The Nehalem Preview: Intel Does It Again
by Anand Lal Shimpi on June 5, 2008 12:05 AM EST- Posted in
- CPUs
Faster Unaligned Cache Accesses & 3D Rendering Performance
3dsmax r9
Our benchmark, as always, is the SPECapc 3dsmax 8 test but for the purpose of this article we only run the CPU rendering tests and not the GPU tests.
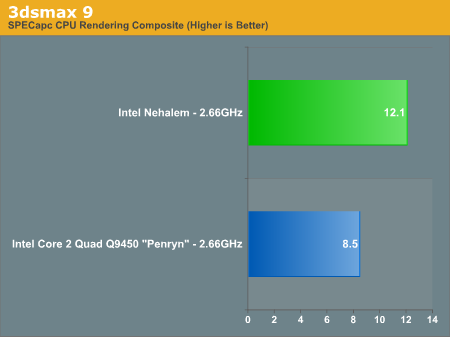
The results are reported as render times in seconds and the final CPU composite score is a weighted geometric mean of all of the test scores.
| CPU / 3dsmax Score Breakdown | Radiosity | Throne Shadowmap | CBALLS2 | SinglePipe2 | Underwater | SpaceFlyby | UnderwaterEscape |
| Nehalem (2.66GHz) | 12.891s | 11.193s | 5.729s | 20.771s | 24.112s | 30.66s | 27.357s |
| Penryn (2.66GHz) | 19.652s | 14.186s | 13.547s | 30.249s | 32.451s | 33.511s | 31.883s |
The CBALLS2 workload is where we see the biggest speedup with Nehalem, performance more than doubles. It turns out that CBALLS2 calls a function in the Microsoft C Runtime Library (msvcrt.dll) that can magnify the Core architecture's performance penalty when accessing data that is not aligned with cache line boundaries. Through some circuit tricks, Nehalem now has significantly lower latency unaligned cache accesses and thus we see a huge improvement in the CBALLS2 score here. The CBALLS2 workload is the only one within our SPECapc 3dsmax test that really stresses the unaligned cache access penalty of the current Core architecture, but there's a pretty strong performance improvement across the board in 3dsmax.
Nehalem is just over 40% faster than Penryn, clock for clock, in 3dsmax.
Cinebench R10
A benchmarking favorite, Cinebench R10 is designed to give us an indication of performance in the Cinema 4D rendering application.
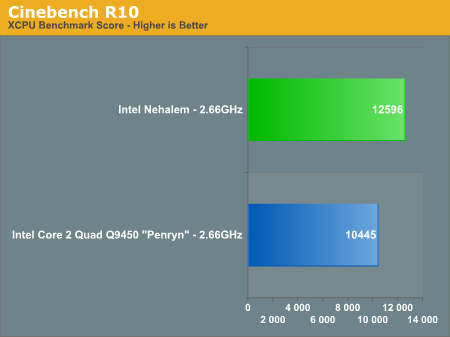
Cinebench also shows healthy gains with Nehalem, performance went up 20% clock for clock over Penryn.
We also ran the single-threaded Cinebench test to see how performance improved on an individual core basis vs. Penryn (Updated: The original single-threaded Penryn Cinebench numbers were incorrect, we've included the correct ones):
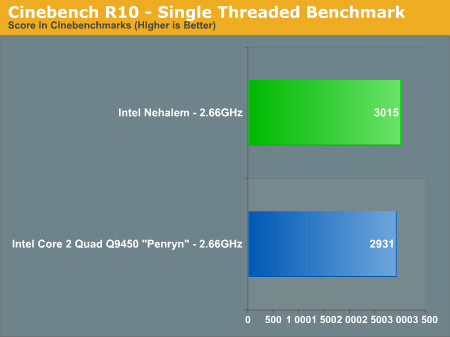
Cinebench shows us only a 2% increase in core-to-core performance from Penryn to Nehalem at the same clock speed. For applications that don't go out to main memory much and can stay confined to a single core, Nehalem behaves very much like Penryn. Remember that outside of the memory architecture and HT tweaks to the core, Nehalem's list of improvements are very specific (e.g. faster unaligned cache accesses).
The single thread to multiple thread scaling of Penryn vs. Nehalem is also interesting:
| Cinebench R10 | 1 Thread | N-Threads | Speedup |
| Nehalem (2.66GHz) | 3015 | 12596 | 4.18x |
| Core 2 Quad Q9450 - Penryn - (2.66GHz) | 2931 | 10445 | 3.56x |
The speedup confirms what you'd expect in such a well threaded FP test like Cinebench, Nehalem manages to scale better thanks to Hyper Threading. If Nehalem had the same 3.56x scaling factor that we saw with Penryn it would score a 10733, virtually inline with Penryn. It's Hyper Threading that puts Nehalem over the edge and accounts for the rest of the gain here.
While many 3D rendering and video encoding tests can take at least some advantage of more threads, what about applications that don't? One aspect of Nehalem's performance we're really not stressing much here is its IMC performance since most of these benchmarks ended up being more compute intensive. Where HT doesn't give it the edge, we can expect some pretty reasonable gains from Nehalem's IMC alone. The Nehalem we tested here is crippled in that respect thanks to a premature motherboard, but gains on the order of 20% in single or lightly threaded applications is a good expectation to have.
POV-Ray 3.7 Beta 24
POV-Ray is a popular raytracer, also available with a built in benchmark. We used the 3.7 beta which has SMP support and ran the built in multithreaded benchmark.
