The Nehalem Preview: Intel Does It Again
by Anand Lal Shimpi on June 5, 2008 12:05 AM EST- Posted in
- CPUs
Faster Unaligned Cache Accesses & 3D Rendering Performance
3dsmax r9
Our benchmark, as always, is the SPECapc 3dsmax 8 test but for the purpose of this article we only run the CPU rendering tests and not the GPU tests.
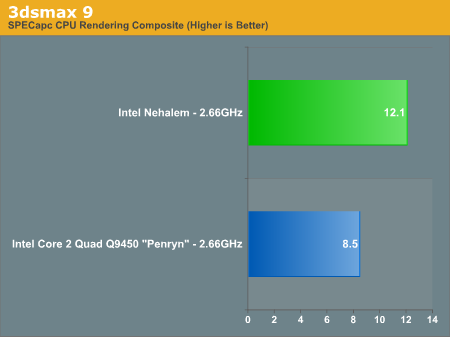
The results are reported as render times in seconds and the final CPU composite score is a weighted geometric mean of all of the test scores.
| CPU / 3dsmax Score Breakdown | Radiosity | Throne Shadowmap | CBALLS2 | SinglePipe2 | Underwater | SpaceFlyby | UnderwaterEscape |
| Nehalem (2.66GHz) | 12.891s | 11.193s | 5.729s | 20.771s | 24.112s | 30.66s | 27.357s |
| Penryn (2.66GHz) | 19.652s | 14.186s | 13.547s | 30.249s | 32.451s | 33.511s | 31.883s |
The CBALLS2 workload is where we see the biggest speedup with Nehalem, performance more than doubles. It turns out that CBALLS2 calls a function in the Microsoft C Runtime Library (msvcrt.dll) that can magnify the Core architecture's performance penalty when accessing data that is not aligned with cache line boundaries. Through some circuit tricks, Nehalem now has significantly lower latency unaligned cache accesses and thus we see a huge improvement in the CBALLS2 score here. The CBALLS2 workload is the only one within our SPECapc 3dsmax test that really stresses the unaligned cache access penalty of the current Core architecture, but there's a pretty strong performance improvement across the board in 3dsmax.
Nehalem is just over 40% faster than Penryn, clock for clock, in 3dsmax.
Cinebench R10
A benchmarking favorite, Cinebench R10 is designed to give us an indication of performance in the Cinema 4D rendering application.
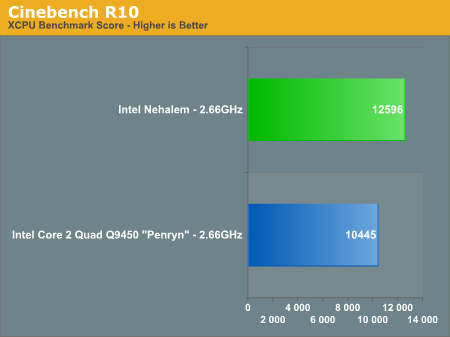
Cinebench also shows healthy gains with Nehalem, performance went up 20% clock for clock over Penryn.
We also ran the single-threaded Cinebench test to see how performance improved on an individual core basis vs. Penryn (Updated: The original single-threaded Penryn Cinebench numbers were incorrect, we've included the correct ones):
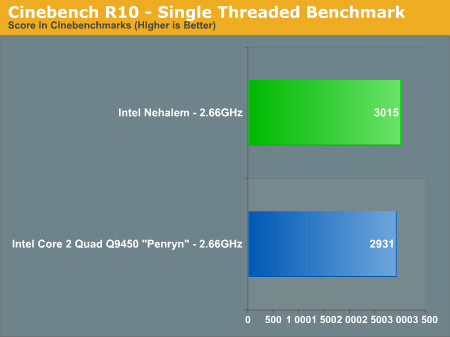
Cinebench shows us only a 2% increase in core-to-core performance from Penryn to Nehalem at the same clock speed. For applications that don't go out to main memory much and can stay confined to a single core, Nehalem behaves very much like Penryn. Remember that outside of the memory architecture and HT tweaks to the core, Nehalem's list of improvements are very specific (e.g. faster unaligned cache accesses).
