Smarter Prefetching and Caching
Making sure that the right instructions and data are ready for use in the caches in the "3 GHz and beyond" era is one of the most important tasks of the architectural engineer. This helps to ensure performance increases as clockspeeds get pushed higher; otherwise, higher CPU clockspeeds will simply result in the processor spending more time waiting for data. This technique of priming the caches is knows as Prefetching; however, the current hardware prefetching algorithms don't always lead to success. There are quite a few cases where they can actually lower performance, especially in bandwidth sensitive applications.The Core architecture prefetching is without any doubt superior to what can be found in the Athlon 64 and Pentium 4. There are no less than three prefetchers - two data, one instruction - in each core, plus two prefetchers for the L2-cache. With eight prefetchers active in one dual-core Core CPU, all those prefetchers could easily get in the way of the "demand" bandwidth - the bandwidth which is needed by the load operations of the running program. In order to avoid this bottleneck, the prefetch monitor of the Core CPUs always give priority to the demand bandwidth; the prefetchers will never steal too much bandwidth away from the running program.
There is more. The data prefetch needs to perform tag lookups (tags = index of cache) in the caches frequently. To avoid this resulting in higher latency for the "normal" (caused by the program running) tag lookups, the data prefetch uses the store port for the tag lookup. If you remember, loads happen about twice as often as stores. This means the store port is used only half as much as the load port and it make sense to use that port for tag lookup by the prefetchers. Note also that stores are not critical for system performance in most cases -- once the data is "written" the processor can go on about its business. The cache/memory subsystem is in charge of replicating the data down to main memory, and as long as this happens eventually, everything works fine.
The cache system of the Core CPU is also very impressive. A massive 4 MB L2-cache is shared between the two cores and is accessed in only 12 to 14 cycles. Each core also has a 3 cycle 32 KB Instruction cache and a 32 KB data cache at its disposal. Note that the "Trace Cache" of NetBurst has been left behind with the return to shorter pipelines; the NetBurst Trace Cache basically functions as an instruction cache for pre-decoded instructions, and while this was apparently helpful for the long pipeline of NetBurst, Intel has apparently determined that a traditional L1 caching scheme makes more sense for Core.
Cache Architecture Overview
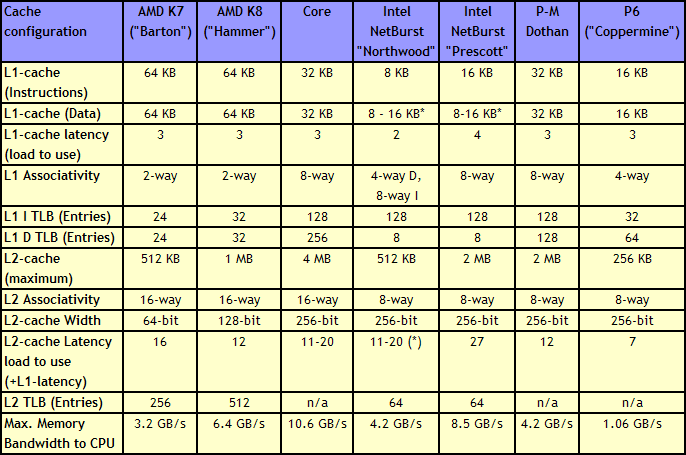 |
| Click to enlarge |
Just a quick look at the numbers in the above table make it clear that the memory subsystem of the Core architecture is impressive. It has twice as much L2 cache as current dual-core CPUs (the same amount as Presler), but the cache is still accessible with low latency. The shared L2 cache also allows one core to use more than 2MB of cache if necessary. Both L1 and L2 cache are accessed via a 256-bit wide bus, allowing the caches to deliver massive bandwidth to the core.
Core versus Hammer: Memory subsystem
Core's most important competitor, the Hammer ("K8") architecture, has two small but noteworthy advantages. The first is its bigger 2 x 64 KB L1 cache. This is only a small advantage as an 8-way 32 KB cache will have a hit rate close to that of a 2-way 64 KB cache.The second and more important advantage is the on die memory controller, which lowers the latency to the memory considerably. However, the lower clockspeeds of the Core CPUs (relative to NetBurst) and the faster FSB also lower latency significantly. With the numbers available to us now, we have reason to believe that the Athlon 64 X2's latency advantage will shrink to only 15 to 20%. For comparison, the memory subsystem of the Pentium 4 was almost twice as slow as the Athlon 64 (80-90 ns versus 45-50 ns).
