CeBIT 2007: Storage & Servers
by Johan De Gelas on March 29, 2007 12:15 AM EST- Posted in
- Trade Shows
AMD
Despite the enthusiastic and hard working marketing people, AMD's presence at CeBIT was somewhat a disappointment. Other than some vague benchmarks, there was no demo system of AMD's "Native quad core", and no real hard benchmarks or clock speeds. With a bit of help from a few enlightened people, however, we were able to dig up some new info.

It was quite interesting to hear AMD's representatives use the term "K10" again. The most famous benchmark so far is AMD's claim that the K10 is about 42% faster in floating point than the current top chip, the Xeon x5355.
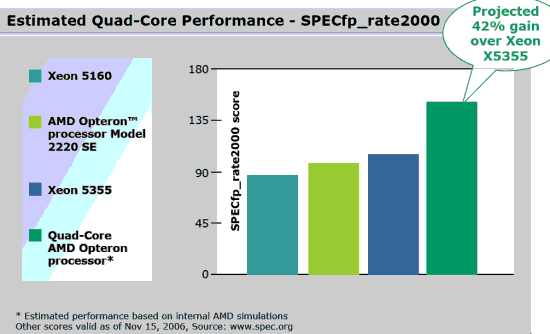
So we decided to delve a little deeper. Let us first look at the dual socket systems, as we try to find more precise SPEC (base) numbers:
First of all, it should be noted that Spec FP2000 rate and Spec FP2006 rate are already running better on the dual core Opteron than on the dual core Xeon "Woodcrest". SpecFP rate is nothing more than several SpecFP benchmarks running completely separate from each other, and it is well known that SpecFP is a bandwidth intensive benchmark. So running several of those benchmarks will only increase the bandwidth needed. In a two socket machine, the Opterons have roughly twice as much bandwidth as with one socket, so SpecFP rate is basically the ideal benchmark to show the benefits of AMD's NUMA platform.
If we compare a dual quad core Xeon (x5355) with a quad socket dual core Opteron, the bandwidth of the AMD platform doubles while the bandwidth of the Intel system stays the same. As we use eight cores in total instead of four, the bandwidth demands of the SpecFP benchmark also double.
The result is that the dual Xeon x5355 (eight cores) is heavily bottlenecked by a lack of bandwidth and hardly faster than the dual Opteron 2220SE (four cores) in CPU FP2000 rates. If we take a look at the best dual core Xeon 5150 (2.66 GHz) score, it gets a score of 78.2. That means that the quad Xeon 2.66 GHz is only about 32% faster than its dual core brother at the same clock speed, another clear indication that the dual Xeon x5355 scores are seriously limited by memory bandwidth. It is no surprise that the quad socket Opteron 8220 is about 34% faster than the Xeon x5355 (and we are ignoring the probably inflated result of 184 you can get with the Sun Studio Compiler).
This puts AMD's claim that the best "K10" (most likely at 2.3 GHz) will be 42% faster than the Xeon x5355 in Spec FP rate in the right perspective. We reported in our Barcelona architecture article that the AMD K10's Northbridge is set up to handle higher bandwidth than the current AMD chips. As has been shown numerous times, the current Athlon 64 X2/Opteron architecture is not able to use the extra bandwidth that DDR2 gives.
So most of the 42% advantage is probably due to K10's better Northbridge and better use of DDR2. Ron Myers of AMD claimed that the difference is now already greater than 42%. Combine this with the fact that the K10 is running at only 2.3 GHz, and we can conclude that the memory subsystem (Load/store unit, L1, L2, Northbridge) of the K10 is simply (vastly) superior compared to the Athlon 64s and to the quad Xeon. This confirms our and Intel's assumption that the K10 will probably make the largest impact as a very potent HPC chip. The hardware virtualization features in AMD's K10 are quite impressive, but we'll discuss them later.
There is more: AMD emphasizes the memory subsystem and SSE on the slide below, presenting the Intel Clovertown as a severely bottlenecked CPU.
