The SSD Anthology: Understanding SSDs and New Drives from OCZ
by Anand Lal Shimpi on March 18, 2009 12:00 AM EST- Posted in
- Storage
Putting Theory to Practice: Understanding the SSD Performance Degradation Problem
Let’s look at the problem in the real world. You, me and our best friend have decided to start making SSDs. We buy up some NAND-flash and build a controller. The table below summarizes our drive’s characteristics:
| Our Hypothetical SSD | |
| Page Size | 4KB |
| Block Size | 5 Pages (20KB) |
| Drive Size | 1 Block (20KB |
| Read Speed | 2 KB/s |
| Write Speed | 1 KB/s |
Through impressive marketing and your incredibly good looks we sell a drive. Our customer first goes to save a 4KB text file to his brand new SSD. The request comes down to our controller, which finds that all pages are empty, and allocates the first page to this text file.
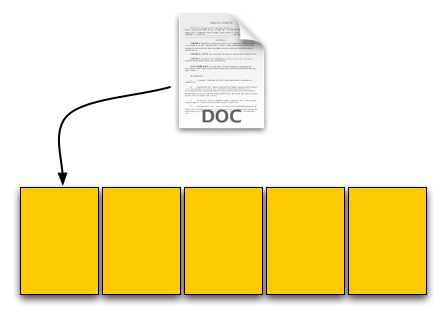
Our SSD. The yellow boxes are empty pages
The user then goes and saves an 8KB JPEG. The request, once again, comes down to our controller, and fills the next two pages with the image.
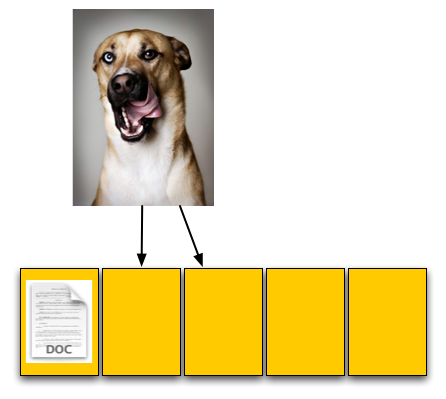
The picture is 8KB and thus occupies two pages, which are thankfully empty
The OS reports that 60% of our drive is now full, which it is. Three of the five open pages are occupied with data and the remaining two pages are empty.
Now let’s say that the user goes back and deletes that original text file. This request doesn’t ever reach our controller, as far as our controller is concerned we’ve got three valid and two empty pages.
For our final write, the user wants to save a 12KB JPEG, that requires three 4KB pages to store. The OS knows that the first LBA, the one allocated to the 4KB text file, can be overwritten; so it tells our controller to overwrite that LBA as well as store the last 8KB of the image in our last available LBAs.
Now we have a problem once these requests get to our SSD controller. We’ve got three pages worth of write requests incoming, but only two pages free. Remember that the OS knows we have 12KB free, but on the drive only 8KB is actually free, 4KB is in use by an invalid page. We need to erase that page in order to complete the write request.

Uhoh, problem. We don't have enough empty pages.
Remember back to Flash 101, even though we have to erase just one page we can’t; you can’t erase pages, only blocks. We have to erase all of our data just to get rid of the invalid page, then write it all back again.
To do so we first read the entire block back into memory somewhere; if we’ve got a good controller we’ll just read it into an on-die cache (steps 1 and 2 below), if not hopefully there’s some off-die memory we can use as a scratch pad. With the block read, we can modify it, remove the invalid page and replace it with good data (steps 3 and 4). But we’ve only done that in memory somewhere, now we need to write it to flash. Since we’ve got all of our data in memory, we can erase the entire block in flash and write the new block (step 5).

Now let’s think about what’s just happened. As far as the OS is concerned we needed to write 12KB of data and it got written. Our SSD controller knows what really transpired however. In order to write that 12KB of data we had to first read 12KB then write an entire block, or 20KB.
Our SSD is quite slow, it can only write at 1KB/s and read at 2KB/s. Writing 12KB should have taken 12 seconds but since we had to read 12KB and then write 20KB the whole operation now took 26 seconds.
To the end user it would look like our write speed dropped from 1KB/s to 0.46KB/s, since it took us 26 seconds to write 12KB.
Are things starting to make sense now? This is why the Intel X25-M and other SSDs get slower the more you use them, and it’s also why the write speeds drop the most while the read speeds stay about the same. When writing to an empty page the SSD can write very quickly, but when writing to a page that already has data in it there’s additional overhead that must be dealt with thus reducing the write speeds.








