SSD versus Enterprise SAS and SATA disks
by Johan De Gelas on March 20, 2009 2:00 AM EST- Posted in
- IT Computing
SQL Server and RAID 5
The RAID 5 IOMeter results were interesting and peculiar enough to warrant another testing round with SQLIO. First, we start with the least useful but "pedal to the metal" benchmark: sequential reads and writes.
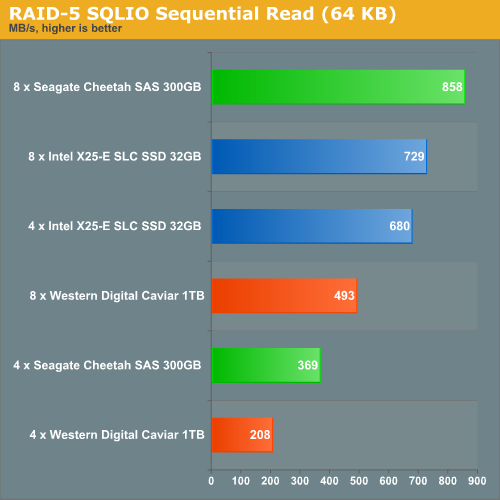

Although hardly surprising, both results are another confirmation that the SLC drives are limited by the SATA interface and the RAID controller combination.

Random reads perform as expected. The SLC SSD drives completely annihilate the magnetic disk competition.
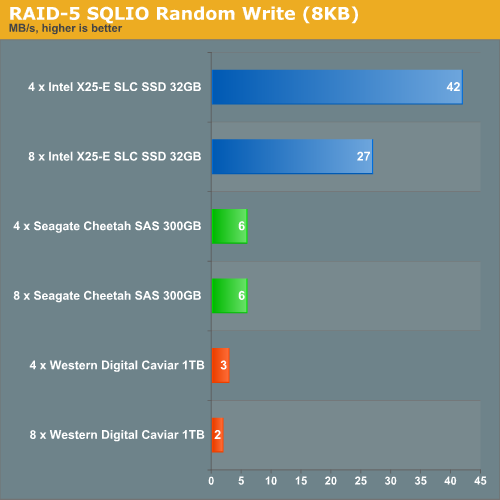
Random writes in RAID 5 are not only a complete disaster, they also confirm our theory that adding more X25-E SLC drives does not help as the storage processor cannot deliver the necessary RAID-5 processing that the SLC drives demand. The more drives you add, the worse the random writing performance becomes.








