Understanding the iPhone 3GS
by Anand Lal Shimpi on July 7, 2009 12:00 AM EST- Posted in
- Smartphones
- Mobile
A Crash Course in CPU Architecture
It’s been years since I’ve gone through the life of an instruction, and when I last did it it was about a very high end desktop processor. I realize that not everyone interested in what’s powering the iPhone 3GS or Palm Pre may have been taken down this path, so I thought some of that knowledge might be useful here.
Applications spawn threads, threads are made up of instructions and instructions are what a CPU “processes”. The actual processing of an instruction is pretty simple; the CPU must fetch the instruction from memory, decode or somehow understand what the instruction is telling it to do (e.g. add two numbers), grab any data that is required by the instruction (e.g. find the numbers to be added), actually execute the instruction and finally write the result of the operation either to a register or memory.
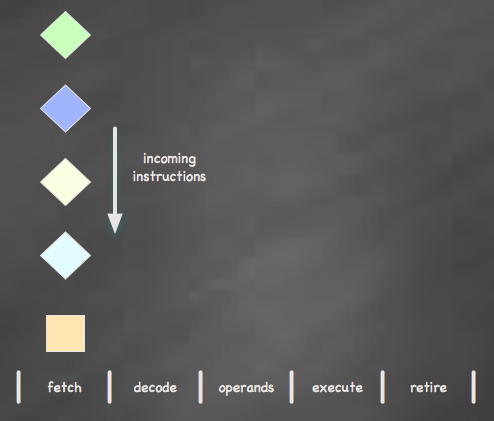
Our basic microprocessor with a 5-stage pipeline
Based on the example above, executing an instruction requires five distinct stages. In a pipelined microprocessor, a different instruction can be active at each stage of the execution pipeline. For example, you can be grabbing data for one instruction, while decoding another and fetching yet another. All modern day processors work this way.
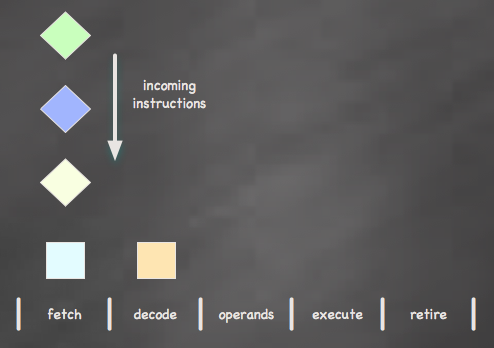
Multiple instructions can exist in the pipeline at once, but only one instruction may be active at any given stage
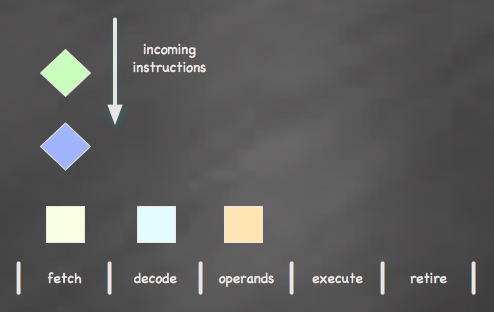
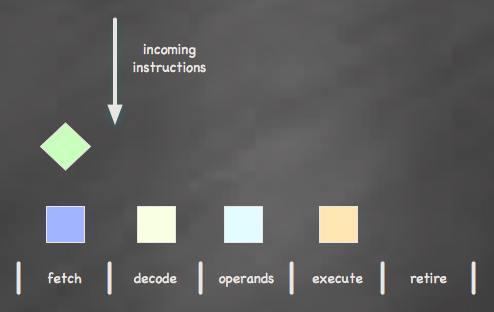


Each one of these stages should take the same amount of time for the processor to work efficiently; the length of time required at the longest stage actually determines the clock speed of the CPU. If the most complex stage in my example above is the decode stage and it requires 3ns to complete, then my CPU can run no faster than 333MHz (1 / 3ns).
To reach faster frequencies, we need to speed up each stage of the pipeline. You can speed up a stage by implementing some sweet new algorithms, or simply by splitting up complicated stages into simpler ones and increasing the number of stages in your pipeline.
