The SSD Anthology: Understanding SSDs and New Drives from OCZ
by Anand Lal Shimpi on March 18, 2009 12:00 AM EST- Posted in
- Storage
Putting Theory to Practice: Understanding the SSD Performance Degradation Problem
Let’s look at the problem in the real world. You, me and our best friend have decided to start making SSDs. We buy up some NAND-flash and build a controller. The table below summarizes our drive’s characteristics:
| Our Hypothetical SSD | |
| Page Size | 4KB |
| Block Size | 5 Pages (20KB) |
| Drive Size | 1 Block (20KB |
| Read Speed | 2 KB/s |
| Write Speed | 1 KB/s |
Through impressive marketing and your incredibly good looks we sell a drive. Our customer first goes to save a 4KB text file to his brand new SSD. The request comes down to our controller, which finds that all pages are empty, and allocates the first page to this text file.
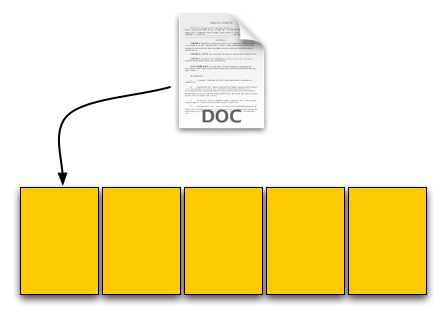
Our SSD. The yellow boxes are empty pages
The user then goes and saves an 8KB JPEG. The request, once again, comes down to our controller, and fills the next two pages with the image.
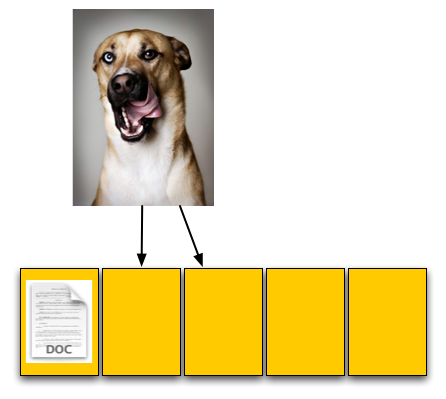
The picture is 8KB and thus occupies two pages, which are thankfully empty
The OS reports that 60% of our drive is now full, which it is. Three of the five open pages are occupied with data and the remaining two pages are empty.
Now let’s say that the user goes back and deletes that original text file. This request doesn’t ever reach our controller, as far as our controller is concerned we’ve got three valid and two empty pages.
For our final write, the user wants to save a 12KB JPEG, that requires three 4KB pages to store. The OS knows that the first LBA, the one allocated to the 4KB text file, can be overwritten; so it tells our controller to overwrite that LBA as well as store the last 8KB of the image in our last available LBAs.
Now we have a problem once these requests get to our SSD controller. We’ve got three pages worth of write requests incoming, but only two pages free. Remember that the OS knows we have 12KB free, but on the drive only 8KB is actually free, 4KB is in use by an invalid page. We need to erase that page in order to complete the write request.

Uhoh, problem. We don't have enough empty pages.
Remember back to Flash 101, even though we have to erase just one page we can’t; you can’t erase pages, only blocks. We have to erase all of our data just to get rid of the invalid page, then write it all back again.
To do so we first read the entire block back into memory somewhere; if we’ve got a good controller we’ll just read it into an on-die cache (steps 1 and 2 below), if not hopefully there’s some off-die memory we can use as a scratch pad. With the block read, we can modify it, remove the invalid page and replace it with good data (steps 3 and 4). But we’ve only done that in memory somewhere, now we need to write it to flash. Since we’ve got all of our data in memory, we can erase the entire block in flash and write the new block (step 5).

Now let’s think about what’s just happened. As far as the OS is concerned we needed to write 12KB of data and it got written. Our SSD controller knows what really transpired however. In order to write that 12KB of data we had to first read 12KB then write an entire block, or 20KB.
Our SSD is quite slow, it can only write at 1KB/s and read at 2KB/s. Writing 12KB should have taken 12 seconds but since we had to read 12KB and then write 20KB the whole operation now took 26 seconds.
To the end user it would look like our write speed dropped from 1KB/s to 0.46KB/s, since it took us 26 seconds to write 12KB.
Are things starting to make sense now? This is why the Intel X25-M and other SSDs get slower the more you use them, and it’s also why the write speeds drop the most while the read speeds stay about the same. When writing to an empty page the SSD can write very quickly, but when writing to a page that already has data in it there’s additional overhead that must be dealt with thus reducing the write speeds.