The single thread to multiple thread scaling of Penryn vs. Nehalem is also interesting:
| Cinebench R10 | 1 Thread | N-Threads | Speedup |
| Nehalem (2.66GHz) | 3015 | 12596 | 4.18x |
| Core 2 Quad Q9450 - Penryn - (2.66GHz) | 2931 | 10445 | 3.56x |
The speedup confirms what you'd expect in such a well threaded FP test like Cinebench, Nehalem manages to scale better thanks to Hyper Threading. If Nehalem had the same 3.56x scaling factor that we saw with Penryn it would score a 10733, virtually inline with Penryn. It's Hyper Threading that puts Nehalem over the edge and accounts for the rest of the gain here.
While many 3D rendering and video encoding tests can take at least some advantage of more threads, what about applications that don't? One aspect of Nehalem's performance we're really not stressing much here is its IMC performance since most of these benchmarks ended up being more compute intensive. Where HT doesn't give it the edge, we can expect some pretty reasonable gains from Nehalem's IMC alone. The Nehalem we tested here is crippled in that respect thanks to a premature motherboard, but gains on the order of 20% in single or lightly threaded applications is a good expectation to have.
POV-Ray 3.7 Beta 24
POV-Ray is a popular raytracer, also available with a built in benchmark. We used the 3.7 beta which has SMP support and ran the built in multithreaded benchmark.
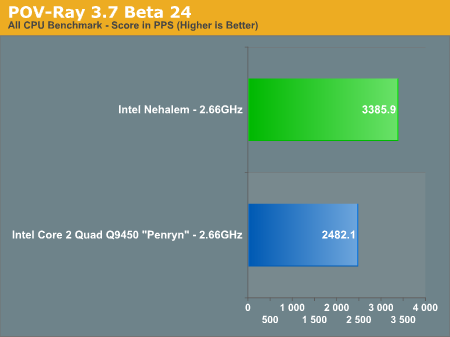
Finally POV-Ray echoes what we've seen elsewhere, with a 36% performance improvement over the 2.66GHz Core 2 Q9450. Note that Nehalem continues to be faster than even the fastest Penryns available today, despite the lower clock speed of this early sample.








108 Comments
View All Comments
Jedi2155 - Saturday, June 7, 2008 - link
Indeed, once the OEM's start demanding DDR3 for their system's due to Nehalem, we start seeing prices drop due economies of scale playing a greater part.RedFoxOne - Thursday, June 5, 2008 - link
I am still waiting for Intel and Google to merge so with their combined powers they can take over the world!JT
http://www.Ultimate-Anonymity.com">http://www.Ultimate-Anonymity.com
0g1 - Thursday, June 5, 2008 - link
Dude, wtf ... "Intel managed to change the cache structure and introduce an integrated memory controller while making both significantly faster than what AMD managed despite a four-year headstart."Thats bs. True, they are significantly faster, but you're comparing something that comes out in 6 months to something thats been out for like 1 year. And when it does come out (in 6 months) Shangai should be close by. Die shrink, cache increase, Hyper Transport clockspeed increase, lower latencies, and DDR3. Your comparison was simply unfair and untrue (considering AMD's upcoming cache and memory structure looks to be faster).
SiliconDoc - Monday, July 28, 2008 - link
Well, in this, one always likes the top dog better - they supply the goodies so much more often (even by unendorsed leaked channels which is GREAT if you ask me), and in turn the monetary stream from the resultant forces, whatever they may be.Add in the hype, and someone always has a favorite, so there ya go.
However, I find at least myself disappointed, since I don't have a grand every month to blow on new parts.
I am over and over again just not impressed, single core HT still has a really good hold on everything ( the D805 is crisys friendly for sure), and the latest videocard wars have hammered through so many tiny jumps - over such a long period and massive price restructuring... I'm sure glad I've waited.. I keep setting up the purchase then some new chip hits... the timing is very difficult the last 8 months.
This one appears to be another so what...again.
If you keep adding 5% to 15% to wowzie 25%, three or four or five times in a row, you finally get to something that isn't disappointing.
IMO they keep dribbling it out to us - maybe that's all they can do(OK I just LIED trying to be nice tothem), but they certainly spend an inordinate amount of time making 10 or 20 different "flavors" of all the chips, then they lock multipliers and disable catches...