In our previous example, the decode stage required 3ns to complete but if we split decode into three separate stages, each requiring 1ns, then we remove that bottleneck. Let’s say we do that but now some of our other stages become the bottleneck; with a target of a 1ns clock period (1ns spent per stage) we go from five stages to eight:
Fetch
Decode 1
Decode 2
Decode 3
Fetch Operands
Execute 1
Execute 2
Write Output
Now, with each stage running at 1ns, our maximum clock speed goes up from 333MHz to 1000MHz (1GHz). Sweet. Right?
With less work being done in each stage, we reach a higher clock speed, but we also depend on each stage being full in order to operate at peak efficiency.

5-stage pipeline (top) vs 8-stage pipeline (bottom). The 8 stage pipe is more desirable, but also requires more instructions to fill.
In the first CPU example we had a 5 stage pipeline, which meant that we needed to have the pipe full of 5 instructions at any given time to be operating at peak efficiency of 1 instruction completed every cycle. The second example has a ginormous 8 stage pipeline, which requires 8 instructions in the pipe for peak efficiency. In both cases you can only get one instruction out of the pipe every cycle, but the second chip can give us more completed instructions in say, 10 seconds.
Now think for a moment about the time periods we’re talking about here. The first CPU had a clock period of 3ns, where each stage took 3ns to complete. The second CPU had a clock period of 1ns. A single trip to main memory can easily take 60ns for a CPU with a very fast on-die memory controller, or over 100ns otherwise. For the sake of argument let’s say that we’re talking about a 100ns trip to main memory. Remember the Fetch Operands stage? Well if those operands are located in main memory that stage won’t take 3ns to complete, but rather 103ns since it has to get the operands from main memory.
Modern processors will perform a context switch upon any memory access to avoid stalling the pipeline for such an absurd length of time. The contents of the pipeline get flushed and filled with another thread while the data request goes off to main memory. Once the data is ready, the processor switches contexts once more and continues on its execution path. Here’s the problem: it takes time to refill the pipeline, and the longer the pipeline, the longer it takes to refill it. This is a bad, but regular occurrence in a microprocessor. Our instruction throughput drops from its 1 instruction per clock peak to 0; not good.
Other scenarios can create interruptions in the normal flow of things within our microprocessor. Some instructions may take multiple cycles at a single stage to complete. More complex arithmetic may spend significantly longer at the execute stage while the operation works out. With an in-order microprocessor, all instructions behind it must wait.
Again, the more stages in your pipeline, the bigger the penalty for a stall. But when the pipeline is full, a deeper pipeline will give us a higher clock speed and better overall performance - we just need to worry about keeping the pipeline full (which takes a great deal of additional transistors). And yes, there is an upper limit to how deep you can pipeline your processor before you start running into diminishing returns in both a performance and power sense, this was ultimately the downfall of the Pentium 4’s architecture.








60 Comments
View All Comments
iwodo - Thursday, July 9, 2009 - link
Would really love Anand digg deeper and give us some more info. The info i could find for Atom, has 47 Million transistors. Ars report 40% of it is cache, while others report the core is 13.7 million. The previous iPhone article Jarred Walton commented that x86 decoder no longer matters because 1.5 - 2 million transistors inside a billions transistor CPU is negligible. However in Mobile space, 2M inside a 13.7M is nearly 15%. Not to mention other transistor used that is needed for this decoding.The space required for Atom is 25mm2 on a 45NM ( Including All Cache) . Cortex A8 require 9mm2 ( dont know how many cache ) on 65nm.