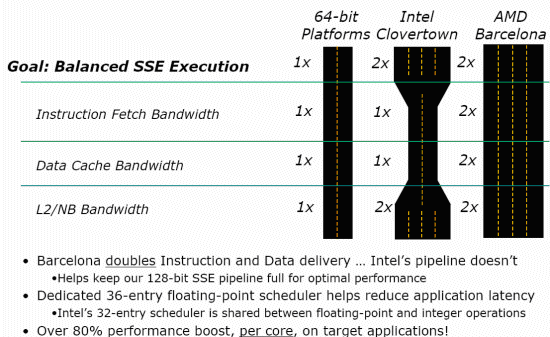
So how much of this marketing slide is true? It is very likely that the instruction fetch bandwidth of the AMD K10 is probably twice as high as Intel's Core architecture. Pre-decoding bandwidth (and thus the complete chain of fetching and decoding) on Core is still limited to 16 bytes of code per clock cycle, while it is claimed to be 32 bytes for the whole pre-decoding, fetching and decoding pipeline for AMD's K10. It should be remarked however that only in very CPU intensive code will the 16 byte per cycle bandwidth really be a bottleneck.
However, stating that the data cache bandwidth is twice as high as Intel's Core is ignoring a few things. Eric Bron, probably one of the most knowledgeable developers when it comes to SSE, stated: "Intel Core can sustain one 128-bit load and one 128-bit store per cycle (I've measured actual timings very near this theoretical peak), so Core can copy 128 bits per cycle. Barcelona (K10) can only copy 64 bits per cycle from the above store bandwidth limitation." So the twice as much "load bandwidth" is only a small part of the story:
A very enthusiastic Ron Myers emphasized that the AMD "Barcelona" launch is just as important as the Opteron launch back in 2003. And frankly, we believe him. The fast interconnects on die and "native quad core" might not make a big difference in typical desktop applications, but it does make a difference in server applications. The improved fetching and decoding pipeline and the much improved OoO (Out of Order) execution should offer better integer performance. At the same time, it's starting to be clear that it is more likely that AMD's K10 will outperform by a tangible margin the current Xeon "Clovertown" in HPC applications than server applications, thanks to vastly improved SSE loading and execution, together with a much better memory system. Again, that is probably the reason why Intel is introducing a 1600 MHz DIB more quickly than planned.
Despite the enthusiastic and hard working marketing people, AMD's presence at CeBIT was somewhat a disappointment. Other than some vague benchmarks, there was no demo system of AMD's "Native quad core", and no real hard benchmarks or clock speeds. With a bit of help from a few enlightened people, however, we were able to dig up some new info.
It was quite interesting to hear AMD's representatives use the term "K10" again. The most famous benchmark so far is AMD's claim that the K10 is about 42% faster in floating point than the current top chip, the Xeon x5355.
So we decided to delve a little deeper. Let us first look at the dual socket systems, as we try to find more precise SPEC (base) numbers:
| AMD vs. Intel Quad Core Performance Overview | |||
| Base SPEC | Xeon 5160 (3 GHz) | Opteron 2220 (2.8 GHz) | Xeon vs. Opteron |
| CPU Int2006 | 17.5 | 12.2 | 43% |
| CPU Fp2006 | 17.1 | 13.1 | 31% |
| CPU Int2006 (rate) | 53.2 | 46.1 | 15% |
| CPU Fp2006 (rates) | 44.1 | 45.6 | -3% |
| CPU Fp2000 (rates) | 81.6 | 85.4 | -4% |
First of all, it should be noted that Spec FP2000 rate and Spec FP2006 rate are already running better on the dual core Opteron than on the dual core Xeon "Woodcrest". SpecFP rate is nothing more than several SpecFP benchmarks running completely separate from each other, and it is well known that SpecFP is a bandwidth intensive benchmark. So running several of those benchmarks will only increase the bandwidth needed. In a two socket machine, the Opterons have roughly twice as much bandwidth as with one socket, so SpecFP rate is basically the ideal benchmark to show the benefits of AMD's NUMA platform.
If we compare a dual quad core Xeon (x5355) with a quad socket dual core Opteron, the bandwidth of the AMD platform doubles while the bandwidth of the Intel system stays the same. As we use eight cores in total instead of four, the bandwidth demands of the SpecFP benchmark also double.
