Intel Core 2 Extreme QX9650 - Penryn Ticks Ahead
by Anand Lal Shimpi on October 29, 2007 12:13 AM EST- Posted in
- CPUs
We've never seen Intel with such a strong roadmap before, the company is truly firing on all cylinders and executing with amazing precision. Server, mobile, desktop and even new areas like ultra mobility and graphics all have absolutely wonderful roadmaps to look forward to. The biggest complaint we've had about Intel these days is that they kind of botched the X38 launch. Think back to a couple of years ago, what was our chief complaint then? Probably leaving us with power hungry, under performing processors for about 5 years. Today we're looking at a damn good Intel.
Recap: What's a Penryn?
Core, it's the architecture that shook an industry and today Intel is officially doing its first update to it. Prior to Intel's Core architecture, there wasn't much to get excited about when it came to Intel on the desktop.
At the same time, with Penryn Intel is very much the victim of its own success. How do you follow up such a tremendous splash with anything but equal greatness? AMD is close but still has yet to produce a response to Core 2, much less Penryn, and thus Intel's biggest competition today is itself.
In January 2007 Intel first showed off its 45nm High K + metal gate transistors, a dramatic departure from Intel's current 65nm transistors not only in size/switching speed but actual composition. If you remember back to the days of the original P6 processors, with a smaller transistor we saw tremendous improvements in die size, power consumption and performance. These days, such dramatic improvements are much harder to come by given that we're already dealing with such small transistor feature sizes. Gone are the days of the free lunch with each die shrink.
We've gone over the technical details of Intel's high-K + metal gate enhancements, but the end result is that at the same clock speed you can expect dramatic reductions in power. Alternatively, at the same power levels, you can achieve much higher switching rates and thus higher clock speeds.

The core architecture of Penryn remains unchanged from Conroe; with the smaller transistors Intel's able to fit in a few new features and more cache on the chip while still maintaining a smaller die size. Where each dual-core Conroe die measured 143 mm^2, Penryn is merely 107 mm^2 despite having 50% more cache (6MB vs. 4MB). Obviously the quad core chips double overall area but you get the point.
Intel also uses a lot more of these new 45nm transistors than before; while a dual-core Conroe was made up of 291 million transistors, the comparable Penryn weighs in at 410 million (582M vs. 820M for quad-core variants). You're getting 40% more transistors and 50% more cache in a 25% smaller package; the latter is obviously most important to Intel as it helps reduce costs and drive profits up. So while it may seem generous, the move is purely self motivated on Intel's part.
The larger cache is a bit different than what we've seen in Conroe. While Conroe's cache is a 4MB 16-way set-associative L2, the 6MB Penryn cache is 24-way set-associative, designed to improve hit rates and keep latency manageable in an already large cache. Intel hasn't revealed whether Penryn's prefetchers have been adjusted to help populate its larger cache any better. As we saw in our original Penryn preview, Penryn's cache performance remains unchanged; latencies in our final stepping are identical to Conroe.
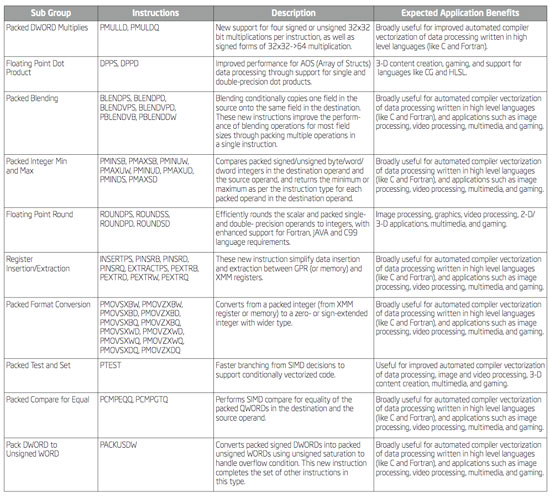
The cache enhancements are by far the biggest consumer of those extra transistors in Penryn, but believe it or not, they aren't responsible for the biggest performance boost. Intel has been fairly steady in adding new instructions to the x86 ISA and Penryn continues the trend with the addition of SSE4. Penryn gets 47 new instructions that make up the first implementation of SSE4; more will come with Nehalem at the end of 2008. We'll talk about SSE4 performance later on in this article, but here are the instructions you get with Penryn:
Penryn also implements a new divider that impacts both integer and floating point divides using a radix-16 algorithm. The algorithm computes more bits of the result of a divide each pass (four bits per iteration vs. two bits in Conroe), decreasing divide latency.
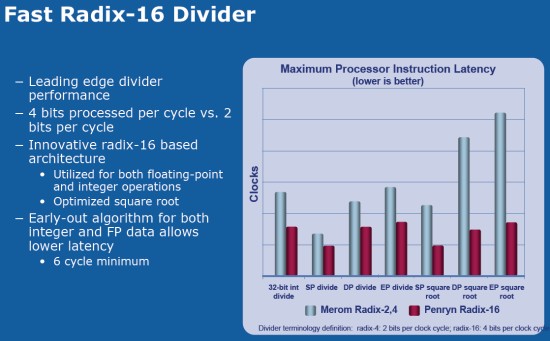
The faster divider is a very specific enhancement that should manifest itself as a performance boost in 3D and imaging applications.

Penryn's Super Shuffle Engine should also improve SSE2, SSE3 and SSE4 applications that use a lot of shuffle operations. Cache performance is also improved slightly for misaligned stores, which should improve performance, once again, in 3D and imaging applications. Finally, there are some power enhancements made to Penryn, but these are mobile-specific and thus don't apply to any of the desktop variants.








16 Comments
View All Comments
Canadian87 - Monday, October 29, 2007 - link
I'd like to point out that someone must have been tired when writing this. The graphs here on page 4 say "QX6950" VS "QX6850", simple reversal of the numbers, but I'd like to correct it for those that might be confused, took me a moment to figure out which was which myself the "QX6950" is ment to be the "QX9650", and obviously the "QX6850" is the correct naming.GL HF.
GlassHouse69 - Monday, October 29, 2007 - link
ew.intel again ftw. blech. They made a great chip. power usage is fantastic. One could get even lower total wattages (by far) if they concentrated on doing so. a quad core that can be cooled near silently. neat :)
sprockkets - Monday, October 29, 2007 - link
Just a question, what was the difference from Core to Core 2? All I could ever fine was cache size was increased.Now that I'm thinking about it, why not the name Quadro? Oh, nVidia ownz it.
defter - Monday, October 29, 2007 - link
Core Duo (Yonah) was based on Pentium M.Core2 (Conroe) is a new architecture.
sprockkets - Monday, October 29, 2007 - link
actually i found a comparison page about it, and core 2 isn't that much different from core. Yes, it updated a lot and gave improved performance. No, it is not a completely new architecture from PM, but you can say a big difference from the P4.http://www.anandtech.com/showdoc.aspx?i=2808&p...">http://www.anandtech.com/showdoc.aspx?i=2808&p...
sprockkets - Monday, October 29, 2007 - link
On page 9 I believe you are grabbing some old benchmarks, old in the sense of your previous articles. I believe I pointed this out to you as a mistake, and now it is here in the bar graph. Again, how is it that the 2.33ghz C2D outperforms the 3ghz one?