250 Comments
View All Comments
sbuckler - Wednesday, March 18, 2009 - link
Depends on how smart the controller is? Shuffling around the data now and again in the background would make sense.Frallan - Wednesday, March 18, 2009 - link
@AT
This is why i come to AT to read up on the developments.
@OCZ
Well played :0)
The ruler of the roost are the Intels however I will be able to afford one of those when there are cows enjoying themselfs by dancing on the moon. My next upgrade will be a Vertex - not only bc its Valu for money but equally much bc. OCZ obviously takes care of thier customers and listens to reason.
pmonti80 - Wednesday, March 18, 2009 - link
This is the kind of article that makes me come back here.nowayout99 - Wednesday, March 18, 2009 - link
OCZ, you should listen to Uncle Anand. ;) Hopefully Mr. Petersen understands that it's tough love.And the final product seems perfectly cool -- great performance at a better price than Intel. It's the first SSD I'd be able to reasonably consider.
SOLIDNecro - Wednesday, March 18, 2009 - link
Thx for this article Anand, I have been in a hotly contested debate over OCZ vs Samsung with my "Asperger Enhanced" nemisis/close friend...(In all fairness, I should mention I use the BiPolar SSE instruction set myself)
He was only looking at Samsung, I said he should look into what OCZ has now.
His reply was "I don't know them, and don't want to be disapointed"
(Long story behind that...He's from the Server/Workstain/HPC crowd, I am from the hardcore OC/Gamer/Desktop group, so he is not familiar with OCZ)
Looks like the Samsung (And alot of others) has "Issues" with performance degrading over time that are somewhat solved by Intel and OCZ (Plus maybe a few other companies that use the Rev B JMicron controller on there low cost SSD's)
I agree the OCZ Vertex offers the best bang for low buck SSD today, and I am tempted to grab one. But a year from now, anyone that bought a current gen MLC SSD will be saying "I coulda had a V-8" if that TRIM technology does what it promises!!!
James5mith - Wednesday, March 18, 2009 - link
As people continue to try and push the envelope of storage performance in a variety of ways, and as 6gbps SATA becomes available, the performance of SSD's will only go up.As always, I wanted to say thanks for the great article and keep them coming. It's the only way the rest of us can keep pace with what's happening out there in the world of performance storage.
vailr - Wednesday, March 18, 2009 - link
Is there any benefit in using 2 SSD's in a Raid 0 configuration?And: any differences between motherboard Intel Raid vs. a Raid controller card from Areca, for example. Also: can the "Trim" command work while in Raid mode? Probably not, I'm guessing...
7Enigma - Thursday, March 19, 2009 - link
Raid0 is really the holy grail for SSD's. The low risk of failure of SSD's which normally makes Raid0 with typical mechanical HD's more dangerous is very appealing. My personal storage-size goal is ~120-160gigs. Once they reach that size for under $300 I think I'm going to jump in. But I'm more likely to grab 2 60's or 2 80's and Raid0 them than get a single large SSD. The added performance will outweigh the higher power draw of 2 drives, and should make them extremely competitive with Intel's offerings (or whatever holds the crown at the time).I figure it will be about a year or so until the prices are in that range, as 2 60gig Vertex drives will currently run you about $400 after rebate.
I can't wait to jump on that upgrade and will then put my current 250gig mechanical drive as the storage drive (I don't use a ton of space in general as I have a 320gig external backup).
Rasterman - Thursday, March 19, 2009 - link
The problem with doing that is if you want to move your drives to another system they won't work, so upgrading is a pain. You could image them I guess, but plugging one drive in is much simpler. I had an older XP install that made it through 3-4 different systems.I would also question real world results, if you're going at 250MB/s or 500MB/s its not even going to be noticeable unless you are doing some massive video editing or some other huge file operations, and as Anand says, SSDs don't fill this role right now as they are super expensive per GB. So if you really are editing video a lot, you are going to need a hell of a lot more space than SSDs can offer you.
Gasaraki88 - Friday, March 20, 2009 - link
RAID is a universal standard so if you take two RAID0 drives out and move them to another computer with a RAID controller, it SHOULD just work if the original RAID was doing it correctly.