be used with error detection. However it also serves as a tool to enable higher memory speeds through its use in temperature compensation.
Once again due to the high speeds of GDDR5, it’s more sensitive to memory chip temperatures than previous memory technologies were. Under normal circumstances this sensitivity would limit memory speeds, as temperature swings would change the performance of the memory chips enough to make it difficult to maintain a stable link with the memory controller. By monitoring the temperature of the chips and re-training the link when there are significant shifts in temperature, higher memory speeds are made possible by preventing link failures.
And while temperature compensation may not sound complex, that doesn’t mean it’s not important. As we have mentioned a few times now, the biggest bottleneck in memory performance is the bus. The memory chips can go faster; it’s the bus that can’t. So anything that can help maintain a link along these fragile buses becomes an important tool in achieving higher memory speeds.








327 Comments
View All Comments
pinguin - Monday, September 28, 2009 - link
It IS a hard launch as obviously a few cards are available. That consumers rip them off one's hand is another problem...Anyway I'll wait until the 5650: 4850 performance w/o PCIe connector + DX11: I'm coming! What else do I need to show off to my friends still staying with rebranded G92 chips!!
jabroni619 - Friday, September 25, 2009 - link
I guess it is, it was even better still when I decided to come home a bit early and UPS got there 2 hours sooner than they usually do. Playing through Crysis Warhead once more "The way it's meant to be played" on an ATI card though.Also included was a Dirt 2 code to be activated on steam, which I nearly threw out! Now I just have to wait for the game to be released.
camylarde - Thursday, September 24, 2009 - link
Lol. I was horrified, when i heard that my precious badminton racquet purchased on my friends address in england was "delivered" to the front door, waiting for him all day on the doorstep.if the card is gonna wait for you in a similar fashion, may i get to know where do you live to... erm... be there when you open the box and celebrate with you?
[/envy]
SiliconDoc - Wednesday, September 23, 2009 - link
I'm not certain how you saw any available then, looks from 3 different states didn't show that.Heck they weren't even active at 8 am, nor later than that. I guess you "got the only one" that wasn't Autonotify when arriving.
The0ne - Wednesday, September 23, 2009 - link
This is the last piece of hardware I've been waiting for before I build my i7 system. Now I think it's a ok time for enthusiast to start building again but on a cheaper budget with better performance :) no more of these 200-300 MB and stuff lolgwolfman - Wednesday, September 23, 2009 - link
I agree. Full bit-streaming support! Yeaz!blanarahul - Wednesday, December 21, 2011 - link
They should have given the option for 5870 to have triple DVI rather than single DVI + Dual DP. :(