SSD versus Enterprise SAS and SATA disks
by Johan De Gelas on March 20, 2009 2:00 AM EST- Posted in
- IT Computing
SQL Server and RAID 5
The RAID 5 IOMeter results were interesting and peculiar enough to warrant another testing round with SQLIO. First, we start with the least useful but "pedal to the metal" benchmark: sequential reads and writes.
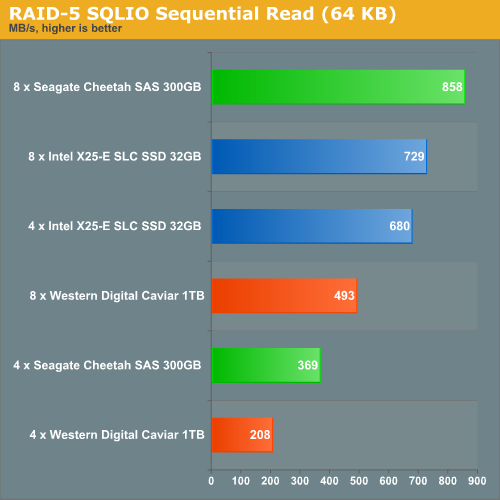

Although hardly surprising, both results are another confirmation that the SLC drives are limited by the SATA interface and the RAID controller combination.

Random reads perform as expected. The SLC SSD drives completely annihilate the magnetic disk competition.
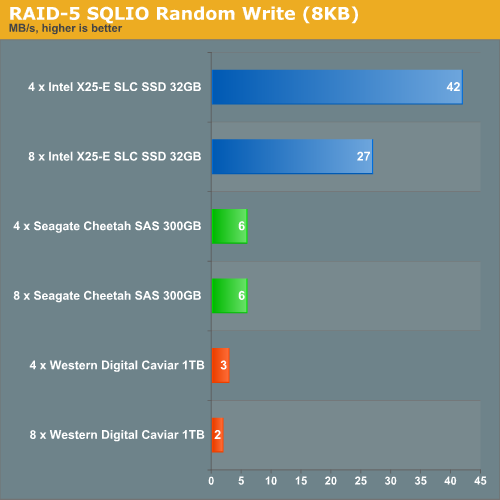
Random writes in RAID 5 are not only a complete disaster, they also confirm our theory that adding more X25-E SLC drives does not help as the storage processor cannot deliver the necessary RAID-5 processing that the SLC drives demand. The more drives you add, the worse the random writing performance becomes.








