The SSD Anthology: Understanding SSDs and New Drives from OCZ
by Anand Lal Shimpi on March 18, 2009 12:00 AM EST- Posted in
- Storage
Putting Theory to Practice: Understanding the SSD Performance Degradation Problem
Let’s look at the problem in the real world. You, me and our best friend have decided to start making SSDs. We buy up some NAND-flash and build a controller. The table below summarizes our drive’s characteristics:
| Our Hypothetical SSD | |
| Page Size | 4KB |
| Block Size | 5 Pages (20KB) |
| Drive Size | 1 Block (20KB |
| Read Speed | 2 KB/s |
| Write Speed | 1 KB/s |
Through impressive marketing and your incredibly good looks we sell a drive. Our customer first goes to save a 4KB text file to his brand new SSD. The request comes down to our controller, which finds that all pages are empty, and allocates the first page to this text file.
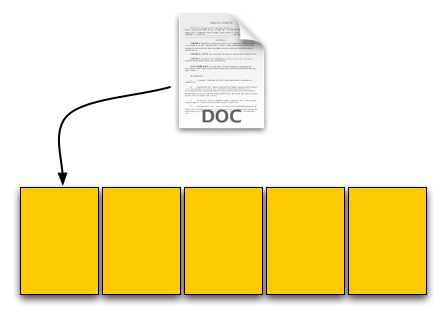
Our SSD. The yellow boxes are empty pages
The user then goes and saves an 8KB JPEG. The request, once again, comes down to our controller, and fills the next two pages with the image.
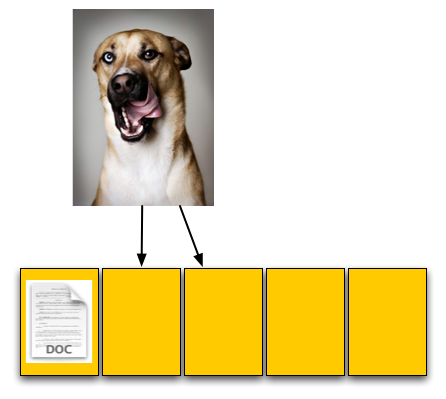
The picture is 8KB and thus occupies two pages, which are thankfully empty
The OS reports that 60% of our drive is now full, which it is. Three of the five open pages are occupied with data and the remaining two pages are empty.
Now let’s say that the user goes back and deletes that original text file. This request doesn’t ever reach our controller, as far as our controller is concerned we’ve got three valid and two empty pages.
For our final write, the user wants to save a 12KB JPEG, that requires three 4KB pages to store. The OS knows that the first LBA, the one allocated to the 4KB text file, can be overwritten; so it tells our controller to overwrite that LBA as well as store the last 8KB of the image in our last available LBAs.
Now we have a problem once these requests get to our SSD controller. We’ve got three pages worth of write requests incoming, but only two pages free. Remember that the OS knows we have 12KB free, but on the drive only 8KB is actually free, 4KB is in use by an invalid page. We need to erase that page in order to complete the write request.

Uhoh, problem. We don't have enough empty pages.
Remember back to Flash 101, even though we have to erase just one page we can’t; you can’t erase pages, only blocks. We have to erase all of our data just to get rid of the invalid page, then write it all back again.
To do so we first read the entire block back into memory somewhere; if we’ve got a good controller we’ll just read it into an on-die cache (steps 1 and 2 below), if not hopefully there’s some off-die memory we can use as a scratch pad. With the block read, we can modify it, remove the invalid page and replace it with good data (steps 3 and 4). But we’ve only done that in memory somewhere, now we need to write it to flash. Since we’ve got all of our data in memory, we can erase the entire block in flash and write the new block (step 5).

Now let’s think about what’s just happened. As far as the OS is concerned we needed to write 12KB of data and it got written. Our SSD controller knows what really transpired however. In order to write that 12KB of data we had to first read 12KB then write an entire block, or 20KB.
Our SSD is quite slow, it can only write at 1KB/s and read at 2KB/s. Writing 12KB should have taken 12 seconds but since we had to read 12KB and then write 20KB the whole operation now took 26 seconds.
To the end user it would look like our write speed dropped from 1KB/s to 0.46KB/s, since it took us 26 seconds to write 12KB.
Are things starting to make sense now? This is why the Intel X25-M and other SSDs get slower the more you use them, and it’s also why the write speeds drop the most while the read speeds stay about the same. When writing to an empty page the SSD can write very quickly, but when writing to a page that already has data in it there’s additional overhead that must be dealt with thus reducing the write speeds.








250 Comments
View All Comments
strikeback03 - Thursday, March 19, 2009 - link
If you get Newegg's specials, one of the codes is for the 30GB for $103 with a $20MIR, so $83 with shipping if the rebate comes through. At the size I would want (~120) the Super Talent undercuts the OCZ slightly.Does anyone know if you can install the firmware of one maker to another maker's SSD? For example, assuming both the Ultradrive ME and the Vertex use the same Indilinx controller, and say Super Talent chose to release it with the firmware which optimizes for higher sequential speeds, would the user be able to choose the firmware which optimizes for less latency?
Testtest - Wednesday, March 18, 2009 - link
Ah, no editing?!A-Data's "300 plus" SSD also uses the Indilinx controller.
vailr - Wednesday, March 18, 2009 - link
"The Anatomy of a SSD" should instead read: "The Anatomy of an SSD"Flunk - Wednesday, March 18, 2009 - link
Yes, because S is a vowel...abudd - Wednesday, March 18, 2009 - link
Assuming SSD = "es-es-dee" then "an SSD" is right. If it *sounds* like a vowel, use "an".JarredWalton - Wednesday, March 18, 2009 - link
Yes, *but* SSD could also be read as "Solid State Drive" instead of "ess ess dee", in which case you would say "a SSD". I tend to read it as "ess ess dee", but Anand thinks of those letters as "Solid State Drive".Potato, potato, tomato, tomato... let's call the whole thing off!
Azsen - Thursday, March 19, 2009 - link
When reading acronyms you're supposed to think of them as the letters, i.e. when you see RAM, you think "ram" straight off not Random Access Memory. When you see "IBM" you think "eye bee emm" not International Business Machines etc etc. It would take ages to read an article if you had to stop and think out all the full wording of acronyms as you're reading them.I'm going with the correction of "Anatomy of an SSD". Correct English fullstop.
JarredWalton - Thursday, March 19, 2009 - link
By your comment, you suggest two different things, and that's really okay. That was my point: when you see "RAM" you probably thing "ram" as in the animal... not "Are A Em". You say "a RAM stick" not "an RAM stick". I'd guess most people think of SATA as "Ess A Tee A", but if you talk to most computer techs that are in the know, it's "say-te" so you would say "a SATA drive".And you know, I'm sure plenty of people will agree with the correct way of saying SATA, and that's perfectly okay. English really is a very flexible thing - particularly in the tech world - and rarely is there an "always right" way of saying things. If Anand wants to say "a SSD" and others want to say "an SSD", I'm not going to try to declare one group or the other correct. They both are, depending on your viewpoint.
"I believe the world is neither black nor white, but only shades of gray."
Pythias - Friday, March 20, 2009 - link
Can't have gray without black and white.7Enigma - Wednesday, March 18, 2009 - link
HAHAHA. What a tool. I love it when people critique grammar.....and get it wrong.