| AMD vs. Intel Octal Core Performance Overview | ||||
| Xeon x5355 (2.66 GHz) | Opteron 8220 (2.8 GHz) | Xeon vs. Opteron | K10 | |
| CPU Int2006 | 16 | 10.5 | 52% | N/a |
| CPU Fp2006 | 16.1 | 12.1 | 33% | N/a |
| CPU Int2006 (rate) | 79.6 | 86.2 | -8% | N/a |
| CPU Fp2006 (rates) | 58.9 | 82.5 | -29% | N/a |
| CPU Fp2000 (rates) | 103 | 157 | -34% | +/- 146 |
The result is that the dual Xeon x5355 (eight cores) is heavily bottlenecked by a lack of bandwidth and hardly faster than the dual Opteron 2220SE (four cores) in CPU FP2000 rates. If we take a look at the best dual core Xeon 5150 (2.66 GHz) score, it gets a score of 78.2. That means that the quad Xeon 2.66 GHz is only about 32% faster than its dual core brother at the same clock speed, another clear indication that the dual Xeon x5355 scores are seriously limited by memory bandwidth. It is no surprise that the quad socket Opteron 8220 is about 34% faster than the Xeon x5355 (and we are ignoring the probably inflated result of 184 you can get with the Sun Studio Compiler).
This puts AMD's claim that the best "K10" (most likely at 2.3 GHz) will be 42% faster than the Xeon x5355 in Spec FP rate in the right perspective. We reported in our Barcelona architecture article that the AMD K10's Northbridge is set up to handle higher bandwidth than the current AMD chips. As has been shown numerous times, the current Athlon 64 X2/Opteron architecture is not able to use the extra bandwidth that DDR2 gives.
So most of the 42% advantage is probably due to K10's better Northbridge and better use of DDR2. Ron Myers of AMD claimed that the difference is now already greater than 42%. Combine this with the fact that the K10 is running at only 2.3 GHz, and we can conclude that the memory subsystem (Load/store unit, L1, L2, Northbridge) of the K10 is simply (vastly) superior compared to the Athlon 64s and to the quad Xeon. This confirms our and Intel's assumption that the K10 will probably make the largest impact as a very potent HPC chip. The hardware virtualization features in AMD's K10 are quite impressive, but we'll discuss them later.
There is more: AMD emphasizes the memory subsystem and SSE on the slide below, presenting the Intel Clovertown as a severely bottlenecked CPU.
So how much of this marketing slide is true? It is very likely that the instruction fetch bandwidth of the AMD K10 is probably twice as high as Intel's Core architecture. Pre-decoding bandwidth (and thus the complete chain of fetching and decoding) on Core is still limited to 16 bytes of code per clock cycle, while it is claimed to be 32 bytes for the whole pre-decoding, fetching and decoding pipeline for AMD's K10. It should be remarked however that only in very CPU intensive code will the 16 byte per cycle bandwidth really be a bottleneck.
However, stating that the data cache bandwidth is twice as high as Intel's Core is ignoring a few things. Eric Bron, probably one of the most knowledgeable developers when it comes to SSE, stated: "Intel Core can sustain one 128-bit load and one 128-bit store per cycle (I've measured actual timings very near this theoretical peak), so Core can copy 128 bits per cycle. Barcelona (K10) can only copy 64 bits per cycle from the above store bandwidth limitation." So the twice as much "load bandwidth" is only a small part of the story:
- Intel Core can do a 128-bit Load and 128-bit Store in one cycle if possible
- AMD's K10 can either do two 128-bit loads, or two 64-bit stores, or one 128-bit Load and one 64-bit Store
A very enthusiastic Ron Myers emphasized that the AMD "Barcelona" launch is just as important as the Opteron launch back in 2003. And frankly, we believe him. The fast interconnects on die and "native quad core" might not make a big difference in typical desktop applications, but it does make a difference in server applications. The improved fetching and decoding pipeline and the much improved OoO (Out of Order) execution should offer better integer performance. At the same time, it's starting to be clear that it is more likely that AMD's K10 will outperform by a tangible margin the current Xeon "Clovertown" in HPC applications than server applications, thanks to vastly improved SSE loading and execution, together with a much better memory system. Again, that is probably the reason why Intel is introducing a 1600 MHz DIB more quickly than planned.








13 Comments
View All Comments
Nehemoth - Thursday, March 29, 2007 - link
Well it was invented by AMD but was the code name for the Turion.Later indeed miss used over Internet....
Hope Barcelona be an Amazing chip, regards to AMD for the great products that Intel is Gave in us, yes sound really extrange but imagine where we would be if not for AMD..
CrystalBay - Thursday, March 29, 2007 - link
Fascinating analysis Johann ..JohanAnandtech - Thursday, March 29, 2007 - link
Thanks!With the current hints we got from Intel (Penryn Xeons might go to 3.6 GHz if necessary), I just hope AMD will do better than 2.3 GHz. Journalists like us need Epic battles ;-)