67 Comments
View All Comments
mikeblas - Friday, March 20, 2009 - link
I'm not sure how you can tell what I have or haven't tested. We tested both the X25-E and X25-M models. The issue isn't with MLC or SLC technology, but with the load-leveling algorithm the drive uses. As far as I can tell, the algorithm is fundamentally the same across both models.While they've got a great track record, Intel isn't beyond shipping products with defects. I fully agree that it's remarkable that they bill the product as enterprise-ready, when it so clearly isn't.
Running a test for 120 seconds tells us something, but at this point it doesn't tell us much more than what the other reviews have told us. We get a little more information here because of the RAID configuration, but we don't get enough details about the test methodology to have something repeatable or verifiable.
It doesn't, however, meet its claim of telling us about real-world performance. In my testing, it was a trivial matter to brick the drives after testing with Intel's own IOMeter, as well as with SQLIO, using suites we had put together using rates and ratios we had observed in our production systems.
Perhaps, since then, Intel has mitigated the problem with better firmware. At the time--only a few months ago--they were unable to provide an upgrade or a remedy when we talked with them. But I think that, if you do a test that tries to mimic real-world use both in volume and duration, you should see similar results. Even if you don't, we will learn a lot more about the drives than this review tells us.
JohanAnandtech - Sunday, March 22, 2009 - link
So basically a review is meaningless because it doesn't redo the Quality Assurance and validation tests that are done by the manufacturer? You can not honestly expect me to perform these, and they would be "meaningless" anyway as I would probably need to perform this on a batch of a few 100s of drives to get some statistical meaningful information.We have been testing these drives for weeks now, deleting 23 GB databases on 32 GB drives and creating them again, performing tests for hours and hours. We are currently running an 8 hour long tests on MS Exchange and others for our Nehalem EP Review. I have not seen the behavior you describe. EMC does not see the behavior you describe. So you were probably unfortunate to get a few bad drives... That is what the 3 year guarantee is for.
The0ne - Monday, March 23, 2009 - link
While I don't disagree with what Mikeblas is trying to say this really isn't the place for Anandtech to be the same test Manufacturers are doing or should be doing. Asking for Anandtech to prove or come up with MTBF’s and “real” life server tests aren’t valid. One very reason for this is time.For example, do we expect the banks that installs and uses our POS products to repeat the same type of testing we have? Of course not; it’s redundant, time consuming and there be no benefit for anyone. You either trust the Manufacturer’s specifications or you don’t. Seriously, you don’t want to run something for so long that eventually the product itself starts to exhibit failures and defects that that test has now introduced. The result you get wouldn’t be accurate.
And while you can trust the specs that doesn’t mean there aren’t defects in the products. There will always be defects. And with that just because you see certain issues with your test doesn’t necessarily mean they’re not secluded to just the drives you have. Heck, it might be the way your tests are set up, ran or analyze.
I believe this discussion is really pointless. If you, Mikeblas, aren’t happy there aren’t enough time involved in the testing it’s your choice. But please don’t complain on something that is, to me, subjective on how you go about doing your test.
JarredWalton - Friday, March 20, 2009 - link
I figured you didn't use the X25-E the moment you said, "We were using Intels' MLC drives." AFAIK, X25-E is SLC and not MLC, so you tested the non-enterprise version. Does the problem exist on the X25-E or not? Well, I can't answer that, and hopefully Johan will investigate the issue further. Then again, as virtualgeek states below, EMC has done extensive testing with SLC drives and hasn't seen the issues you're discussing.Anyway, this particular article was in the works for weeks if not months, so I seriously dispute any claims that it is meaningless and doesn't tell people anything new. Johan tried to do the tests in as real-world of a setup as possible. However, it's like a 60 second FRAPS run for testing a game's performance: that tells us more or less the same as if we did a 600 second or 6 hour FRAPS test, in that the average frame rates should scale similarly. What it doesn't tell is performance in every possible situation - i.e. level X may be more CPU or GPU intensive than level Y - but it gives us a repeatable baseline measurement.
At any rate, your comments are noted. Feel free to email Johan to discuss your testing and his findings further. If there's a problem that he missed, I'm sure he'll be interested in looking into the matter further. After all, he does this stuff (i.e. server configuration and testing) for work outside AnandTech, and if he's making a bad decision he would certainly want to know.
mikeblas - Saturday, March 21, 2009 - link
Sorry; that was a typo. We used both models, and reproduced the problem I describe both models.We were in direct contact with Intel, who provided the same utility they've given to other people to try and reset the drives. For some drives, it worked; one of the drives were unrecoverable. It's entirely possible we had a bad batch of six or eight drives, or that the firmware has been redesigned since. I suppose it's also possible that some incompatibility between the controllers we used and the drives exists, too. But the controllers were the ones we'd use in some production applications, and given the issues, we're just not going to move to SSDs for our online systems.
It's great that you stand behind your authors, but just because an article was in the works for a long time doesn't mean it's good or worthwhile. I just can't find the logic there.
Similarly, I'm not sure why you'd conclude that testing a game is the same as testing enterprise-level hardware. I guess that shows the fundamental flaw in both your argument about spending time on the article, and the article itself. A bad starting assumption makes a bad result, no mater how much time you spend on actually doing the work. Since the bad assumption has tainted the process, the end result will be compromised no matter how long you spend on it.
In this particular case, it should be foreseeable that the results from a short test run is not scalable to long-term, high-scale usage. At the very least, it should be obvious that there's the strong potential for difference. This is because of the presence of write-leveling technology. What are the differences between spinning media and a the SSD under test? Seek time, transfer rate, volatility, power draw, physical shock resistance, and the write-leveling algorithm. One way to stress the write-leveling algorithm is to try to overwhelm it; throw a high amount of IOPS at it for a sustained duration. What happens? Throw writes at it, only, and see what happens.
In a production system OLTP system--what you purport to be simulating--the data drive is write-mostly. A well-tuned OLTP database in steady-state operation is going to do the majority of its reads from cache. (Otherwise, it's not going to be fast enough.) All of its writes are going to disk, however, because they have to be transactionally committed. When one of these drives sees a 100% workload with a very high throughput, how does it behave compared to a spinning drive? Is the problem with tests that didn't reveal problems simply that they didn't try testing the drive in this application? That they didn't adequately simulate this application?
I'm not sure email would reveal anything I haven't already posted here.
JarredWalton - Saturday, March 21, 2009 - link
My comment re: gaming tests is that you don't need to test the game for hours to know how it behaves. Similarly, you don't need to collect results from a one week test run to know how the database setup behaves. You certainly should run for more than 120 seconds to "break in" the drives. Once that is done, you don't need to run the tests for hours at a time. A snapshot of performance for 120 seconds should look like a snapshot for two hours or two days... as long as there isn't some problem that causes performance to eventually collapse, which is what you assert.You seem to have the opinion that all he did was slap in the drives, run a 120 second test, and call it quits. I know from past experience that he put together a test system, designed tests to stress the system, ran some of the tests for hours (or days or weeks) to verify things were running as expected, and then after all that he collected data to show a snapshot of how the setup performed. At that point, whether you collect data for a short time or a long time doesn't really matter, because the drives should be well seasoned (i.e. degraded) as far as they'll go.
It is entirely possible that in the several months since you performed your tests, things have changed. It is also possible that some other hardware variable is to blame for the performance issues you experienced. A detailed list of the hardware you ran would certainly help in looking into things from our end - what server, SATA controller, drives, etc. did you utilize? What firmware version on the drives? What was the specific setup you used for SQLIO or IOMeter? Those are all useful pieces of information, as opposed to the following:
"Anyone can promptly demonstrate this to yourself with longer, more aggressive tests. (We did that, and we also spoke with the Intel support engineers. Other sites document similar problems. We were using Intels' MLC drives.)"
Links and specifics for sites that show the data you're talking about would be great, since a few quick Google searches turned up very little of use. I see non-RAID tests, Linux tests, tests using NVIDIA RAID controllers (ugh...), RAID 0 running desktop applications, etc. With further searching, I'm sure there's an article somewhere showing RAID 0, 5, and 10 performance with server hardware, but since you already know where it is a quick post with direct links would be a lot more useful.
YOUDIEMOFO - Wednesday, November 14, 2018 - link
I would love to see this test done today as costs have been drastically cut in regards to solid state drives in general.Just amazing as this article proved is the literal translation of savings to performance in the long run. Hard to imagine that the storage devices are still the bottleneck in performance when regarding throughput in a PC.