However, those two small advantages are likely negated by all the other memory subsystem metrics. The Core CPUs have much bigger caches and much smarter prefetching than the competition. The Core architecture's L1 cache delivers about twice as much bandwidth (Measured by ScienceMark), while it's L2-cache is about 2.5 times faster than the Athlon 64/Opteron one.








87 Comments
View All Comments
Missing Ghost - Monday, May 1, 2006 - link
hum, no. There is a 1.4gHz P6, you forgot Tualatin.JarredWalton - Monday, May 1, 2006 - link
1.26 was Tualatin as well, but that's beside the point. Basically, clock speed at launch vs. final clock speed of the architecture was a disappointment for Intel. They were hoping for 6+ GHz at launch, and even thinking 10 GHz might be possible.KayKay - Monday, May 1, 2006 - link
Someone should hire you to write textbooks because this was explained extremely well and in simple terms. Good JobJohanAnandtech - Monday, May 1, 2006 - link
Thanks! :-)Very happy to read that.
BitByBit - Monday, May 1, 2006 - link
Fantastic article.In retrospect, it is easy to conclude that this is the route Intel should have chosen for P6's retirement.
Core looks to be a very strong, all-round performer, unlike Netburst.
We can only hope that AMD has an answer in the works, as K8 will have a hard time competing with this monster.
It is unreasonable in my mind to expect a 4-5(?) year-old architecture to be able to compete with Intel's latest. AMD with K8 has had a long reign as the performance king, but is now facing something entirely different. Perhaps K8L will be able to offer serious competition.
It will, however, take more than a doubling of the FP units (if rumour is correct) to achieve this. The cumulative effect of Conroe's architectural features (memory disambiguation, macro-ops fusion etc...) mean that Core's efficiency has far exceeded K8's, not to mention the impact of its vastly superior cache system - its 8-way 32kb * 2 L1 should in theory exceed the hitrate of K8's 2-way 64kb * 2 L1.
It may not be until K10 is released that AMD takes back the performance crown.
Larso - Monday, May 1, 2006 - link
As the K8 is about 5 years old, and the current incarnations doesn't really include that many modifications, I wonder what AMD's engineers have been doing all these years. The K8 is not that different from the K7 even.Whats coming up? The AM2 version is basically the same beast with a new memory controller. The K8L, well since they didn't name it K9, I suppose its just small upgrades to the same design.
I really like to think AMD has something coming we don't know about. Or rather, they ought to have something coming... Any rumors?
Reynod - Monday, May 1, 2006 - link
I can't help but think (and pray) that Larso's comment has some validity here.Why would AMD sit back and do nothing for so long? Would they have not been tinkering with various prototypes over the last couple of years? Are we in for a surprise?? Anand, you and the review team touched on several improvements they could make, care to outline these in some detail in a future article? Someone needs to give AMD some free advice ... heh heh
Spoonbender - Monday, May 1, 2006 - link
Keep in mind that AMD doesn't have Intel's resources. Until recently, they still lost money every quarter. So they might not have been able to work on a successor to K8 until recently. (I remeber reading an interview with some AMD boss, saying that the K8 was literally a last-ditch effort to survive. If that failed, there wouldn't be an AMD, so they threw everything they had at it)So "Why would AMD sit back and do nothing for so long?" Because they had a good project, and didn't have the resources to make a new one?
Of course, it probably isn't that bad, just tossing out an alternative scenario. ;)
However, they have hinted that they were working on specific architectures for the notebook and server markets. (Unlike Intel who are moving back to a single unified architecture).
And despite its age, the K8 is still a pretty nice architecture, and it wouldn't be a huge undertaking to improve on it to get something quite a bit more efficient. Intel had to develop a new architecture because NetBurst just wouldn't cut it. AMD can probably afford to expand on K8 a bit longer, and even with K9/K10, I wouldn't expect a vastly different architecture.
Spoonbender - Monday, May 1, 2006 - link
"Because they had a good project" <- Was supposed to be product, not project... :)psychobriggsy - Monday, May 1, 2006 - link
AMD said recently that they have three times the engineers on their books as they did when they designed K8.However I suspect they're working on K10/KX, although maybe some of them worked on K8L.
Clearly it seems that some in-core work could translate into reasonable performance gains for the current K8 design. A 4-way L1 cache instead of 2-way for example, and a greater L2 to L1 bandwidth. Certainly a mechanism to reorder instructions so that loads can be performed earlier seems to be necessary. 2MB L2 per core could also help, and the 65nm die pictures that AMD showed recently did seem to show far denser cache. K8L is rumoured to include more FP resources, but I don't know about any of the other stuff - but AMD will be talking more about K8L (and beyond?) in June apparently.