What is interesting is how Intel manage to squeeze the north bridge inside the Atom CPU ( more transistors ) while making the Die Smaller. ( i dont know if Intel slides were referring to the total package size or the die size itself ).
snookie - Thursday, July 9, 2009 - link
The Pre hardware, as in case, screen, keyboard is terrible. Cheap, plasticky and breaking left and right on people. If Palm survives long enough to get to Verizon etc Here's hoping they come out with better hardware soon. I've used Blackberries for year but I see no need for a physical keyboard. With the new iPhone widescreen keyboard I type with both thumbs very quickly and I have big hands.snookie - Thursday, July 9, 2009 - link
Jason, Apple has in fact agreed to using mini-usb as a standard. As if that is really a reason to buy a phone or not.To say Apple never changes shows no knowledge of the history of Apple, even their recent history.
Itaintrite - Wednesday, July 8, 2009 - link
Heh, it's funny how you say that you can't just look at clock speed, then followed with "the 528MHz processor in the iPod Touch is no where near as fast as the 600MHz processor in the iPhone 3GS." Heh.Anonymous Freak - Wednesday, July 8, 2009 - link
I want my punch and pie!Or a lollipop.
Good review, I could feel your hunger pangs toward both Palm and Apple toward the end...
monomer - Wednesday, July 8, 2009 - link
Regarding Anand's comments about Android phones needing an upgraded CPU, rumors are that the upcoming Sony Xperia Rachael will be sporting a 1GHz Qualcomm Snapdragon processor (ARM Cortex A8 derivative). Would love to find out the details of this phone when they become available.http://www.engadget.com/2009/07/04/sony-ericsson-r...">http://www.engadget.com/2009/07/04/sony...chael-an...
Affectionate-Bed-980 - Thursday, July 9, 2009 - link
Well I'd like to see Anand's experience with Android phones. What is it, just G1? Look at the new Hero or even G2. What about the Samsung i7500? Sorry I'm afraid that the limited nature of cell phone selection in the US makes it VERY HARD to review cell phones well here. I haven't seen a good cell phone site that's by people in the US and from the US only. Phone Arena, Mobile Burn, Phonescoop, GSM Arena, It seems the international guys get a LOT more exposure, and this is why I feel like Anand's comments about phones in general makes him sound inexperienced which I can certainly bet is the case.If you limit yourself to only carrier offered phones, then I don't think you can make accurate assessments about manufacturers like Nokia or certain OS phones like WinMo or Symbian or even Android unless the US starts offering more of what the world considers top notch popular phones.
Affectionate-Bed-980 - Wednesday, July 8, 2009 - link
N97 specs should be 434 MHz ARM11 not 424...Affectionate-Bed-980 - Wednesday, July 8, 2009 - link
BTW I don't believe you should be commenting about the N97. Gizmodo is heavily biased towards iPhones and unless you yourself Anand uses some Symbian S60 phones with detail, I don't really think you should join in the S60 bashing. I think a lot of us Symbian users AGREE that the platform needs to improve, but considering we were like ZOMG434MHZFAIL, the N97 is not bad in response time if you look at a few videos. The UI exceeded a lot of expectations amongst the Symbian crowd. If anything why don't you throw the Samsung i8910 Omnia HD in there instead? That has a Cortex A8 and uses Symbian S60v5 (not to mention has been out longer than the N97). The other S60v5 phone to come out is the Sony Satio which also uses a Cortex A8.You might as well comment on why Cortex A8 isn't being implemented in all new phones. WinMo phones are still on ARM11, and even HTC's newest announcements are ARMv7 chips. The iPhone doesn't define what high end is. Because if you want to point out that its unacceptable to have a ARMv7 chip in an N97, then it's just as unacceptable for the iPhone not to have a 5MP camera and multitasking.
straubs - Wednesday, July 8, 2009 - link
1. It IS unacceptable for any flagship phone to use ARM11. The iPhone, Pre, and Omnia HD (as you pointed out) all use it, so why wouldn't Nokia put it in it's $700 N-series flagship? It doesn't make sense. I'm surprised he didn't mention the crappy screen on the N97.2. He did comment on how the iPhone needs multi-tasking and how much he missed the Pre's implementation of it.
3. Doesn't everyone at this point agree that the number of megapixels in a phone camera is not a huge deal, considering the size of the sensor and optics? I would guess the N97 pictures are better than those from the the 3GS, but nothing like the jump from an ARM11 or A8.