250 Comments
View All Comments
coil222 - Wednesday, March 18, 2009 - link
Yes I run a pair of MTRON 7500s in a raid 0 stripe for my OS and Gaming (wow). I don't recall numbers off the top of my head but tests were better on the raid 0 than a single drive configuration.Watch this:
http://www.youtube.com/watch?v=96dWOEa4Djs&fea...">http://www.youtube.com/watch?v=96dWOEa4Djs&fea...
sawyeriii - Wednesday, March 18, 2009 - link
I just wanted to state how much I loved the combination of technical and real world information in this article.What is the possibility of having different page sizes built into a drive? I.e. you could have a drive with many 1k page packages on one die, 2k on another, and most others 4k. Could that theoretically help? Could the controllers work with that (or would you need to combine multiple 1k's into a 4k transfer size)?
PS One note on page 3, the VelociRaptor and Intel in the first chart (responce time) are switched, however the text is correct.
StormyParis - Wednesday, March 18, 2009 - link
the ugly truth is that an SSD won't let you do anything that you couldn't do without it, and due to its cost and small capacity, it's not a replacement drive, it's an extra drive: not less power consumption but more, not less noise but just the same. You just gain a bit of time when booting up and lauching apps... which I do about 1/week and 1/day, respectively. Assuming your system has enough RAM (and if it doesn't, buy RAM before buying an SSD !), you won't feel much difference once the apps are launched.For the same cost, I'd rather buy a bigger screen.
It's urgent to wait for prices to come down. But I'm all for lots of people buying them now and help get the price down for us wiser buyers.
Rasterman - Thursday, March 19, 2009 - link
I've already decided my next system in a few months will have one, after you go through 5 hard drive failures (over several years) lets see how much your willing to pay to not have to put up with it anymore. If you use your PC for anything useful (work) then an SSD is a no brainer even at $1000/64GB IMO if the data security is there, speed is secondary for me.When you already have the best screen, video card, memory, why not have the best drive? And your argument is pretty dumb, almost any upgrade won't let you do anything that you couldn't do without it, not just SSDs.
Calin - Wednesday, March 18, 2009 - link
You get lower power due to the lower power use of the SSD and the fact that the other drive is not stressed with difficult access patterns (small random reads/writes). Remember that idle power of a SSD drive is very low7Enigma - Wednesday, March 18, 2009 - link
No, his comment was accurate for most users. Due to the small capacities and high cost these will be used as boot drives primarily with maybe a single heavily used program (say the current game or program you are playing/using), the rest will be on an additional drive. So while the power consumption of the SSD would be less than the old drive, the aggregate power usage of both (even when the larger storage drive is primarily at idle) will be higher than the single HD.And I believe you meant to say traditional HD for idle power?
strikeback03 - Wednesday, March 18, 2009 - link
If all you were going to throw on the drive is the OS and a game, a 32GB drive should be plenty. The reason the 80GB and up range is important is so general consumers can load all their programs on it.But yes, in consumer usage other than a laptop, some people who were previously using one drive for both boot and storage would likely need a mechanical HDD is addition to the SSD. OTOH, those who were using a Velociraptor (or RAID array) for boot and another drive for storage will see their power consumption decrease.
sawyeriii - Wednesday, March 18, 2009 - link
Have you used a SSD? (If so which)I would state that it is not a luxary product, it is a premium product. The price difference you pay WILL translate to faster performance (if you choose correctly). More RAM only helps upto a point.
Remember performance is based on a system of parts...
CPU
RAM
NORTHBRIDGE
GPU
SOUTHBRIDGE
I/O INTERFACE
HDD/SDD
Microsoft's Windows Experience Index has specific flaws, but the concept is sound... The system can only go a fast as the slowest component in the system (relative to the amount of time used by that component).
Testtest - Wednesday, March 18, 2009 - link
... there's also Supertalent's Ultradrive ME (MLC) and LE (SLC) and Photofast's G-Monster v3At least the Supertalent drives are quite a bit cheaper with the same drive layout/controller than the Vertex drives and only differ in the firmware (which isn't bad either).
It's however possible at least with the Ultradrive ME currently to provoke a kinda timeout error after they've been fully filled once and then still beeing written on. I don't own a Vertex so I can't test that there but if it was a controller issue, it should pop up there sooner or later as well (if you take a look in their suppport forum some error reports seem very similar).
Intels have their 80% bug, Indilinx drives have their issues too it seems - let's hope that firmware can cure it!
Great article btw!
iwod - Thursday, March 19, 2009 - link
Both SuperTalent and OCZ 30 / 32 GB drive cost exactly the same on NewEgg$129