67 Comments
View All Comments
JarredWalton - Monday, March 23, 2009 - link
Judging by the content and the comments on that blog, it seems as though there are some software specific settings that may be causing problems (i.e. specifically barriers/nobarriers is mentioned several times). The end result appears to be that a single X25-E is capable of matching a RAID 10 disk in performance, but at a higher cost? I don't know, as I don't see any specific hardware listed and he only mentions receiving one drive.He did figure out a workaround to the issue by modifying the parameters, but concludes the performance isn't worth the cost. However, if a single X25-E matches a RAID 10 setup, what happens on RAID 10 X25-E? Also, what about power? Johan shows TCO with power favoring SSD by a significant margin. Even if performance is equal, if power is greatly in favor of SSD you might want to go that route.
Of course, the bigger question is whether this is software or hardware related. As one user puts it:
"Sorry, but you realize that nobarrier is the likely cause for the data loss, right? With barriers XFS fsync (but not necessarily ext3 fsync) would wait for a write barrier on the log commit, and thus also for the data. O_SYNC might be different though. Basically you specified the “please go unsafe but faster” option and then complain that it is actually unsafe. I would recommend to do the power off test without nobarriers but write cache on. -Andi"
The response: "I wrote that in post. With barrier and write cache we have 50 writes / s, which I consider “not just slower” but disaster which I would not put on production system."
Sounds to me like software/configuration problems more than anything. If he can get 1200 write/s with safe function, but only 50 with what should be a usable setting, something is wrong. More details on what hardware/software was used would be nice, naturally.
virtualgeek - Friday, March 20, 2009 - link
We've done a lot of work on this at EMC - and STEC drives have been put through the same wringers (and meet the same specs) we demand of enterprise FC and SATA drives from the 3rd parties. They are SLC-based, like the Intel X25-E, but have some of the difference noted at the tail end of the article. We continue to work with Intel (and others) - it's only goodness to have more vendors in that space.We've deployed a LOT of Enterprise Flash Disk or EFD (what we call this "sub category" of Enterprise-class solid state disk)
BUT - I can say with authority that the MTBF issue is being used at this point as FUD. MLC is a different story - which is why it's absolutely an option in the consumer space, today it's not for these applications.
mikeblas - Friday, March 20, 2009 - link
You would assume, sure. But we don't know, either way.The testing done here is naieve. First, RAID5 is the wrong RAID. Because of the way it behaves (even with a good, hardeware card) it's not really a good idea for a performant database system. RAID10 is generally the way to go.
Next, Databases run 24x7. The testing done here started, ended, and that was that. At a site that depends on their database system, they probably rewrite all the data in the database very often--between once per day and once per week, say.
If this test was intended to be meaningful, it would have run the test constantly, showing a graph of performance over time. That takes too much effort for a free review site, I suppose--when we did that exercise in house, it wasn't even a couple of hours before then Intel drives were bricked, unusable.
JohanAnandtech - Friday, March 20, 2009 - link
"The testing done here is naieve. First, RAID5 is the wrong RAID. Because of the way it behaves (even with a good, hardeware card) it's not really a good idea for a performant database system. RAID10 is generally the way to go. "You would be amazed how many people are running DB systems with RAID-5. And we performed the database system with RAID-10.
"If this test was intended to be meaningful, it would have run the test constantly, showing a graph of performance over time. "
It is a good suggestion, but that doesn't mean our testing is not meaningful. Considering how many times we performed the benchmarks, it is clear that we were not using a "virgin SLC". The numbers you are seeing are the measurements we took after a few days of testing. (Especially the RAID-5 ones)
We'll try out a very long test, but these SLC drives are quite a bit more robust than a typical MLC drive, also when it comes to performance degradation. Let us not blown this out of proportion, Anand measured a 10% performance degradation on an MLC drive. That is hardly an issue, when you get 13 times more performance than one of the best SAS drives.
mikeblas - Friday, March 20, 2009 - link
>You would be amazed how many people are running DB systems with RAID-5.
Probably not. People do dumb stuff all the time; it doesn't surprise me anymore. I mean, something subtle like using RAID-5 instead of RAID-10 on a database server is an easy mistake to make. I can be surprised at deeper dumbness, though.
Anyway, I don't see how the number of people making a mistake justifies the same mistake in a review.
> And we performed the database system with RAID-10.
I don't see any RAID 10 results in the SQL Server SQLIO test results.
> but that doesn't mean our testing is not meaningful.
Of course it does. The test doesn't stress the biggest concern with the drives in enterprise applications; it also indicates that the tester doesn't understand how the drives work.
On write-leveling SSDs, write requests take a variable amount of time; they take longer the more writes the drive has seen recently. You're worried about the drive being "virgin" or not. That's not the issue; far past the loss of "virginity", past the time degredation is first noticed, the Intel drives take many hundreds of milliseconds to perform write operations. They take so long they might even fall off the bus, and might be flagged by the RAID controller as failed. The problems show themselves after being exposed to high IOPS rates. The problem it that not only the response time increases, the latency increases, too. Eventually, the latency overcomes the ability to keep up with the incoming rate, and the device effectively fails.
Anyone can promptly demonstrate this to yourself with longer, more aggressive tests. (We did that, and we also spoke with the Intel support engineers. Other sites document similar problems. We were using Intels' MLC drives.)
Point is, though, that the article is about enterprise applications, but fails to adequately simulate a large class of enterprise applications. Running a database benchmark for just a few minutes doesn't adequately stress the drives. This makes it meaningless; it's not telling readers anything more than the consumer-level reviews have, since it's not stressing the drive in the way enterprise applications would use it.
Spinning drives eat sustained high IOPS rates up, particularly enterprise class drives, which are engineered for such application. SSDs fail, or exhibit erratic performance that makes the predictability an reliability guarantees required of enterprise applications impossible to deliver. They're not 10% slower as you claim; they're 100% slower, or they're DNF -- or however you want to represent divide-by-zero slower.
virtualgeek - Friday, March 20, 2009 - link
Gang - you can't do a test on an MLC drive, and compare it to an SLC test - it's totally different.RAID-5 configs for EFDs in CLARiiON and DMX arrays are not uncommon at all, and through much testing - did absolutely fine.
The traditional RAID penalty logic of rotating media and parity RAID write impact is not entirely applicable here either.
There are LOADS of detailed performance tests at different workloads here:
http://virtualgeek.typepad.com/virtual_geek/2009/0...">http://virtualgeek.typepad.com/virtual_...sks-ente...
I posted links to docs with the big database workloads and exchange.
Literally - we've been doing this for more than a year (shipping STEC-based EFDs into enteprises). The comments are partially right - but not all write-levelling algorithms are the same, and not all SSDs have the same internal architecture.
mikeblas - Friday, March 20, 2009 - link
Britney Spears albums aren't uncommon, either. But that doesn't mean they are any good and "did fine" is far from "optimal".RagingDragon - Thursday, March 26, 2009 - link
For enterprise systems "optimal" is sufficient performance at the lowest possible price, not highest possible performance at any cost.For a given amount of storage, RAID5 requires fewer disks (and thus costs less) than RAID10, so if RAID5 can provide sufficient performance it is more optimal than RAID10. For workloads where RAID10 provides adequate peformance, but RAID5 does not, obviously RAID10 is more optimal. And for workloads where RAID10 cannot deliver the required performance there are in memory databases
RagingDragon - Thursday, March 26, 2009 - link
Also, the high end systems virtualgeek refers to have far more RAM cache and processing power than any RAID card, so experience with RAID cards may not be applicable to them.JarredWalton - Friday, March 20, 2009 - link
You make a lot of claims, but as far as I can tell you have not tested with the enterprise X25-E, which costs three times as much as the X25-M. Intel wouldn't release something for the enterprise at that price without at least trying to make it handle the situation properly.As for the testing, Johan *benchmarks* a test run that lasts several minutes. That doesn't mean that the test was only run for several minutes, but rather that the final benchmark score is from a test run of a couple minutes (120 seconds to be exact). Knowing how Johan tests, retests, changes tests, etc. often dozens of times in the course of writing an article, this is definitely not a "meaningless" test result. Rather, it is a look at the best we can do with simulating a real world environment without actually doing everything in the real world (because the real world doesn't usually lend itself to repeatable benchmarks).
Do the drives have long-term reliability issues? Can performance drop off substantially in certain situations? Anand suggests that it can happen with the X25-M and pretty much every other SSD out there, but I don't know if he actually tested the same thing with X25-E. It sounds as though it's a possibility it will occur after certain event sequences (involving high I/O levels), but you'd really have to test with the enterprise class drives to know for sure. Hopefully Anand and Johan can work on that a bit to verify whether or not that problem exists; if it does, I'm fairly confident that Intel will update the firmware to fix the issue - otherwise, as you say the SSDs would be useless in the enterprise.