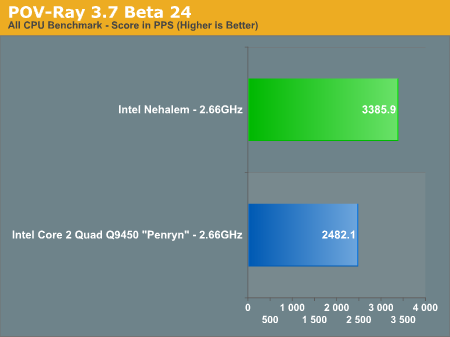
Finally POV-Ray echoes what we've seen elsewhere, with a 36% performance improvement over the 2.66GHz Core 2 Q9450. Note that Nehalem continues to be faster than even the fastest Penryns available today, despite the lower clock speed of this early sample.








108 Comments
View All Comments
SiliconDoc - Monday, July 28, 2008 - link
lol- Buddy you are thinking.magreen - Thursday, June 5, 2008 - link
Thanks for the amazing preview, Anand!I hope you and Gary will get us more Nehalem information quick like bunnies.
yottabit - Thursday, June 5, 2008 - link
Great Article Anand! I'm so excited for this new technology. But that socket and triple channel memory archetecture makes me want to puke in my mouth a little bit. It's very reminiscent to me of the Socket 423/RDRAM era. I have the feeling that they are going to release this setup for a lot of the early adopters and then screw them over by dropping the socket completely, when they decide that Dual Channel DDR3 is fast enough. I can't picture two platforms running side by side, with two entirely different sockets. People whant a Nehalem but need 4 gigs of ram will end up buying 6 Gigs of ram... and DDR3 ain't exactly cheap.I wish they had plans to through this into the mainstream faster. I'd love to have one of these, in dual channel variety. I'm still running an old early A64, and I'm holding out for these next gen processors in the next year or two.
Its awesome to see that nice performance per clock increase, but the triple channel memory is a real slap in the face to me. Its like Intel saying "look, we increase clock for clock performance, but we also decided to use some brute force and raise our power consumption and motherboard complexity for no reason by adding another impractical memory channel". I don't see it as elegant at all. I think they are overcompensating for their lack of memory bandwith in recent times. :-
Maybe AMD will have a chance to jump in with some nicer Phenom's before Nehalem comes out and actually capture some quad core market?
npp - Thursday, June 5, 2008 - link
I'm tired of all those people who just can live with the fact that the world is spinning and the CPUs that were reviewed here are simply far faster than the Penryn or Phenom you just bought yesterday... Get used to the fact, this is how thing happen today. Nehalem will be probably the most advanced x86 (x64) CPU when launched, and it just happened that Intel developed it - it could have been anybody else, say AMD, or nVidia, or whoever you prefer, no difference to me. Things go ahead, and some vendors simply get the job done first, in the grand scheme of things, it is all the same. All those fanboys I see around sound like some 3 year old children fighting for candy to me, It's amusing to see how AMD or Intel PR locked you up, guys.Now a brief question, aimed directly at Anand, I guess: I still can't figure out why memory performance is so low even via an advanced controller such as Nehalem's. As far as I can tell, 3-channel DDR3-1066 should be able to deliver up to 25,5 GB/s of bandwidth, far from the figures we see. How does this happen? And once more: you measured some 46ms latency altogether, how was that obtained? Assuming memory clock of 133Mhz, this should yield something like CAS4 (~30ms) latencies for the memory, am I right?
fitten - Thursday, June 5, 2008 - link
30usAs far as single/dual/triple channel, it seems that Anand and gang were able to test with all three modes (you'll notice the comment about WinRAR being 10% faster with triple channel compared to single channel on the pre-release motherboard)... so you don't *have* to buy 3 sticks of memory... if you want 4GiB, you should be able to get 1x4 or 2x2 and leave the other slot(s) empty.
npp - Thursday, June 5, 2008 - link
It's all nanoseconds, of course, not milli- or micro, my fault. Never mind, I'm still awaiting some reasonable explanation about the "modest" bandwidth measured. 12GB/s copy is by no means little - I can't say if it's achievable via overclocking today, I'm not into that kind of business - but still I would guess no. Still, it seems little compared to the max. theoretical values.Anand Lal Shimpi - Thursday, June 5, 2008 - link
I think we may have to wait for a final Nehalem platform before we can make any calls on memory bandwidth figures, but do keep in mind that the amount of usable memory bandwidth will depend largely on how it's being measured. If the algorithm is even slightly compute bound we won't see perfect scaling with theoretical memory bandwidth.I'm not sure how Everest measures bandwidth so I can't tell you exactly what numbers we should be seeing there, but it is useful for comparing a relative increase in bandwidth between Penryn and Nehalem.
Take care,
Anand
npp - Thursday, June 5, 2008 - link
Thank you very much, very kind of you to bother answering my question! Keep up the good work here at Anandtech.NINaudio - Thursday, June 5, 2008 - link
I'm not sure hwy everyone is so concerned about DDR3 prices being high. A quick check shows that you can get a 2gig kit of ddr3-1600 for under $150 already. By the time Nehalem is out for mass consumption ddr3 will be even cheaper. I would say that it's pretty realistic to expect to be able to get a 3gig triple channel kit for under $100 and a 6gig triple channel kit for around $175 by the time nehalem is available to us.Anand Lal Shimpi - Thursday, June 5, 2008 - link
What I'm really interested in is why Intel felt that Nehalem needed a three channel DDR3 memory controller. Will it really be necessary for higher clocked Nehalem (or is it Nehalems)? It'd be great for the versions of Nehalem with integrated graphics but I figured those would mostly be pushed into the mainstream, dual channel SKUs anyways. Looks like we'll have to wait at least a few more months before we can find out for sure.-A