I agree with the guy who said maybe he'll get an E8400 when they're 50 bucks. I'm not running a University server / research cruncher / consulting firm system.
Anyway good luck to AMD. Their Dx4/100 sample was exciting, as was their K6, good on their Thunderbird and Barton, no problem.
They do it too now though, "unlock" their chips for $$$$.
So, the whole system holds back FAST, and lays down SLOW to "saturate price point markets" and get everyone blowing their $$$ for some peice of hacked down crud. That's the way it IS.
HexiumVII - Thursday, June 5, 2008 - link
While AMD might not have a competitor anytime soon, lucky for us, Nvidia decided to go all ape bananas on Intel. General processors are really at a plateau for consumers. We really don't need 8 cores. What we do need is focused cores for Video and 3D. We are still pretty far from some really nice multimedia acceleration to finally kill our clunky mouse interface.0g1 - Friday, June 6, 2008 - link
We need all the cores we can get in CPU's. In the future, games are going to be multithreaded to the point of hundreds of threads.Focused cores for 3D should be a separate entity from the CPU die for maximum speed because:
1. Main memory speed is too slow compared to graphics memory.
2. 3D can be separated with little to no penalty, thus allowing you to get theoretically twice the speed via two processors (one for 3d and one for general computation).
mkruer - Thursday, June 5, 2008 - link
Compare the blue and yellow graph to Anand's two graphs. According to these benchmarks, "old" Penryn beats "new" Penryn by about 38% in single-threaded Cinebench and 17% in multi-threaded Cinebench.http://images.anandtech.com/graphs/nehalempreview_...">http://images.anandtech.com/graphs/nehalempreview_...
http://images.anandtech.com/graphs/nehalempreview_...">http://images.anandtech.com/graphs/nehalempreview_...
http://images.anandtech.com/graphs/amd%20phenom%20...">http://images.anandtech.com/graphs/amd%20phenom%20...
http://www.anandtech.com/printarticle.aspx?i=3153">http://www.anandtech.com/printarticle.aspx?i=3153
A mature Penryn system should score closer to the 3000 mark then what Anand listed.
You can look at other review sites as well
http://www.hardwarezone.com.my/articles/view.php?i...">http://www.hardwarezone.com.my/articles/view.php?i...
http://www.overclockersclub.com/reviews/intel_q945...">http://www.overclockersclub.com/reviews/intel_q945...
This should be raising some red flags people
Anand Lal Shimpi - Thursday, June 5, 2008 - link
That's a very good question, the Penryn system we ran the new numbers on is obviously different from the older systems but I'm trying to figure out now if there is a software explanation for why Cinebench is a lot slower now.The POV-Ray scores line up with what they were in our previous reviews, the only thing I can think of off the top of my head is that we've since switched to Vista SP1 and that has caused some problems where performance has gone down (see the 3dsmax scores).
I'm digging on the Cinebench question right now and will post back as soon as I have some more data.
-A
Anand Lal Shimpi - Thursday, June 5, 2008 - link
Just a quick check of the multithreaded numbers shows that the old and new Penryn numbers are where they should be, within 2%, so that's not an issue.Re-running the single threaded stuff now to see where we're at. Neither of the sites you pointed at used Vista SP1 either (including our older Phenom results), I may to run a quick install of Vista without SP1 to figure this one out.
I'll keep you posted.
-A
Anand Lal Shimpi - Thursday, June 5, 2008 - link
Fixed.That was entirely an error on my part, it wasn't a SP1 or a configuration issue. It was an Excel spreadsheet malfunction :) I used data from the wrong column (first run data vs. average run data) for Cinebench. Everything else looks to be exactly where it should be but I'll make another run through the spreadsheet to make sure.
I just reran the numbers to confirm and now things make much more sense. Not only are our XCPU scores virtually identical to what they were for the Phenom article, but the single threaded tests make a lot more sense. Furthermore, the scaling from 1 to n-threads makes a lot more sense now too. Penryn gets a 3.56x speedup from multithreading while Nehalem gets a 4.18x speedup - the difference in scaling partially being due to HT.
Thanks for bringing this to my attention and sorry for the mixup.
Take care,
Anand