NVIDIA's GeForce 8800 (G80): GPUs Re-architected for DirectX 10
by Anand Lal Shimpi & Derek Wilson on November 8, 2006 6:01 PM EST- Posted in
- GPUs
Digging deeper into the shader core
Many of the same patterns that lead designers of current hardware to their conclusions are still true today. For instance, pixels next to each other on the screen still tend to follow a very similar path through the hardware. This means that it still makes sense to process pixels in quads. As for changes, as hardware becomes more programmable, we are seeing a higher percentage of scalar data being used. In spite of the fact that much of the work done by graphics hardware is vector based, it becomes easier to schedule code if we are working with a bunch of parallel, independent, scalar processors. It is also more efficient to build separate units for texture addressing and filtering, and ATI has done this for quite some time now.
NVIDIA has finally decoupled the texture units from their shader hardware, enabling math and texturing to happen at the same time with no scheduling issues. They have also decided to implement their math hardware as a collection of scalar processors that can be used together to perform vector operations. NVIDIA calls the scalar processors Stream Processors (SPs), and they handle all the math performed in the shader core of G80.
It isn't surprising to see that NVIDIA's implementation of a unified shader is based on taking a pixel shader quad pipeline, and breaking up the vector units into 4 scalar units. Now, rather than 4 pixel quads, we see 16 SPs per "quad" or block of stream processors. Each block of 16 SPs shares 4 texture address units, 8 texture filter units, and an L1 cache.
G70 Pixel Shader Quad
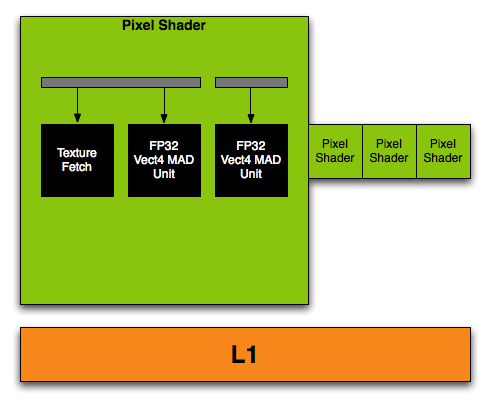
G80 Stream Processor Block
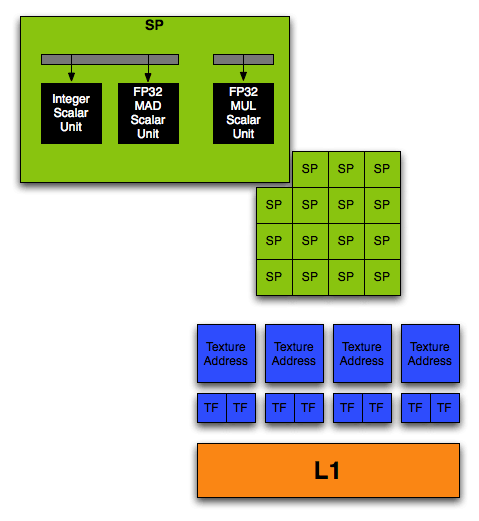
The fact that these SPs are now independent and scalar gives NVIDIA the ability to keep more of them busy more of the time. This is very important as programmers start to write longer more complex shaders. Even while working with vectors, programmers need to use scalar values all the time to manipulate and evaluate data.
Each Stream Processor is able to complete one MAD and one MUL per clock cycle. While this is based on maximum throughput, we can reasonably expect to achieve this even though the hardware is pipelined. In spite of the 4 or 5 cycles (depending on precision) latency of a MUL in Conroe, SSE is now capable of one MUL per cycle throughput (as long as there are no stalls in the pipeline). Latency of operations in G80 could be even longer and sustain high throughput, as most of the time we are working with code that isn't riddled with dependencies.
The fact that each SP is capable of IEEE 754 single precision and can sustain high throughput for MAD and MUL operations while running any type of shader code makes this hardware very powerful and more general purpose than ever.
As a thread exits the SP, G80 is capable of writing the output of the shader to memory. The fact that SPs can do this at any time (except after pixel shaders) goes beyond the DX10 spec of just allowing for stream output after the Geometry Shader. On previous hardware, data would have to go through every stage of the pipeline until a value was finally written out to the frame buffer. Now, we can write data out at the end of anything but a pixel shader (as pixel shaders must send their output straight over to the ROPs for processing). This will be a great benefit to GPGPU (general purpose computing on graphics processing units).








111 Comments
View All Comments
DerekWilson - Wednesday, November 8, 2006 - link
No DX10 for winxp -- but you've got OGL with extensions.We will certainly take a look at DX10 performance once we have DX10 apps.
Have fun glimpsing :-)