Real-world virtualization benchmarking: the best server CPUs compared
by Johan De Gelas on May 21, 2009 3:00 AM EST- Posted in
- IT Computing
Caches, Memory Bandwidth, or Pure Clock Speed?
We currently only have one Xeon 55xx in the lab, but we have four different CPUs based on the AMD "K10" architecture. That allows us to do some empirical testing to find out what makes the most impact: larger caches, faster memory, or mostly clock speed?
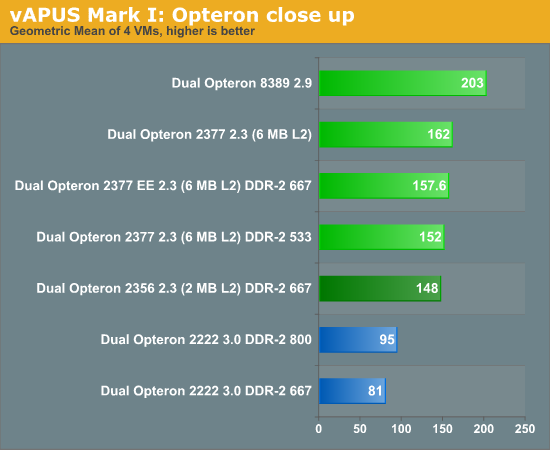
Every bit of extra clock speed seems to benefit our test. Bandwidth has a smaller effect. Even if we reduce the bandwidth of the Shanghai Opteron by one third, the score only lowers by 6%. Given that we only run four VMs this seems reasonable. Shanghai got three times as much L3 cache, a faster L3 cache, DDR2-800 instead of DDR2-667, and lower world switch times. The Opteron 2377 2.3GHz allows us to test at the same clock speed: the Shanghai Opteron is about 9.5% faster clock-for-clock than the Barcelona chip. If we run both chips with the same memory, the Shanghai Opteron is 6.5% faster. That's a small difference, but the Opteron EE promises much lower power consumption (40W ACP, 60W TDP) than the Barcelona chip (75W ACP, 115W TDP).
Notice that the Dual Opteron is a lot more bandwidth sensitive: improve bandwidth by 20% and you get 14% higher performance. Four VMs are fighting for only 4x1MB of cache, while running on the dual "Shanghai" Opteron each VM in theory has two 512KB L2 caches plus a 3MB chunk of L3.








66 Comments
View All Comments
GotDiesel - Thursday, May 21, 2009 - link
"Yes, this article is long overdue, but the Sizing Server Lab proudly presents the AnandTech readers with our newest virtualization benchmark, vApus Mark I, which uses real-world applications in a Windows Server Consolidation scenario."spoken with a mouth full of microsoft cock
where are the Linux reviews ?
not all of us VM with windows you know..
JohanAnandtech - Thursday, May 21, 2009 - link
A minimum form of politeness would be appreciated, but I am going to assume your were just dissapointed.The problem is that right now the calling circle benchmark runs half as fast on Linux as it does on Windows. What is causing Oracle to run slower on Linux than on Windows is a mystery even to some of the experienced DBA we have spoken. We either have to replace that benchmark with an alternative (probably Sysbench) or find out what exactly happened.
When you construct a virtualized benchmark it is not enough just to throw in a few benchmarks and VMs, you really have to understand the benchmark thoroughly. There are enough halfbaken benchmarks already on the internet that look like a Swiss cheese because there are so many holes in the methodology.
JarredWalton - Thursday, May 21, 2009 - link
Page 4: vApus Mark I: the choices we made"vApus mark I uses only Windows Guest OS VMs, but we are also preparing a mixed Linux and Windows scenario."
Building tests, verifying tests, running them on all the servers takes a lot of time. That's why the 2-tile and 3-tile results are not yet ready. I suppose Linux will have to wait for Mark II (or Mark I.1).
mino - Thursday, May 21, 2009 - link
What you did so far is great. No more words needed.What I would like to see is vApus Mark I "small" where you make the tiles smaller, about 1/3 to 1/4 of your current tiles.
Tile structure shall remain simmilar for simplicity, they will just be smaller.
When you manage to have 2 different tile sizes, you shall be able to consider 1 big + 1 small tile as one "condensed" tile for general score.
Having 2 reference points will allow for evaluating "VM size scaling" situations.
JohanAnandtech - Sunday, May 24, 2009 - link
Can you elaborate a bit? What do you menan by "1/3 of my current tile?" . A tile = 4 VMs. are you talking about small mem footprint or number of VCPUs?Are you saying we should test with a Tile with small VMs and then test afterwards with the large ones? How do you see such "VM scaling" evaluation?
mino - Monday, May 25, 2009 - link
Thanks for response.1/3 I mean smaller VM's. Mostly from the load POW. Probably 1/3 load would go for 1/2 memory footprint.
The point being that currently the is only a single datapont with a specific load-size per tile/per VM.
By "VM scaling" I would like to see what effect woul smaller loads have on overal performance.
I suggest 1/3 or 1/4 the load to get a measurable difference while remaining within reasonable memory/VM scale.
In the end, if you get simmilar overal performance from 1/4 tiles, it may not make sense to include this in future.
Even then the information that your benchmark results can be safely extrapolated to smaller loads would be of a great value by itself.
mino - Monday, May 25, 2009 - link
Eh, that last text of mime looks like a nice gibberish...Clarification nneded:
To be able to run more tiles/box smaller memory footprint is a must.
With smaller mem footprint, smaller DB's are a must.
The end results may not be directly comparable but shall be able to give some reference point, corectly interpreted
Please let me know if this makes sense to you.
There are multiple dimensions to this. I may be easily on the imaginery branch :)
ibb27 - Thursday, May 21, 2009 - link
Can we have a chance to see benchmarks for Sun Virtualbox which is Opensource?winterspan - Tuesday, May 26, 2009 - link
This test is misleading because you are not using the latest version of VMware that supports Intel's EPT. Since AMD's version of this is supported in the older version, the test is not at all a fair representation of their respective performance.Zstream - Thursday, May 21, 2009 - link
Can someone please perform a Win2008 RC2 Terminal Server benchmark? I have been looking everywhere and no one can provide that.If I can take this benchmark and tell my boss this is how the servers will perform in a TS environment please let me know.